Kafka基础教程:消息队列与点对点、发布订阅模式解析
需积分: 9 13 浏览量
更新于2024-07-08
收藏 3.16MB DOCX 举报
"Kafka课堂讲义"
Kafka是一种分布式流处理平台,由Apache软件基金会开发。本讲义主要探讨Kafka的基础操作,包括其作为消息队列的角色、工作原理以及在实际应用中的重要性。
一、Kafka简介
1. 消息队列
消息队列(MQ)在分布式系统中扮演着关键角色,它允许应用程序异步处理数据,从而提高系统性能和可伸缩性。消息Message是指在网络中两台计算机或设备间传递的数据形式。队列Queue遵循先进先出(FIFO)原则,允许在队头删除元素,在队尾添加元素。消息队列MQ结合了这两者,提供了生产和消费接口,用于存储和检索消息。
2. 消息队列的分类
- 点对点(P2P)模式:在这种模式下,生产者将消息发送到队列,消费者从队列中拉取消息并消费。一旦消息被消费,它将从队列中移除,确保每个消息仅被一个消费者处理,例如电子邮件系统。
- 发布/订阅(Pub/Sub)模式:在这种模式中,生产者(发布者)将消息发布到主题(Topic),多个消费者(订阅者)可以订阅并消费这些消息。每个消息可以被多个消费者接收,比如社交媒体平台。
二、Kafka的特点与使用场景
1. 解耦:Kafka允许系统通过消息进行通信,无需知道彼此的细节,增强了系统的灵活性和独立性。
2. 冗余与持久化:Kafka支持消息持久化,即使在处理前消息丢失,也能保证数据的完整性。
3. 扩展性:由于Kafka的消息处理是分布式的,各组件可以独立扩展,不影响整体系统的运行。
4. 峰值处理能力:在高流量时期,Kafka可以缓冲大量消息,使得业务系统按其处理能力逐步处理,避免系统崩溃。
5. 可恢复性:如果系统部分组件故障,Kafka的冗余机制保证了系统的稳定性和恢复性。
总结来说,Kafka作为一个高效、可扩展的消息中间件,适用于日志收集、流式数据处理、实时监控等多种场景。其设计目标是处理大规模实时数据,提供低延迟、高吞吐量的服务,并且通过消息队列的方式,有效地解决了分布式系统中的数据通信问题。
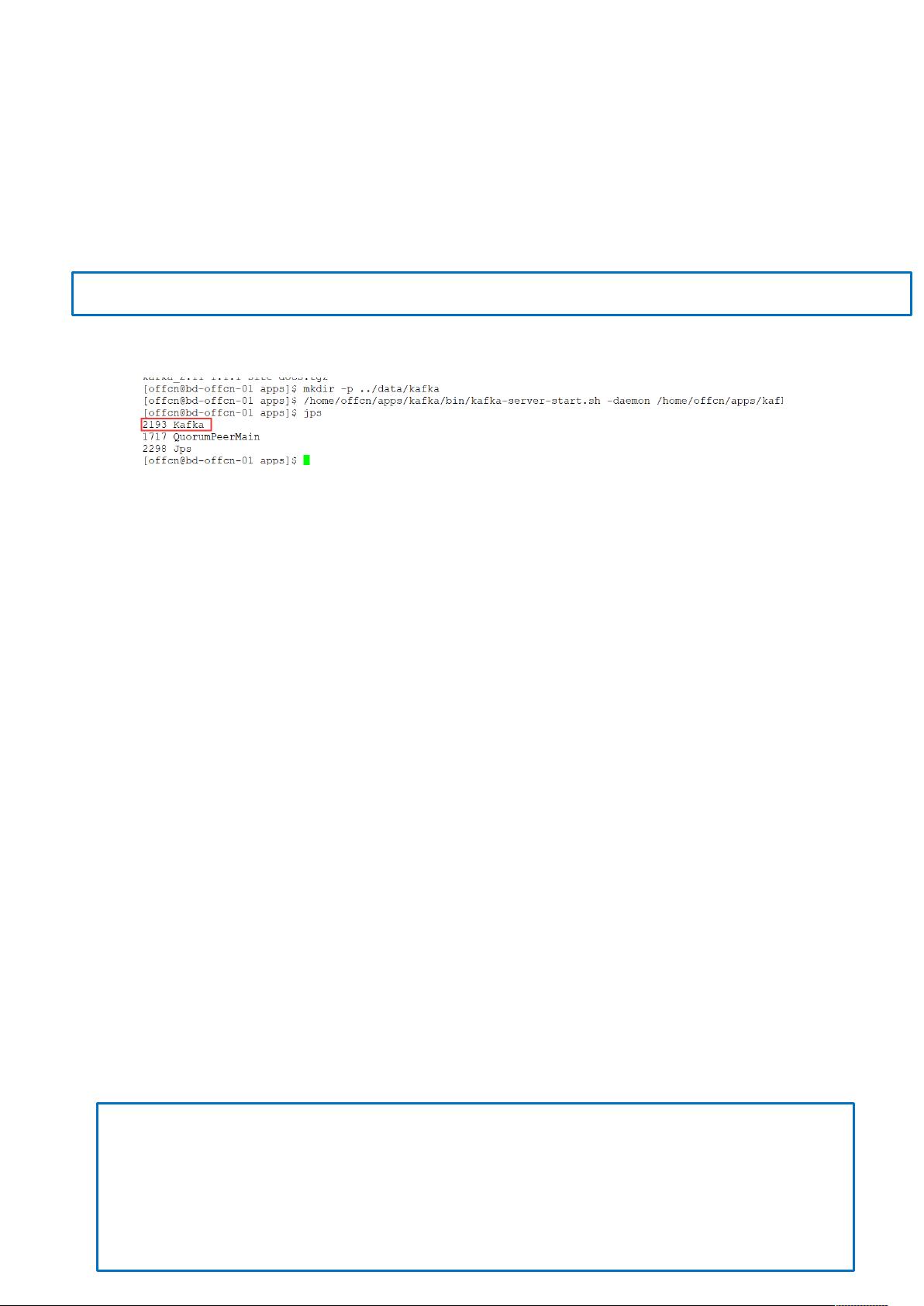
2、服务启动
服务启动5每台都要运行此命令
启动结果如下图 +> 所示:
图 +> 启动
三、Kafka 基本操作
(一)、Kafka 的 topic 操作
是 非常重要的核心概念,是用来存储各种类型的数据的,所以
最基本的就需要学会如何在 中创建、修改、删除的 ,以及如何向
生产消费数据。
关于 的操作脚本:+ 6
1、创建 topic
[root@node01 kafka]$ nohup bin/kafka-server-start.sh config/server.properties 2>&1
&
[root@node01 kafka]# bin/kafka-topics.sh --create \
--topic hadoop \ ## 指定要创建的 topic 的名称
--zookeeper node01:2181,node02:2181,node03:2181/kafka \
##指定 kafka 关联的 zk 地址
--partitions 3 \ ##指定该 topic 的分区个数
--replication-factor 3 ##指定副本因子


剩余63页未读,继续阅读
2022-01-21 上传
2023-07-28 上传
2023-03-16 上传
2023-10-08 上传
2023-07-13 上传
2023-09-20 上传
2023-06-28 上传
2023-05-26 上传
2023-06-28 上传

AYXYSYS
- 粉丝: 10
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
