Ubuntu16.04配置Hadoop2.6.5完全分布式教程
需积分: 10 193 浏览量
更新于2024-09-11
收藏 891KB DOCX 举报
"本文档提供了Hadoop2.6.5在Ubuntu16.04上的完全分布式配置步骤,包括环境准备、Hadoop安装、配置环境变量和初步测试。"
Hadoop是一个开源的分布式计算框架,主要处理和存储大量数据。在这个配置指南中,我们将专注于在Ubuntu16.04操作系统上搭建Hadoop2.6.5的完全分布式集群。在开始之前,我们需要确保已安装了VMware、Ubuntu16.04以及JDK1.8,并配置好JDK的环境变量。
1. **完全分布式模式概述**
- **独立模式**:适用于初学者,仅在单个节点上运行,无需额外配置。
- **伪分布模式**:在单台机器上模拟多节点环境,用于测试和学习,但不适用于生产环境。
- **完全分布模式**:至少包含两个节点,每个节点都有特定的角色,如NameNode、DataNode等,适合大规模数据处理。
2. **在Ubuntu上安装Hadoop**
- 从Apache官方网站下载Hadoop2.6.5的二进制文件。
- 解压缩文件并将其移动到`/usr/soft/hadoop-2.6.5`目录下。
- 配置环境变量,编辑`/etc/environment`文件,添加`HADOOP_INSTALL`和`PATH`变量。`HADOOP_INSTALL`指向Hadoop安装目录,`PATH`变量需要包含Hadoop的`bin`和`sbin`目录。
3. **环境变量生效**
- 使用`source`命令使环境变量配置生效,之后通过`echo $HADOOP_INSTALL`和`echo $PATH`检查是否正确设置。
4. **Hadoop配置**
- 在Hadoop的配置目录中,有`etc/hadoop`下的核心配置文件,如`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`,这些文件需要根据集群的具体情况进行调整。
- `core-site.xml`配置主要涉及HDFS的基本属性,如命名空间的默认值、临时文件存放位置等。
- `hdfs-site.xml`用于定义HDFS的参数,比如NameNode和DataNode的数据存储位置,副本数量等。
- `mapred-site.xml`配置MapReduce框架的参数,如JobTracker和TaskTracker的位置。
- `yarn-site.xml`配置YARN(Yet Another Resource Negotiator),负责资源管理和调度。
5. **启动和测试Hadoop集群**
- 初始化HDFS:`hadoop namenode -format`
- 启动Hadoop服务:`start-dfs.sh`和`start-yarn.sh`
- 检查NameNode和DataNode状态:`jps`命令应显示NameNode、DataNode、SecondaryNameNode和ResourceManager等进程。
- 测试HDFS写入和读取:使用`hadoop fs -put`和`hadoop fs -get`命令上传和下载文件。
- 使用Web界面监控集群状态:NameNode的50070端口和ResourceManager的8088端口。
6. **集群扩展**
- 要在更多节点上部署Hadoop,需要在其他节点上重复上述安装和配置步骤,然后将它们加入到现有集群中,通过修改`slaves`文件列出所有DataNode节点。
通过这个配置指南,你可以成功地在Ubuntu16.04上建立一个简单的Hadoop完全分布式集群,从而开始进行大数据处理。不过,实际生产环境中还需要考虑高可用性、安全性、网络拓扑等因素,这需要更深入的配置和管理。
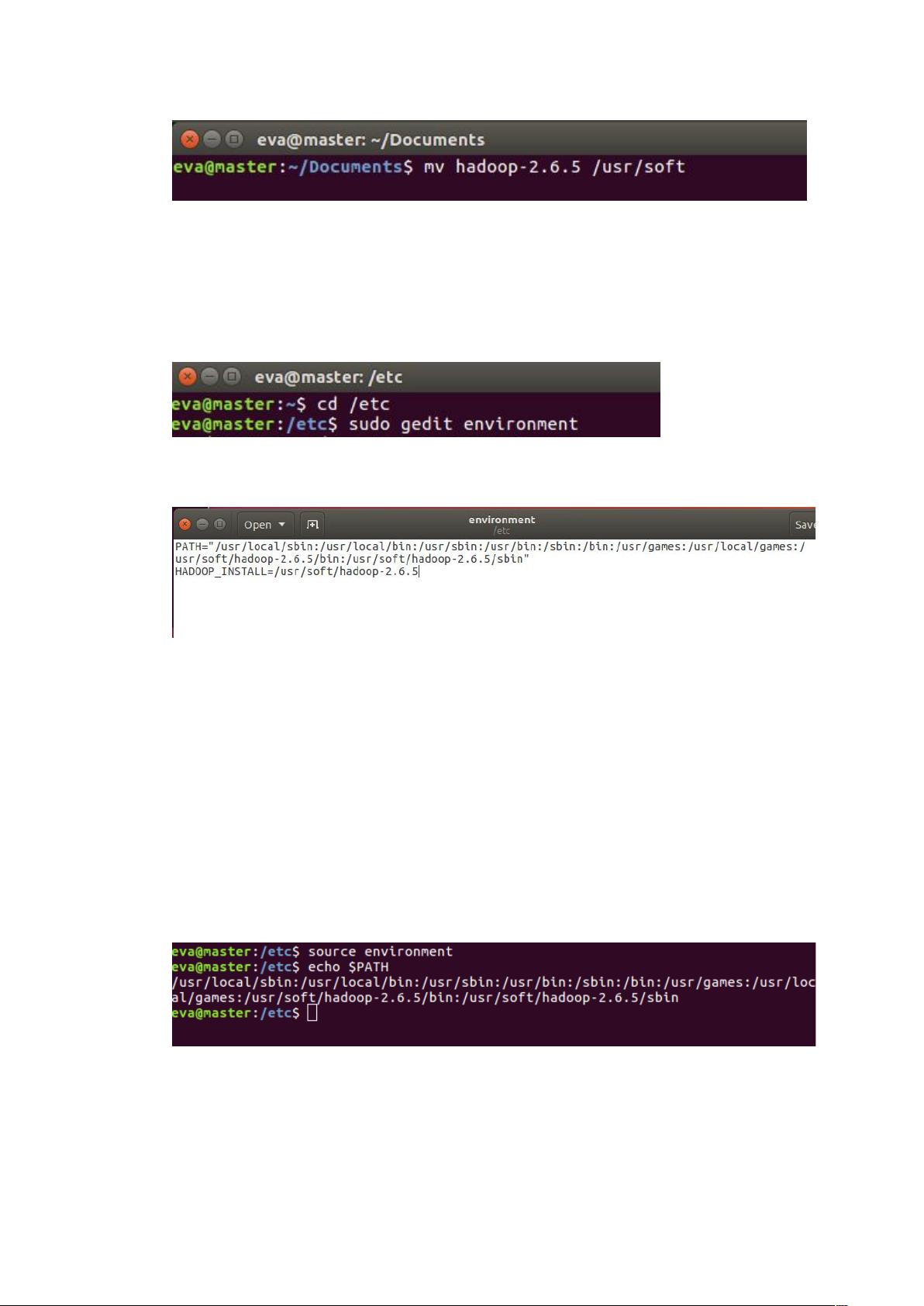
下面配置环境变量
进入根目录下 etc 目录,用 gedit 打开 encironment
在里面配置 HADOOP_INSTALL 和 PATH 两个环境变量。
其中 HADOOP_INSTALL 是 soft 中 Hadoop2.6.5 所在的目录
PATH 环境变量是在 jdk 环境变量的基础上,用冒号:分割,加入 Hadoop
的 bin 和 sbin 两个目录的地址。如上图所示。(上图中 games:后面的部分为
Hadoop 的配置路径,大家根据自己的地址对号入座)
然后用 source 编译 environment 文件,使得环境变量生效。之后可以通
过 echo $+变量名来查看环境变量。如图
现在 Hadoop 已经在本机安装好了,或者说“独立模式”的 Hadoop 已经安
装好了。可以通过输入 hadoop version 命令来验证。version 前没有”-“
剩余12页未读,继续阅读
114 浏览量
130 浏览量
304 浏览量
276 浏览量
124 浏览量
1277 浏览量
422 浏览量
366 浏览量
412 浏览量

Evsho
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







