Spark高可用HA集群部署实战指南
需积分: 15 187 浏览量
更新于2024-07-21
收藏 2.66MB PPTX 举报
“通过案例实战掌握高可用HA下的Spark集群部署”
本课程主要针对大数据领域的专业人士,旨在通过实际操作案例帮助学员深入理解并掌握在高可用性(HA)环境下的Spark集群部署。Spark作为一种快速、通用且可扩展的数据处理引擎,其在大数据分析中的应用日益广泛。在高可用模式下部署Spark集群,可以确保系统的稳定性和数据处理的连续性,避免单点故障对整个工作流程的影响。
课程的第一期重点讲解如何配置和管理具有HA功能的Spark集群。这将包括但不限于以下几个关键知识点:
1. **Spark高可用性架构**:讲解Spark的主节点(Master)角色和备份节点(Standby Masters)的概念,以及如何设置和配置这些节点以实现HA。
2. **Zookeeper集成**:Spark HA通常依赖于Zookeeper进行主节点选举,课程会介绍如何设置和管理Zookeeper集群,以及它在Spark HA中的作用。
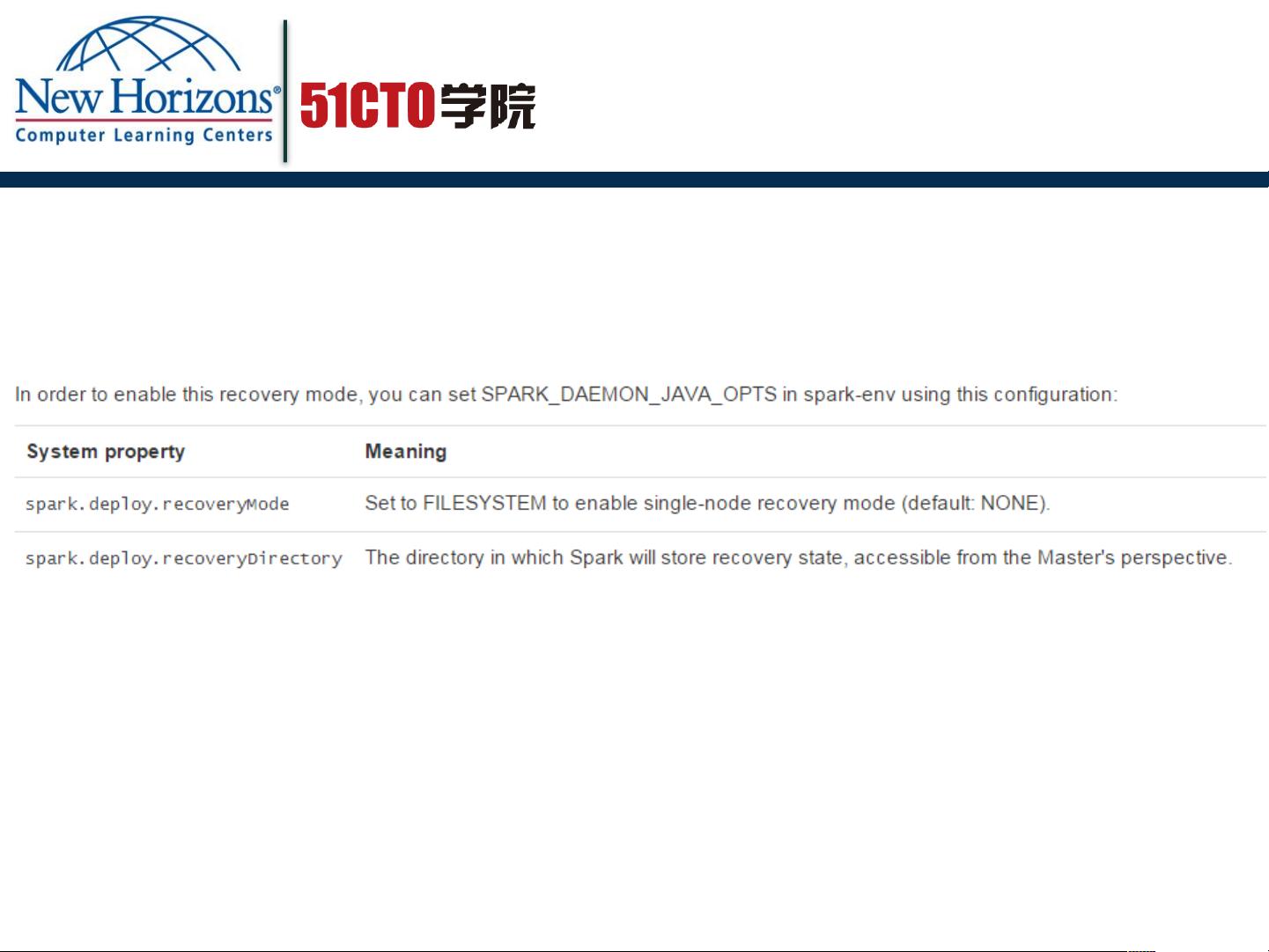
3. **Spark配置**:详细解析与HA相关的配置参数,如`spark.master`, `spark.deploy.recoveryMode`, `spark.deploy.zookeeper.url`等,以及如何根据实际需求调整这些参数。
4. **故障切换机制**:解释当主节点失效时,如何通过Zookeeper触发故障切换,以及备份节点如何接管成为新的主节点。
5. **集群监控和管理**:讨论如何使用工具(如Ganglia或Ambari)监控Spark集群的健康状态,以及在HA环境中如何进行故障排查和问题修复。
接下来的课程将逐步深入Spark的核心功能和内部机制,包括Spark编程模型、内核运行内幕、SparkSQL、DataFrame、Hive on Spark、Spark Streaming、GraphX、SparkR、Spark on Tachyon、运维和调优等。这些课程将涵盖Spark的各个组件和用例,使学员能够全面了解和掌握Spark的使用和优化。
课程还将涉及Spark的任务调度系统、Shuffle机制、存储系统、在YARN和Mesos上的部署等底层细节,深入剖析源码,帮助学员理解Spark的工作原理。此外,课程还将涵盖机器学习相关的实战和源码揭秘,如Logistic Regression和SVM的实现,进一步提升学员在大数据分析和预测建模方面的技能。
通过这系列课程,学员不仅能够具备在生产环境中部署和管理高可用Spark集群的能力,还能深入理解Spark的内在机制,从而更好地利用Spark解决实际业务问题。
剩余28页未读,继续阅读
578 浏览量
121 浏览量
2023-08-31 上传
215 浏览量
107 浏览量
2233 浏览量
138 浏览量
点击了解资源详情

qq_30851611
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 英语常用3500词音频+PDF文件(含音频).zip
- 老板计时器
- Honey Boo Boo的算法和功能分解
- ember-addon-config
- 1.8wUA库.zip
- reading-notes:在这里您可以找到我的阅读资料库,主要用于总结我在编程方面的学习历程,希望您能找到一些有用的信息<3
- 视频播放可弹出弹幕,关闭弹幕
- simple-spawner:生成一个命令并将输出通过管道返回到 std{in,out,err}
- CSS_Assignment_2
- 使用注释将JDBC结果集映射到对象
- curious-blindas-api:CuriousCat克隆
- PRO-C21-BULLETS-AND-WALLS
- ff35mm:Flickr 的全画幅 (35mm) 焦距
- C#解析HL7消息的库
- 将Java System.out定向到文件和控制台的快速简便方法
- 库索逻辑-葡萄牙语
