使用Kaldi构建语音识别系统
需积分: 9 155 浏览量
更新于2024-07-17
收藏 17.65MB PDF 举报
"这篇文档是关于使用Kaldi工具包构建语音识别系统的研究,由Sanjeev Khudanpur、Dan Povey和Jan Trmal来自约翰斯·霍普金斯大学的语言与语音处理中心共同撰写。Kaldi是在2009年在马里兰州巴尔的摩诞生的,随着时间的发展,它变得越来越成熟,并且有超过60位贡献者参与其中。文中还提到了语音搜索从被宣告解决到再次成为未解问题的过程,以及2012年IARPA推出的BABEL项目,旨在自动转录会话电话语音。"
Kaldi工具包是构建语音识别系统的重要资源,由语音和语言处理领域的专家开发。这个开源工具包提供了构建先进ASR(Automatic Speech Recognition,自动语音识别)系统的框架,使得研究人员和开发者能够更容易地处理各种语音识别任务。Kaldi的出现显著降低了开发自定义ASR系统的门槛,它的成长和改进反映了该领域技术的快速进步。
在20世纪90年代末的NIST TREC SDR(Text Retrieval Evaluation Conference Spoken Document Retrieval)中,语音识别技术的进步使得从语音转文本后的信息检索效果几乎等同于使用参考文本来检索,因此当时认为语音搜索问题已经解决。然而,随着时间推移,特别是在2006年的NIST STD Pilot项目中,人们发现自动语音识别(STT,Speech-to-Text)在处理会话式电话语音中的关键词检测时表现不足,揭示了这一领域的复杂性和挑战。
2012年,IARPA启动了BABEL计划,这是一个针对多语言语音识别的项目,因为之前的数据集如英语的Switchboard、CallHome和Fisher,以及阿拉伯语和普通话的CallHome数据集,虽然对英语研究有所帮助,但它们的语言多样性有限。BABEL项目的推出是为了应对这一挑战,目标是实现对广泛语言的会话电话语音的自动化转录。
Dan Povey在2012年回到Kaldi的诞生地,这可能意味着Kaldi在这个背景下得到了进一步的发展,特别是在处理会话电话语音和应对多语言识别需求方面。Kaldi的广泛应用和持续更新表明,它已经成为解决复杂语音识别问题和推动相关研究的重要工具。
通过Kaldi,开发者可以利用其丰富的功能,例如HMM-GMM(隐马尔科夫模型-高斯混合模型)和DNN-HMM(深度神经网络-隐马尔科夫模型)方法进行建模,以及数据准备、训练、解码和评估等一系列流程。此外,Kaldi社区的活跃度和贡献者数量证明了它在学术界和工业界的影响力,使得更多的人能够参与到语音识别技术的研发中,推动整个领域不断前进。

!"#$%#&'(7&()88()123+4(5#3-(67$%#(
• >737(*<+*7<70/&(
– [,/"20,(4/%+$(3<7#&#&'(%737(
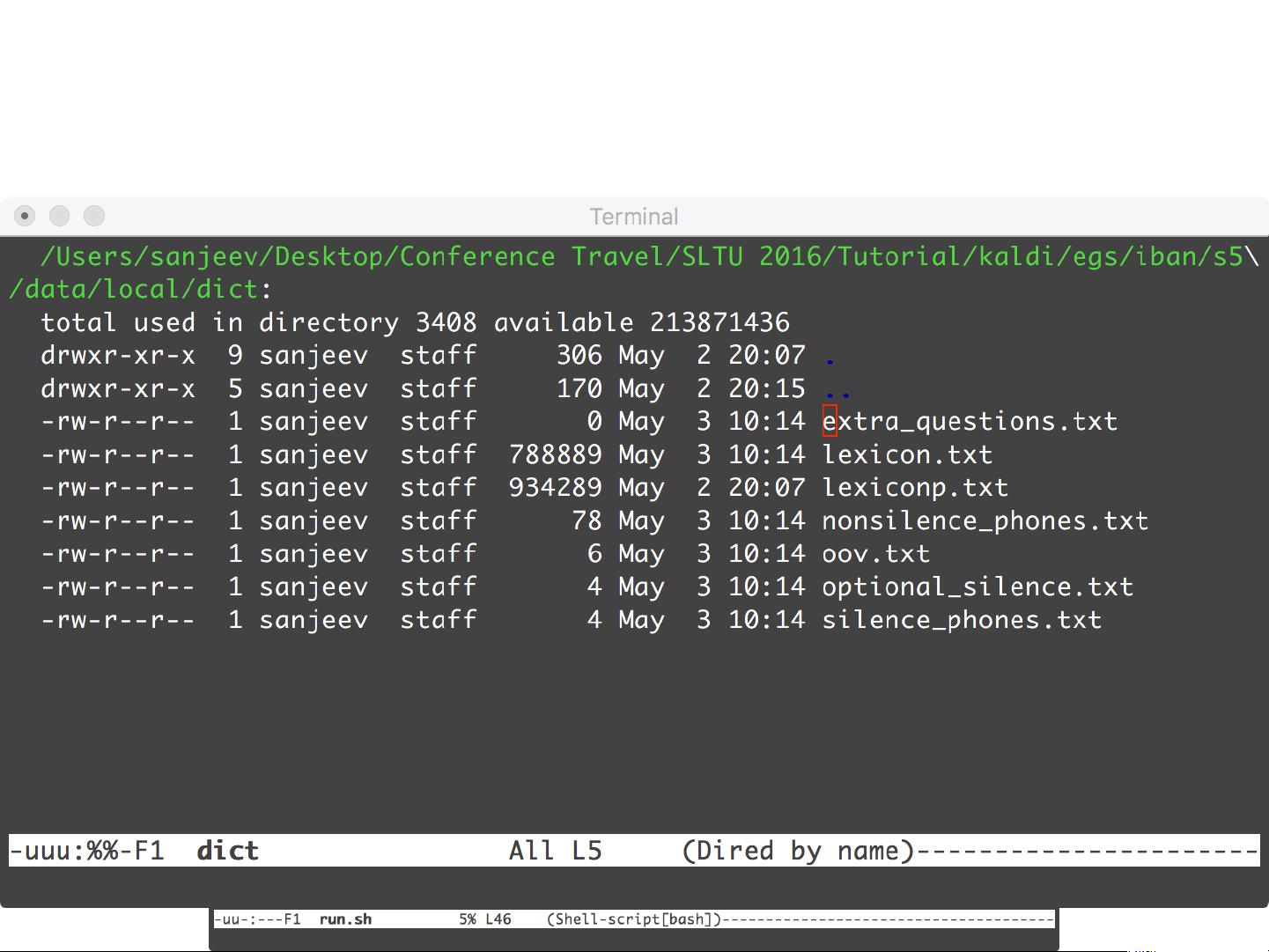
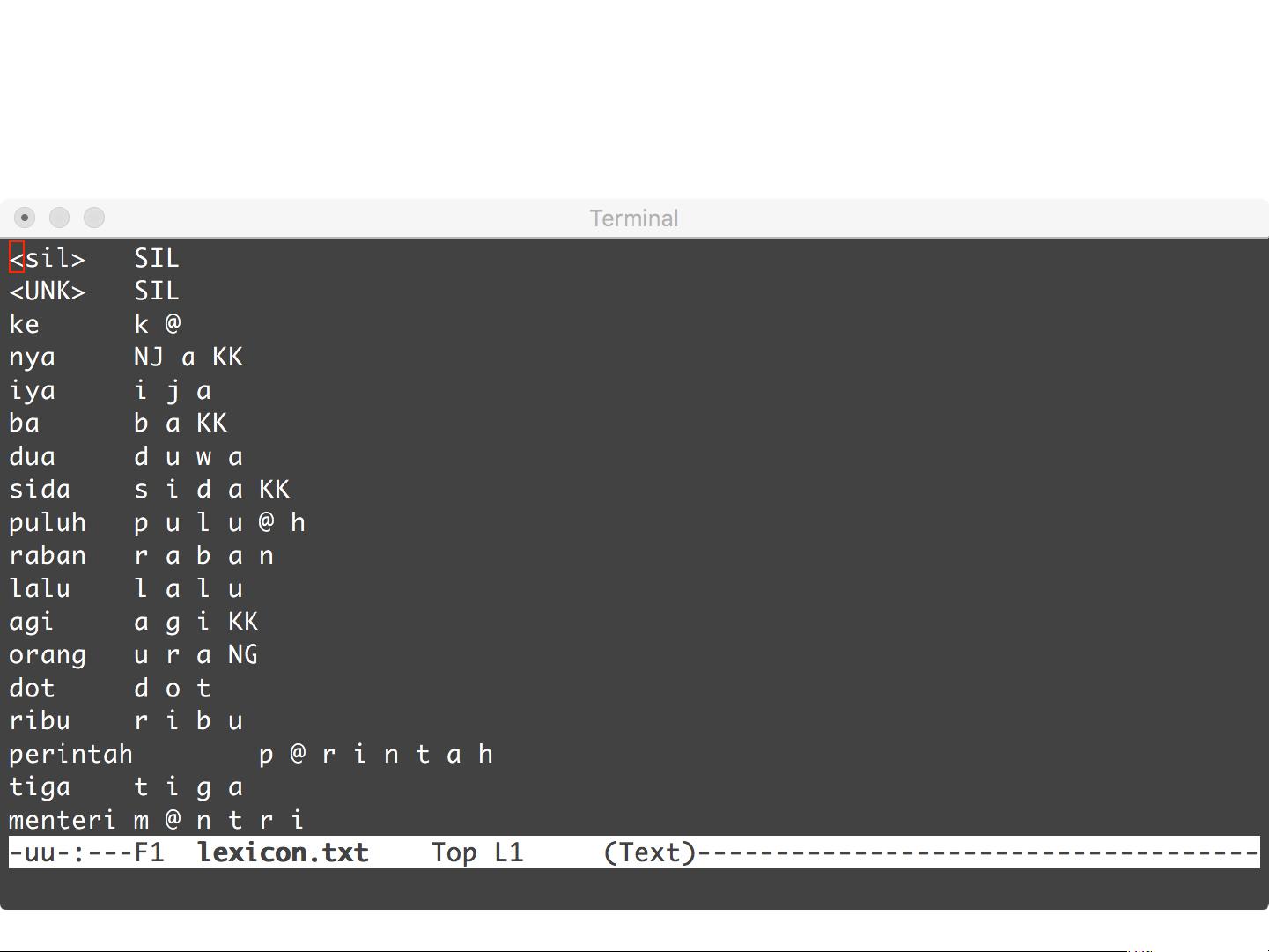
– Pronuncia$on'lexicon'
– E7&'"7'+(4/%+$(3<7#&#&'(%737(
• !72#,(iMM(2123+4(L"#$%#&'(
– [,/"20,(4/%+$(3<7#&#&'(
– E7&'"7'+(4/%+$(3<7#&#&'(
• !72#,(>+,/%#&'(
– C<+70&'(7(2370,(%+,/%#&'('<7*-(
– E7n,+(<+2,/<#&'(
• !72#,(>TT(2123+4(L"#$%#&'(
• i/#&'(L+1/&%(3-+(L72#,2(
剩余120页未读,继续阅读
327 浏览量
2021-04-04 上传
2022-07-15 上传
2022-07-15 上传
2022-07-15 上传
166 浏览量

aiXpert
- 粉丝: 225
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动抄表系统中几种传感器的应用
- Vxworks入门实验
- Spring框架的简要分析.doc
- Operating System(Chapter 1)
- RDP协议详解(remote desktop protocol)
- Resin_brochure
- eclipse中文文档
- ASP.NET 不仅仅是 Active Server Page (ASP) 的下一个版本;它还提供了一个
- C#和.Net的优点研究了一下C#和.Net,有很多体会,好的不好的都有。随便谈谈,供大家参考。
- 深入理解计算机系统(英文版)
- Practical UML Statecharts in C,C++, Second Edition.pdf
- JSP 实用教程 (第二版) 代码
- 经典c程序编程100例
- 常用DIV+CSS网页制作布局技术技巧
- scilab 软件的帮助说明
- PowerPCB教程.pdf
