Hive简介:Hadoop生态系统中必不可少的SQL工具
需积分: 0 51 浏览量
更新于2024-01-11
收藏 614KB DOCX 举报
第12章 Hive是Hadoop生态系统中必不可少的一个工具,最初由Facebook提供。Hive提供了一种SQL(结构化查询语言)方言,可以查询存储在Hadoop分布式文件系统(HDFS)中的数据或其他Hadoop集成的文件系统,如MapR-FS、Amazon的S3以及像HBase和Cassandra这样的数据库中的数据。Hive的设计目的是让SQL技能良好,但Java技能较弱的分析师可以查询海量数据。2008年,Facebook将Hive项目贡献给Apache。然而,Hive自身的最大缺点是执行速度较慢。
Hive的系统架构主要包括用户接口、HiveQL解析器、优化器、执行引擎和存储引擎等组件。其中,用户接口是Hive自带的几种交互式接口,如CLI、JDBC/ODBC和Web GUI HWI。用户可以通过这些接口来执行HiveQL查询语句,并获取查询结果。HiveQL解析器负责解析用户输入的HiveQL查询语句,转换成执行计划树。优化器则对执行计划树进行优化,包括查询重写、表达式下推和列剪裁等优化策略,以提高查询性能。执行引擎则负责执行经优化后的执行计划,将查询分解为一系列的MapReduce任务或Tez任务,并将结果返回给用户。存储引擎则负责将数据存储在Hadoop生态系统中,支持多种文件格式和压缩编码,如ORC、Parquet和Snappy等。
Hive支持类似于SQL的查询语法,可以使用SELECT、JOIN、GROUP BY和ORDER BY等关键字进行数据查询和处理。同时,Hive还提供了用户自定义函数(UDF)、用户自定义聚合函数(UDAF)和用户自定义表生成器(UDTF)等扩展功能,以满足用户对自定义计算逻辑的需求。此外,Hive还支持动态分区和分桶等数据组织和查询优化技术,使得查询更加高效。
然而,Hive执行速度慢是其最大的缺点之一。这主要是由于Hive将HiveQL查询转换为MapReduce任务或Tez任务进行执行的方式导致的。在这种方式下,每个查询都需要启动一个新的MapReduce或Tez作业,涉及到大量的任务调度和数据IO操作,造成了较高的延迟。为了解决这个问题,Hive引入了向量化执行和基于列存储的优化技术,以提高查询性能。向量化执行将多条记录打包成向量,进行批量处理,减少了任务启动和数据IO的开销。基于列存储则将相同列的数据存储在一起,提高数据的读取效率。
此外,Hive还支持数据仓库功能,可以将结构化数据加载到Hive表中,并进行数据转换、汇总和分析等操作。Hive的数据仓库功能使得用户可以更加灵活地处理和分析海量结构化数据,支持离线批处理和实时查询等多种数据处理模式。同时,Hive还支持数据的导入和导出,可以将Hive表的数据导出为其他格式文件,或将其他格式文件导入到Hive表中。
总之,Hive是Hadoop生态系统中一款重要的工具,为用户提供了一种方便易用的SQL查询接口,支持海量数据的高效查询和数据仓库功能。虽然Hive执行速度较慢,但通过引入向量化执行和列存储等优化技术,可以提高查询性能。此外,Hive还具有灵活的数据导入和导出功能,支持多种文件格式和压缩编码。因此,Hive在大数据处理和分析领域有着广泛的应用前景。
<value> jdbc:mysql://localhost:3306/hivedb?createDatabaseIfNotExist=true</value>
<describe>默认的配置元数据是存放在 Derby 数据库里面的,我们使用 MySQL 来存储元数据</describe>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>*****(根据自己的用户名填)</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>*****(根据自己的密码填)</value>
</property>
其他的一些配置项:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/opt/hive-1.2.1/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/opt/hive-1.2.1/scratchdir</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/opt/hive-1.2.1/logs</value>
</property>
� hive.metastore.warehouse.dir:指定 hive 的数据存储目录,指定的是 HDFS 上的位置,默认
值:/usr/hive/warehouse,为了方便管理也可以在 linux 上指定一个目录。
� hive.exec.scratchdir:指定 hive 的临时数据目录,默认位置为:tmp/hive-${user.name}。为了方便管
理也可以在 linux 上指定一个目录。
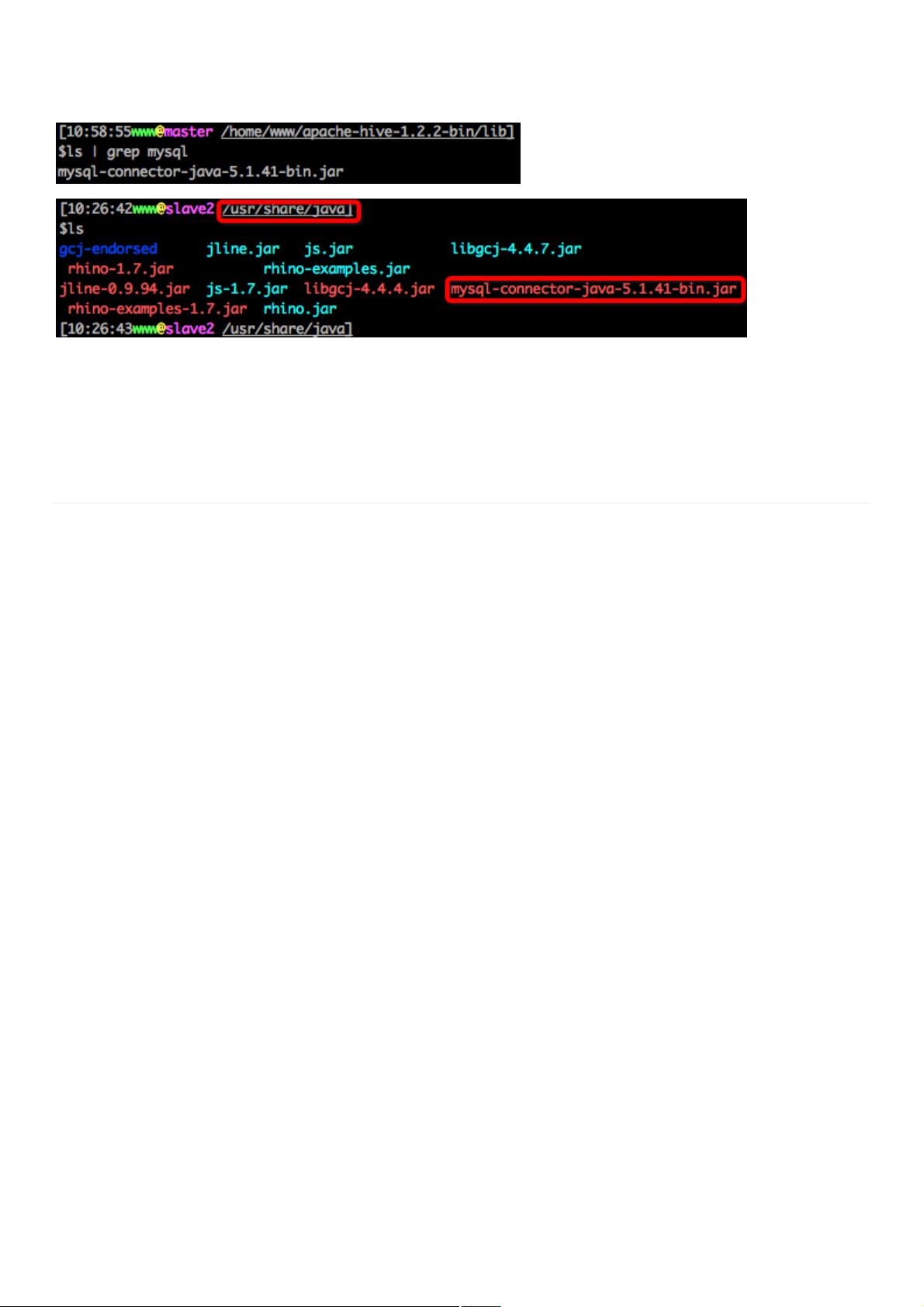
4.上传 JDBC jar 包
剩余35页未读,继续阅读
2017-12-21 上传
2021-09-20 上传
2022-03-11 上传
2023-08-25 上传
2023-05-11 上传
2023-12-03 上传
2023-08-13 上传
2024-07-10 上传
2023-07-12 上传

蒋寻
- 粉丝: 30
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
