探索图数据库入门:Neo4j引领的连接数据潮流
需积分: 8 5 浏览量
更新于2024-07-17
收藏 3.83MB PDF 举报
"《图数据库入门指南:Neo4j实战》"
在当前信息技术领域,图数据库正崭露头角,成为了连接数据的新一代平台。本文档《Graph Databases for Beginners》由Bryce Merkl Sasaki、Joy Chao和Rachel Howard撰写,专为对图技术知之甚少或完全没有背景的读者设计,旨在引导他们理解和探索这一强大的工具。图数据库,如Neo4j,因其独特的关注点——关系模型而变得尤为重要。
在当今世界,传统的关系型数据库可能无法有效处理复杂的数据网络,例如社交网络、推荐系统或者实体之间的多对多关联。图数据库正是为了解决这类问题而生,它们强调节点和边的连接,能够更好地捕捉现实世界的动态性和复杂性。在这个指南中,作者会介绍:
1. 基础知识:从零开始,逐步介绍图的概念,包括节点(Node)、边(Edge)和属性(Property),以及它们如何构成图结构。
2. 图存储与查询:讲解如何在Neo4j这样的图数据库中存储和查询数据,特别是Cypher查询语言的使用,这对于理解数据的检索和操作至关重要。
3. 关系型与非关系型比较:对比关系型数据库和图数据库的优缺点,让读者理解何时选择图数据库更合适。
4. 实际应用示例:提供真实世界中的案例,如推荐系统、知识图谱构建等,展示图数据库在解决特定业务问题上的效能。
5. 迁移与实践:对于考虑从其他数据库转向Neo4j的开发者,会分享一些实用技巧和最佳实践,帮助他们顺利过渡。
6. 未来趋势与挑战:探讨图数据库在大数据、人工智能和物联网时代的发展前景,以及可能面临的挑战和应对策略。
通过阅读本指南,无论是企业高管还是开发人员都能对图数据库有深入的理解,并决定是否将其纳入自己的业务和技术栈中。图数据库并非一时潮流,而是顺应了现代数据需求变化,为理解和利用连接数据提供了强大而必要的工具。
neo4j.com7
Graph Databases For Beginners
neo4j.com7
Now, for our match-up.
If we were working with a relational database, the business leaders, subject-matter experts
and system architects would convene and create a data model similar to the image above
that shows the entities of this domain, how they interrelate and any rules applicable to the
domain. We would then create a logical model from this initial whiteboard sketch before
mapping it into the tables and relations we see below.
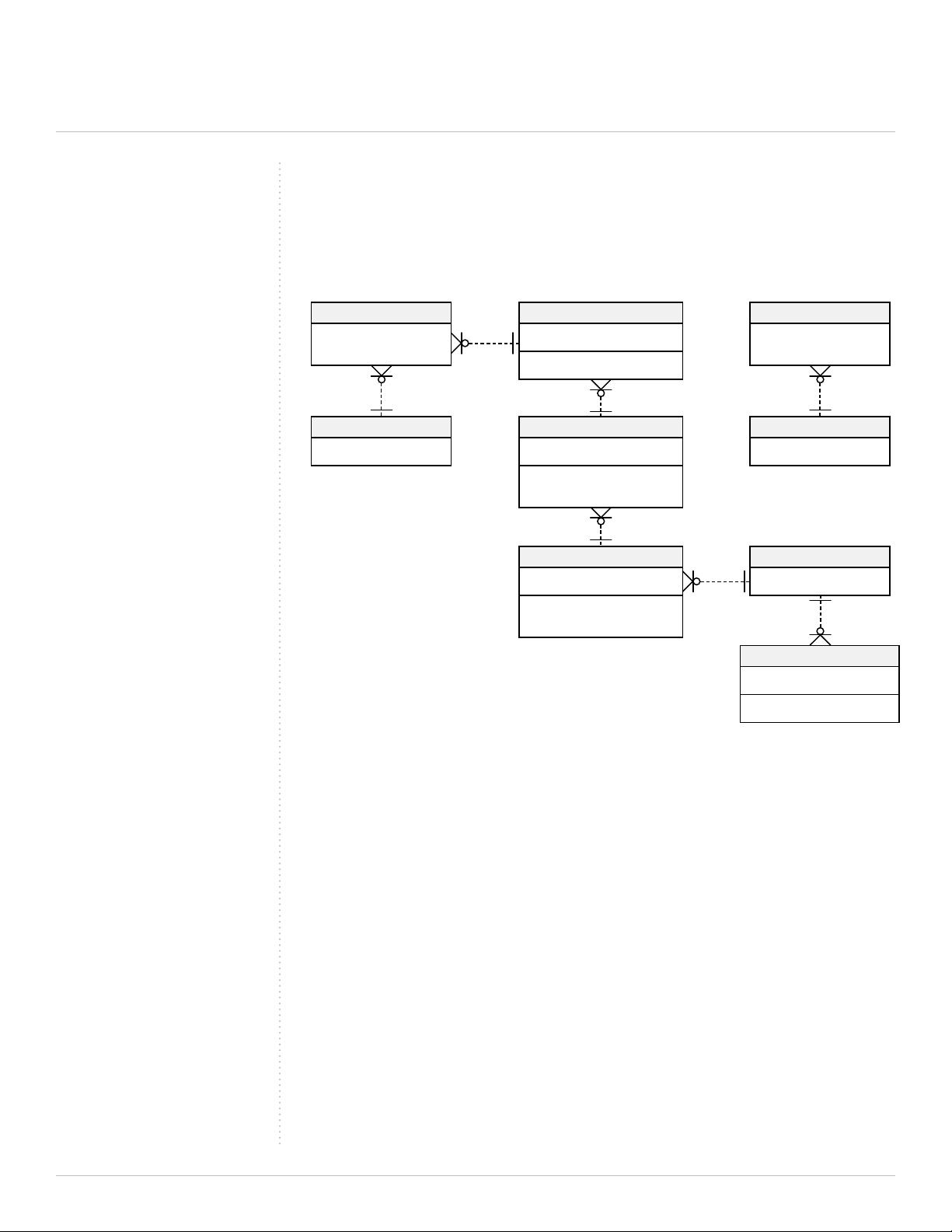
FIGURE 3.2: The relational database version of our initial “whiteboard” data model.
Several JOIN tables have been added just so dierent tables can communicate with
one another.
AppDatabase
AppId: INTEGER [FK]
DatabaseId: INTEGER [FK]
UserApp
UserId: INTEGER [FK]
AppId: INTEGER [FK]
User
UserId: INTEGER [PK]
Rack
RackId: INTEGER [PK]
Load Balancer
LoadBalancedId: INTEGER [PK]
RackId: INTEGER [FK]
App
AppId: INTEGER [PK]
VirtualMachineId: INTEGER [FK]
VirtualMachine
VirtualMachineId: INTEGER [PK]
AppInstanceId: INTEGER
BladeId: INTEGER [FK]
Server
BladeId: INTEGER [PK]
RackId: INTEGER [FK}
VirtualMachineId: INTEGER
Database Server
DatabaseID: INTEGER [PK]
In the diagram above, we’ve had to add a lot of complexity into the system to make it t
the relational model. First, everywhere you see the annotation FK (tech lingo: foreign key) is
another point of added complexity.
Second, new tables have crept into the diagram such as “AppDatabase” and “UserApp.” These
new tables are known as JOIN tables, and they signicantly slow down the speed of a query.
Unfortunately, they’re also necessary in a relational data model.
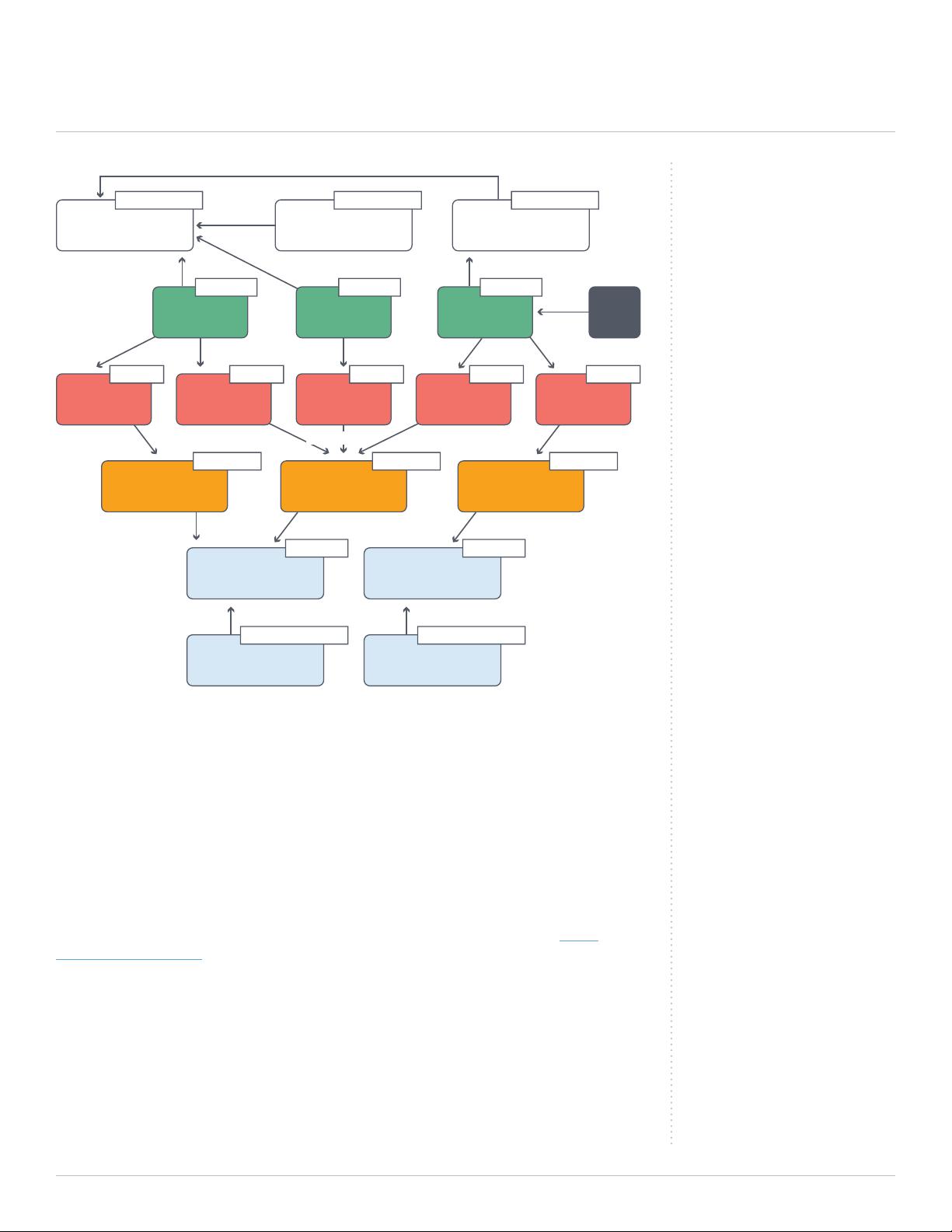
Now let’s look at how we would build the same application with a graph data modeling
approach. At the beginning, our work is identical – decision makers convene to produce a
basic whiteboard sketch of the data model (Figure 3.1).
After the initial whiteboarding step, everything looks dierent. Instead of altering the initial
whiteboard model into tables and JOINs, we enrich the whiteboard model according to our
business and user needs.
Figure 3.3 on the next page shows our newly enriched data model after adding labels,
attributes and relationships:
"The huge advantage
with Neo4j was that
we were able to focus
on modeling our data
and how to best serve
our customers instead
of agonizing how to
structure tables and
JOINs. It also required
very little coding, so
we were able to keep
our focus on our
customers."
-- Josh Marcus, CTO,
Albelli
剩余45页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-13 上传

ssyshenn
- 粉丝: 23
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
