手机:从通讯工具到多媒体中心
需积分: 10 157 浏览量
更新于2025-01-02
收藏 1.62MB PDF 举报
随着科技的飞速发展,移动电话已经从最初的通信工具转变为全球范围内的日常生活必需品。据统计,到2008年,全球有一半人口(即33亿人)使用手机,这一数字预计在2010年将增长到与牙刷用户数量相当的40亿。这种现象的背后,是移动电话功能的显著扩展和技术创新。
过去的十年里,手机经历了革命性的转变。它不再仅仅是一个通话设备,而是集成了多种多媒体功能。如今的手机配备了高分辨率的彩色显示器,如24位真彩(16,800,000种颜色)的屏幕,甚至达到了VGA标准(640×480像素),使得视觉体验更加丰富。用户可以享受游戏娱乐,例如通过手机玩游戏(见图1),这已经成为一种流行的消遣方式。
拍照功能的提升也是手机发展的一大亮点。手机摄像头从早期的黑白小像素逐渐升级,能够捕捉高质量的照片,满足用户的记录生活和分享瞬间的需求。音乐播放能力也不容忽视,手机内置或外接音乐播放器,让用户随时随地享受音乐的乐趣。
视频观看和制作方面,现代手机支持高清视频播放和拍摄,无论是观看在线视频流、YouTube内容,还是录制日常生活片段,都变得轻而易举。消息传递功能的进步使得沟通更为便捷,无论是短信、社交媒体应用还是即时通讯软件,手机都扮演着核心角色。
视频会议技术的发展更是推动了移动办公的普及。通过手机的摄像头和稳定的网络连接,人们可以进行远程商务会议,极大地提高了工作效率和灵活性。这意味着无论身处何地,只要有信号覆盖,就可以实现面对面的交流。
此外,手机还在不断融入更多的创新技术,如增强现实(AR)、虚拟现实(VR)和物联网(IoT)的结合,为用户提供更沉浸式和个性化的体验。这些进步不仅得益于硬件性能的提升,也依赖于软件算法和无线通信技术的优化。
总结来说,现代移动电话已经成为一个多功能的生活伴侣,它在通信、娱乐、工作以及个人表达等多个领域发挥着关键作用。随着技术的持续迭代,未来的手机将可能承载更多元化和智能化的功能,进一步改变我们的生活方式。
76 July/August 2008
Mobile Graphics Survey
Compression
Compression not only saves storage space, but it
also reduces the amount of data sent over a net-
work or a memory bus. For GPUs, compression
and decompression (codec) have two major tar-
gets: textures and buffers.
Textures are read-only images glued onto geomet
-
rical primitives such as triangles. A texture codec
algorithm’s core requirements include fast random
access to the texture data, fast decompression,
and inexpensive hardware implementation. The
random-access requirement usually implies that a
block of pixels is compressed to a xed size. For ex-
ample, a group of 4 × 4 pixels can be compressed
from 3 × 8 = 24 bits per pixel down to 4 bits per
pixel, requiring only 64 bits to represent the whole
group. As a consequence of this xed-rate compres
-
sion, most texture compression algorithms are lossy
(for example, JPEG) and usually don’t reproduce the
original image exactly. Because textures are read-
only data and usually compressed ofine, the time
spent compressing the image isn’t as important as
the decompression time, which must be fast. Such
algorithms are sometimes called asymmetric.
As a result of these requirements, developers have
adopted Ericsson Texture Compression (ETC) as a
new codec for OpenGL ES.
6
ETC stores one base
color for each 4 × 4 block of texels and modies
the luminance using only a 2-bit lookup index per
pixel. This technique keeps the hardware decom-
pressor small. Currently, no desktop graphics APIs
use this algorithm.
Buffers are more symmetric than textures in
terms of compression and decompression because
both processes must occur in hardware in real time.
For example, the color buffer can be compressed,
so when a triangle is rendered to a block of pix-
els (say, 4 × 4) in the color buffer, the hardware
attempts to compress this block. If this succeeds,
the data is marked as compressed and sent back to
the main memory in compressed form over the bus
and stored in that form. Most buffer compression
algorithms are exact to avoid error accumulation.
However, if the algorithm is lossy, the color data
can be lossily compressed and later recompressed,
and so on, until the accumulated error exceeds the
threshold for what’s visible. This is called tandem
compression, meaning that if compression fails, you
must have a fallback that guarantees an exact color
buffer—namely, sending the data uncompressed.
7
Depth and stencil buffers might also be com-
pressed. The depth buffer deserves special men-
tion because its contents are proportional to 1/z,
and when viewed in perspective, the depth values
over a triangle remain linear. Depth-buffer com
-
pression algorithms heavily exploit this property,
which accounts for higher compression rates. A
survey of existing algorithms appears elsewhere.
8
Interestingly, all buffer codec algorithms are
transparent to the user. All action takes place in the
GPU and is never exposed to the user or program-
mer, so there’s no need for standardization. There’s
no major difference for buffer codec on mobile
devices versus desktops, but mobile graphics has
caused renewed interest in such techniques.
Tiling architectures
Tiling architectures aim to reduce the memory traf-
c related to frame-buffer accesses using a com
-
pletely different approach. Tiling the frame buffer
so that a small tile (such as a rectangular block of
pixels) is stored on the graphics chip provides many
optimization and culling possibilities. Commercial-
ly, Imagination Technologies and ARM offer mobile
3D accelerators using tiling architectures. Their core
insight is that a large chunk of the memory accesses
are to buffers such as color, depth, and stencil.
Ideally, we’d like the memory for the entire frame
buffer on-chip, which would make such memory
accesses extremely inexpensive. However, this isn’t
practical for the whole frame buffer, but storing a
small tile of, say, 16 × 16 pixels of the frame buffer
on-chip is feasible. When all rendering has been
nished to a particular tile, its contents can be
written to the external frame buffer in an efcient
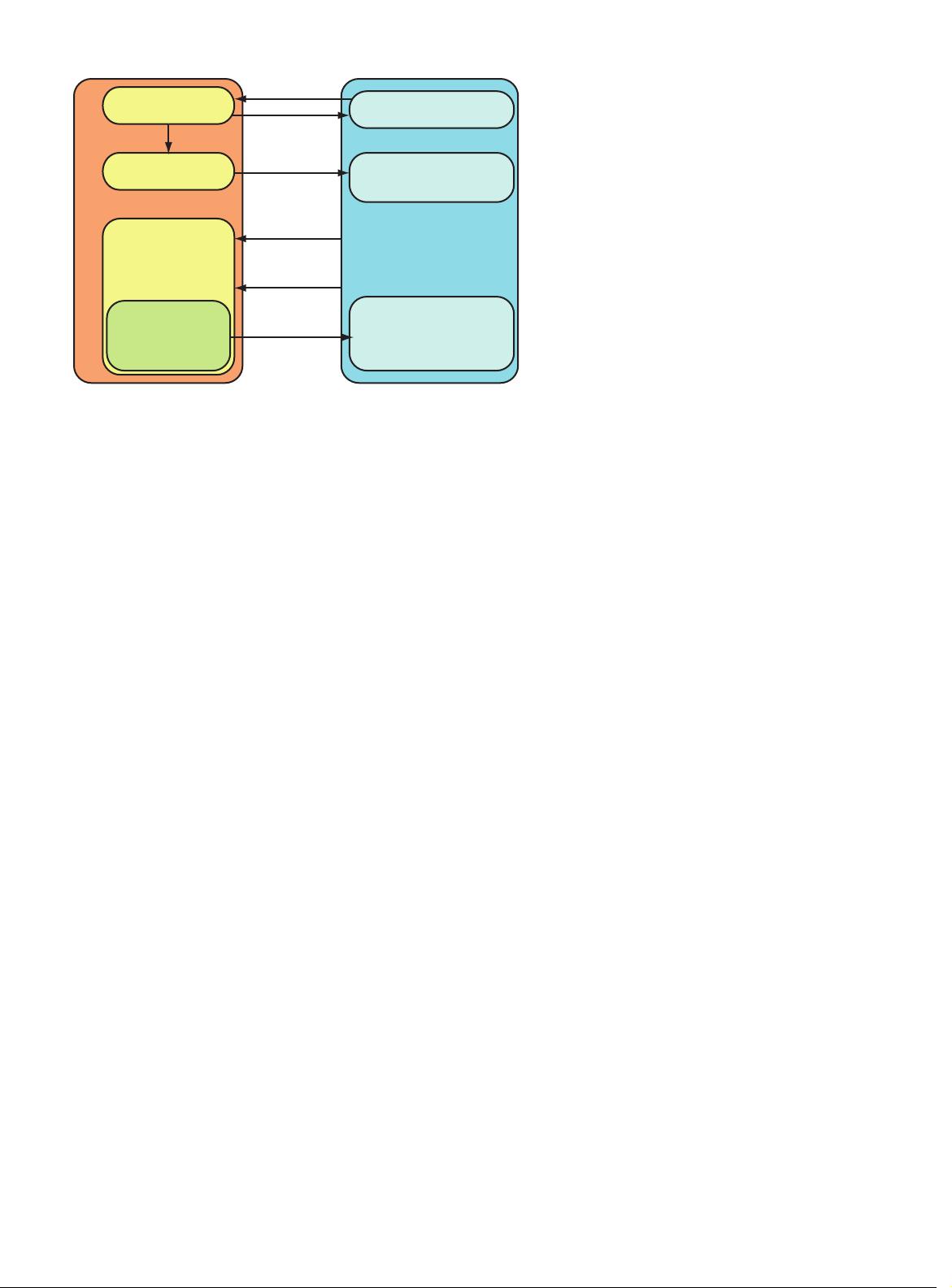
block transfer. Figure 2 illustrates this concept.
However, tiling has the overhead that all the tri-
angles must be buffered and sorted into correct tiles
after they’re transformed to screen space. A tiling
Tiling
Rasterizer
pixel shader
Memory
Primitives
Primitives
Geometry
Scene data
Transformed
scene data
Frame buffer
Tile lists
Primitives
per tile
Texture read
Write
RGBA/Z
On-chip
buffers
GPU
Figure 2. A tiling architecture. The primitives are being transformed
and stored in external memory. There they are sorted into tile lists,
where each list contains the triangles overlapping that tile. This makes it
possible to store the frame buffer for a tile (for example, 16 × 16 pixels)
in on-chip memory, which makes accesses to the tile’s frame buffer
extremely inexpensive.
剩余10页未读,继续阅读
116 浏览量
139 浏览量
2013-03-09 上传
118 浏览量
2011-10-13 上传

SunHaoLi1988
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Zigbee入门学习
- at&t 部分语法大 其中的一个小块
- ARM嵌入式系统实验教程(二)附加实验教程
- NETBEANS RCP.PDF
- 基于超混沌的FM_DCSK系统的性能分析.pdf
- GPRS模块Q39的介绍
- 《effective software testing》 addison wesley 著
- unix/linux系统管理
- 基于ORACLE数据融合的一卡通系统的实现
- java西安公司考试考试资源
- FPGA设计的经验谈
- RestFul_Rails_Dev_v_0.1
- 软件工程师笔试题目(应聘)
- 宫东风考研英语讲座.宫东风考研英语讲座
- ARM嵌入式WINCE实践教程
- SCCP信令原理介绍
