深入解析Spark内存管理机制与优化策略
需积分: 9 31 浏览量
更新于2024-07-19
收藏 1.72MB PDF 举报
深度解析Spark如何利用内存
Spark是一个强大的分布式计算框架,其内存管理是其高效性能的关键组成部分。在深入探讨"Spark内存使用深度解析"这一主题时,我们重点关注以下几个关键点:
1. **内存使用概述**
Spark内存主要分为三个部分:存储、执行和其他。存储内存用于临时缓存数据,以便后续操作使用,这部分由内存管理器控制。执行内存则用于执行计算密集型任务,如shuffle操作、JOIN、排序和聚合,同样受内存管理器调度。其他内存包含用户数据结构、内部元数据、用户自定义函数(UDF)创建的对象等。
2. **内存内容竞争**
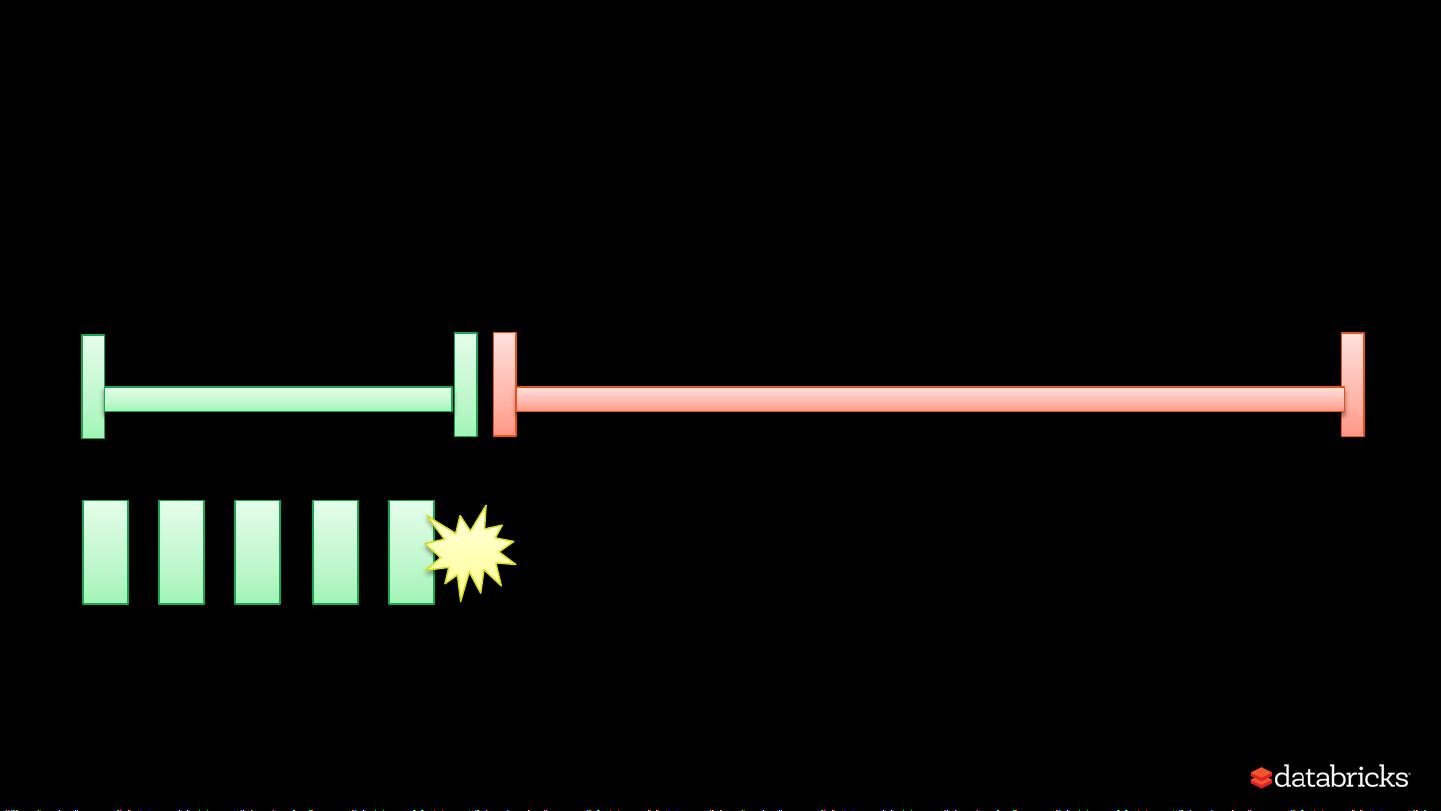
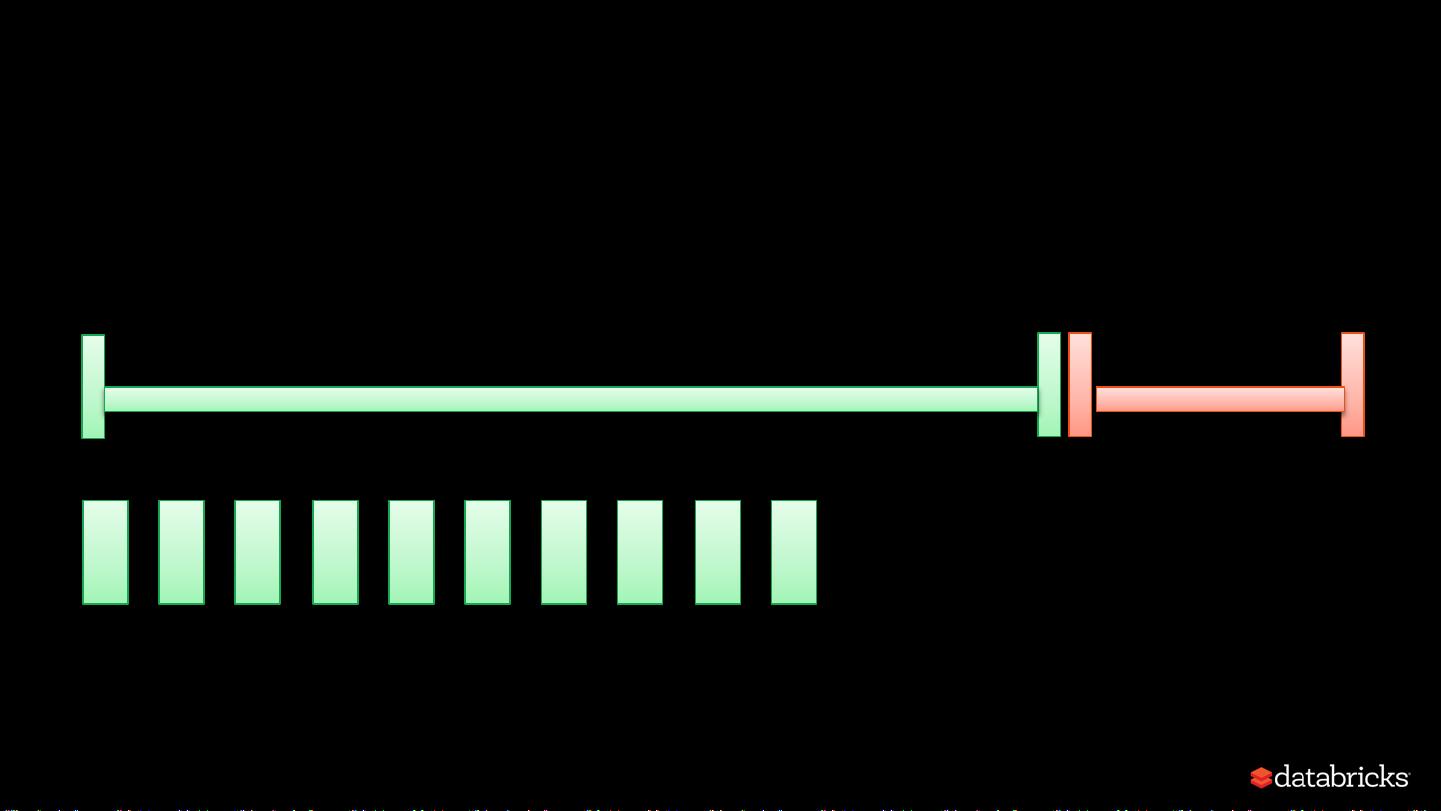
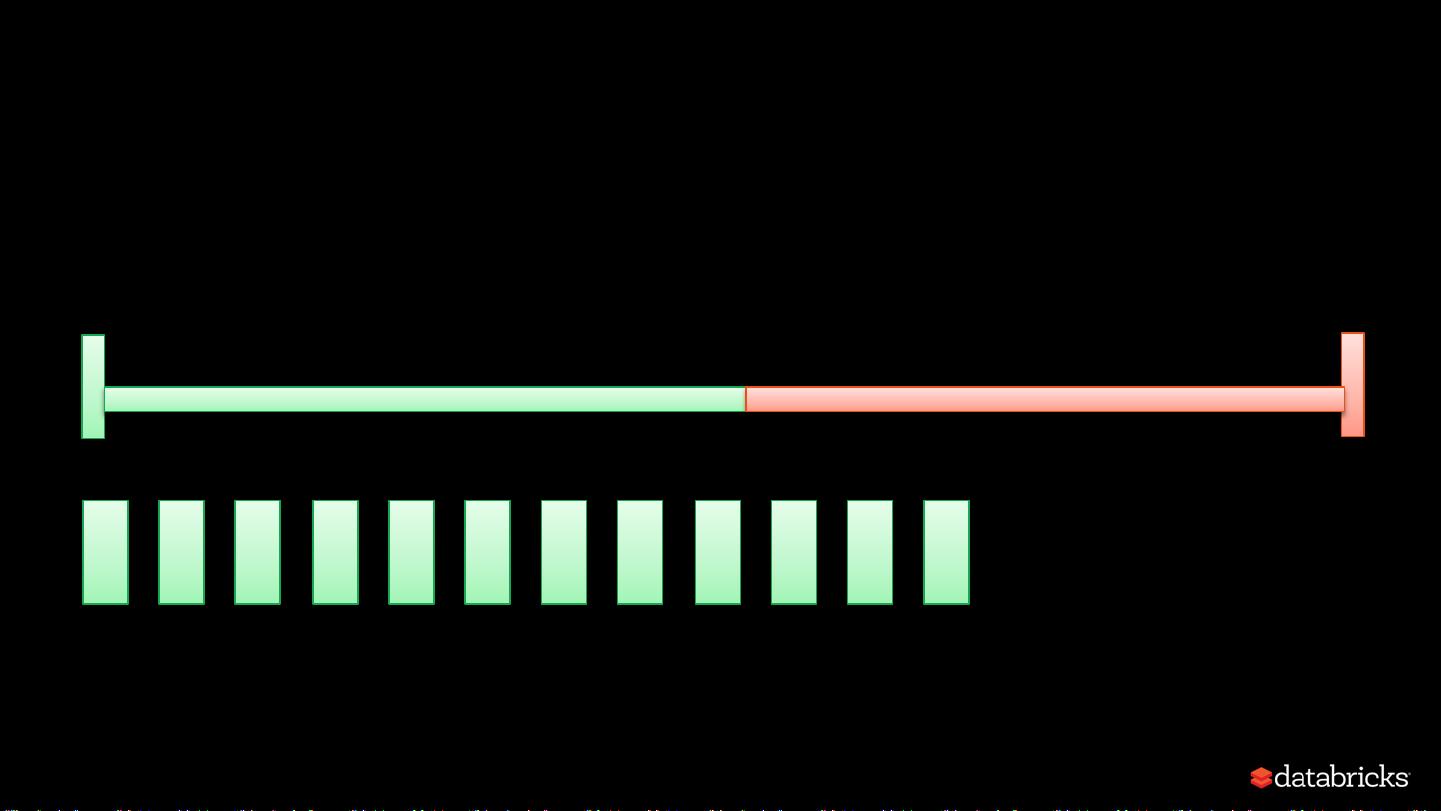
在并行处理过程中,内存内容竞争是个挑战。Spark需要解决如何在执行和存储内存之间,以及在不同任务或同一任务内运行的不同操作符之间公平地分配资源。这涉及到内存的动态调整和优化策略,以避免瓶颈并最大化整体系统效率。
3. **Tungsten内存格式**
Tungsten是Spark的下一代内存管理技术,它旨在减少跨节点通信,提高内存局部性。通过将对象直接存储在任务上下文中,Tungsten减少了垃圾回收开销,并使得数据传输更有效率。
4. **缓存感知计算**
Cache-aware computation是Spark的一种优化,它根据数据的重复访问频率来决定是否将其存储在内存中。这样可以减少磁盘I/O,提高数据读取速度,从而提升整体性能。
5. **未来计划**
Spark团队持续关注内存管理的改进。未来的计划可能包括更智能的内存分配算法、内存泄漏检测和修复机制,以及对内存使用情况的可视化工具,以帮助开发者更好地理解和优化内存使用。
在实际应用中,例如在处理迭代操作(如`take`操作)和排序操作时,Spark会重复使用内存中的数据,以便在需要时快速获取已排序的结果。然而,当再次需要排序时,即使数据已经在内存中,也可能因为内存竞争导致重新排序,这就展示了内存管理在性能优化中的复杂性和动态性。
理解Spark如何管理和优化内存使用对于充分利用其分布式计算能力至关重要。通过掌握内存的布局、分配策略以及内存竞争的解决方案,开发人员能够编写出更加高效的Spark应用程序。随着技术的不断发展,对内存管理的深入研究将继续推动Spark性能的提升。

2023-08-25 上传
2023-08-28 上传
2018-06-11 上传
2023-09-09 上传
2020-06-08 上传
2022-04-23 上传
2021-07-11 上传
2023-09-02 上传
2021-05-28 上传

xiaoj08
- 粉丝: 1
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
