斯坦福CS229机器学习完整笔记pdf版
需积分: 9 46 浏览量
更新于2024-07-19
1
收藏 7.52MB PDF 举报
"斯坦福学习笔记CS229是一份详细的英文PDF文档,由著名教授Andrew Ng讲解的机器学习课程的完整解读。这份笔记源自2011年秋季ml-class.org网站上的原始课程资料,涵盖了课程的所有核心内容,包括但不限于监督学习、无监督学习、神经网络、支持向量机、集成学习等主题。笔记作者原本是为了个人学习而编写,随着时间的推移,它已经发展成为一个包含超过40,000字和众多图表的全面参考材料,适用于对编程有一定基础,但不假设读者具备统计学、微积分或线性代数背景的学习者。
笔记的特点是所有的解释和概念阐述深入浅出,所有图表都是作者根据讲座内容绘制或者直接引用,充分展示了Ng教授的精彩教学。此外,虽然原课程涉及Octave/MATLAB编程部分在这些笔记中并未包含,但对于希望深入理解机器学习理论的人来说,这是一份极其宝贵的资源。
由于其详尽的内容和易懂的语言,这份笔记不仅适合那些正在上斯坦福CS229课程的学生,也对希望自学机器学习或者作为教师的教学辅助材料非常有用。通过阅读这份笔记,读者能够系统地掌握机器学习的基本原理和实践技巧,是提升机器学习能力不可多得的参考资料。"
17_Large_Scale_Machine_Learning
file:///C|/Users/fencer/Desktop/Machine_learning_complete/17_Large_Scale_Machine_Learning.html[2017/11/1 21:03:12]
For many learning algorithms, we derived them by coming up with an optimization objective (cost
function) and using an algorithm to minimize that cost function
When you have a large dataset, gradient descent becomes very expensive
So here we'll define a different way to optimize for large data sets which will allow us to scale the
algorithms
Suppose you're training a linear regression model with gradient descent
Hypothesis
Cost function
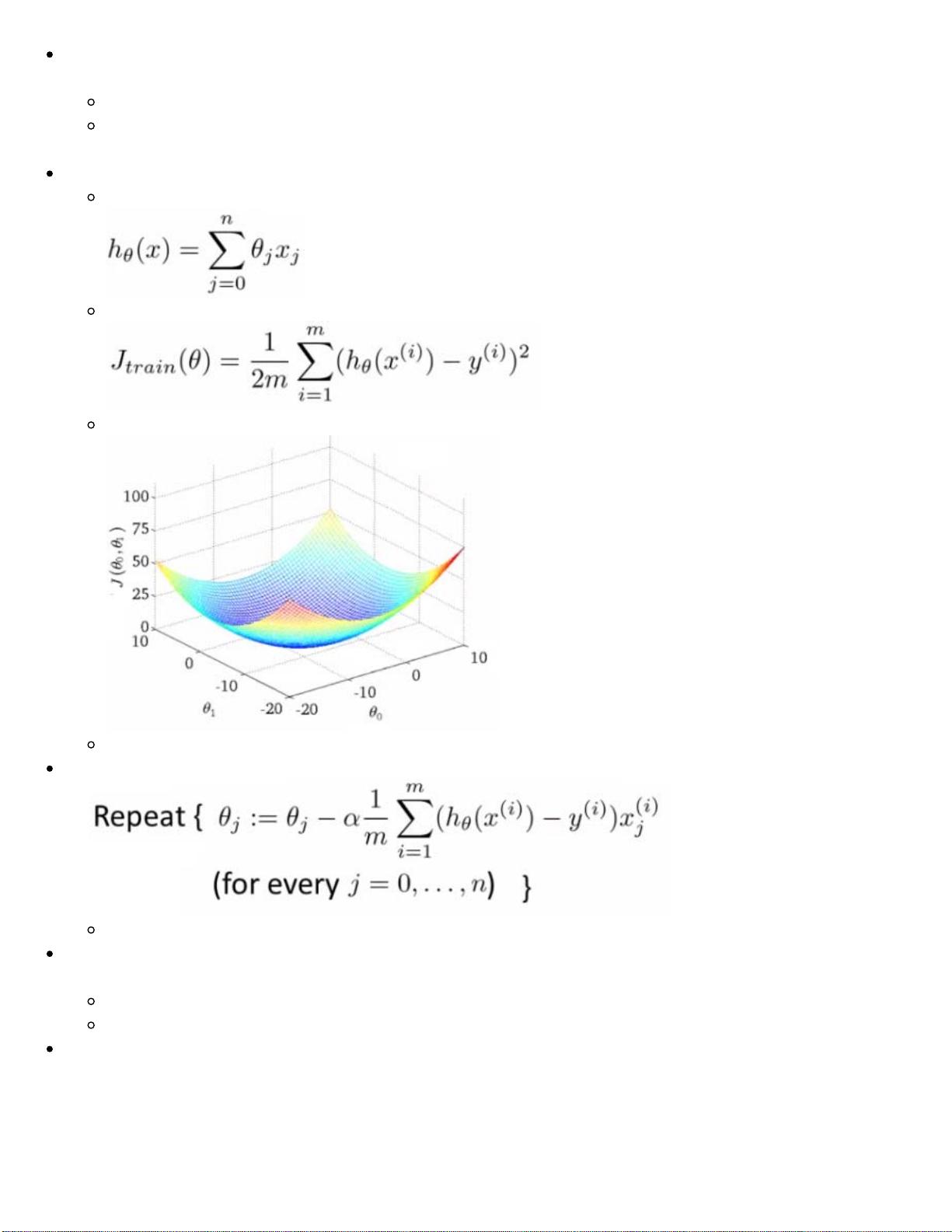
If we plot our two parameters vs. the cost function we get something like this
Looks like this bowl shape surface plot
Quick reminder - how does gradient descent work?
In the inner loop we repeatedly update the parameters θ
We will use linear regression for our algorithmic example here when talking
about stochastic gradient descent, although the ideas apply to other algorithms too, such as
Logistic regression
Neural networks
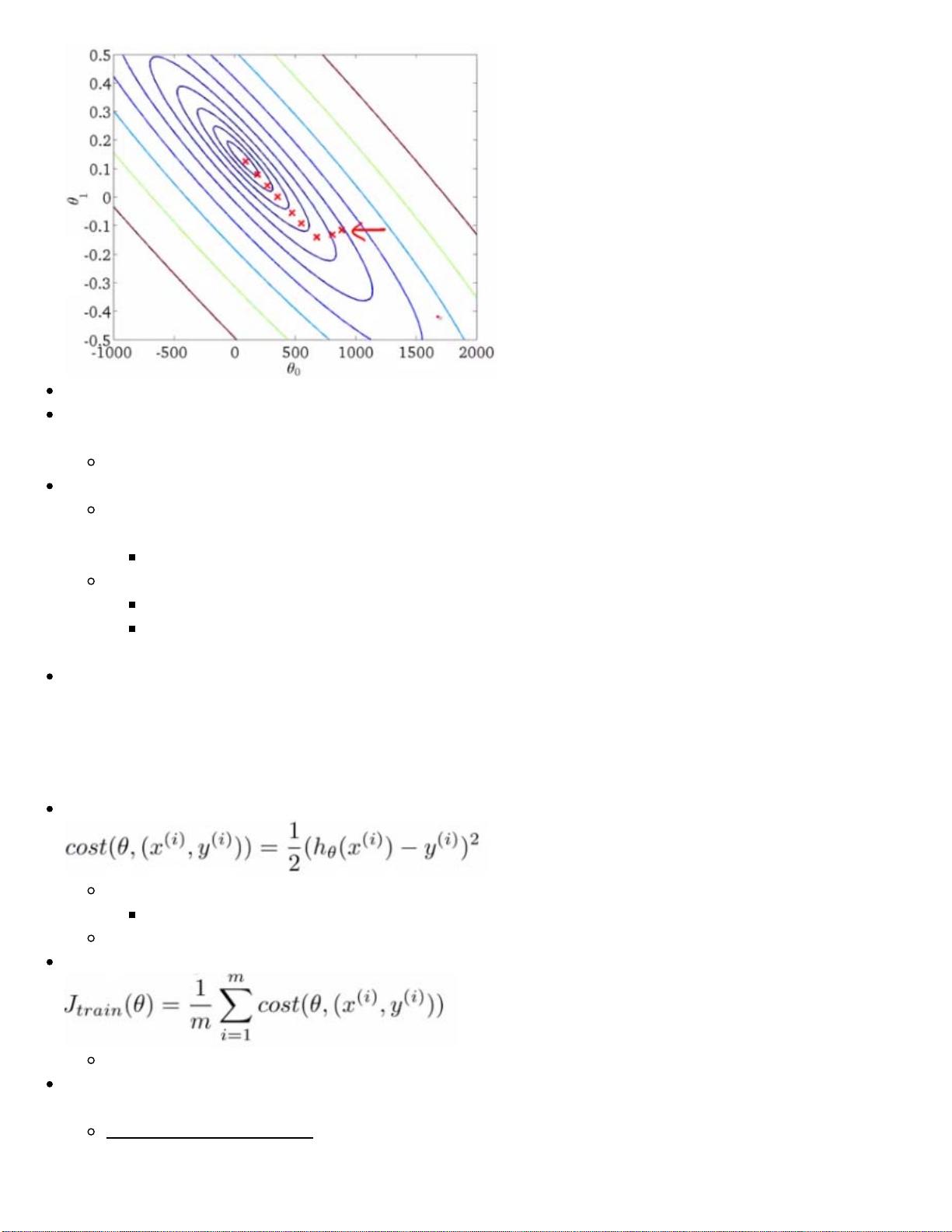
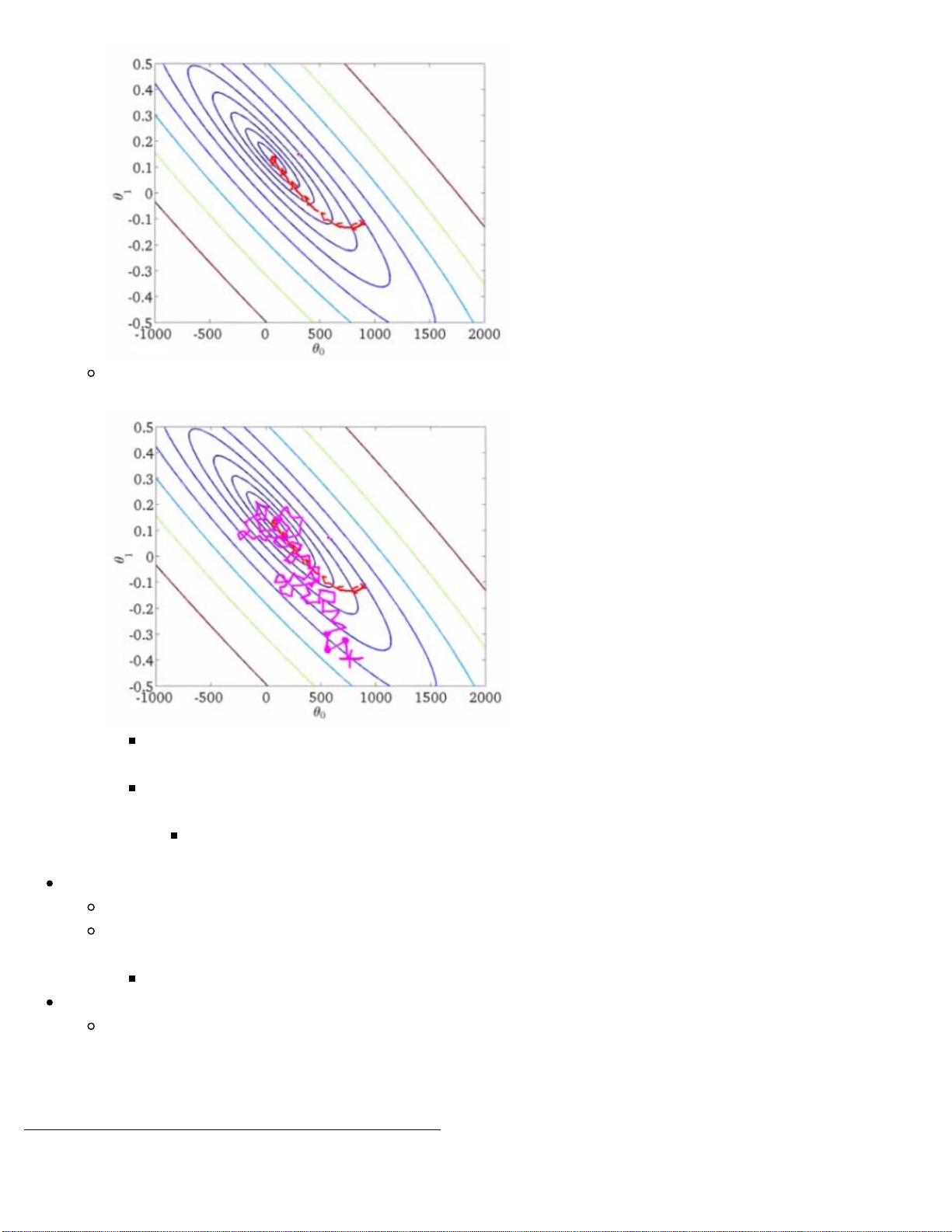
Below we have a contour plot for gradient descent showing iteration to a global minimum


剩余212页未读,继续阅读
401 浏览量
171 浏览量
2024-08-06 上传
108 浏览量

开发老牛
- 粉丝: 37
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- 软件水平考试网络工程师英语复习练习题10套
- JAVA面试题目大汇总
- 门禁系统设计 论文 完整版
- soa相关技术介绍与实现
- a Frame Layout Framework
- Thinking in Patterns
- 图书管理信息系统 SIM SQL Server2000数据库管理系统
- Bayesian and Markov chain
- Analysis of a Denial of Service Attack on TCP.
- 802.11英文原版协议 11G 11 N WEP WPA WPA2 BEACON 好东西大家分享
- aix双机配置详细配置
- 中国联通SGIP1.2
- 09数据库系统工程师考试大纲
- DFBlaser窄线宽激光器
- WinSock编程基础原理与C实现代码
- bfin-uclinux内核的CPLB v0.1
