
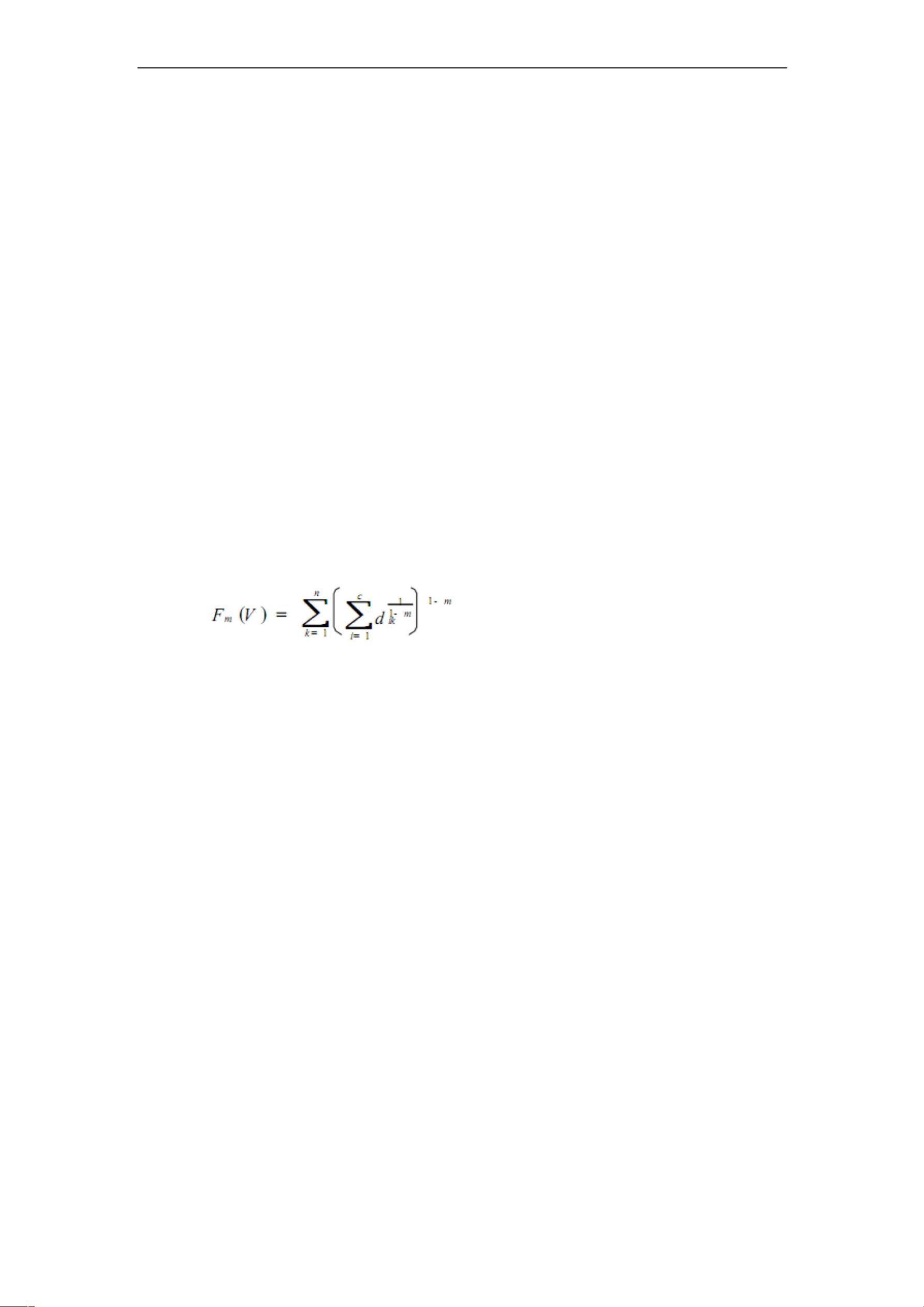
.
(1) 种群中个体的确定
聚类的关键问题是聚类中心的确定,因此可以选取聚类中心作为种
群的个体,由于共有 C 个聚类中心,而每个聚类中心是一个 S 维的实数
向量,因此每个个体的初始值是一个 c*s 维的市属向量。
(2) 编码
常用的编码方式有二进制与实数编码,由于二进制编码的方式搜索
能力最强,且交叉变异操作简单高效,因此采用二进制的编码方式,同
时防止在进行交叉操作时对优良个体造成较大的破坏,在二进制编码的
方式中采用格雷码的编码形式。
每个染色体含 c*s 个基因链,每个基因链代表一维的数据,由于原
始数据中各个属性的取值可能相差很大,因此需首先对数据进行交换以
统一基因链的长度,可以有以下两种变换方式。
1 扫描整个数据集,确定每维数据的取值范围,然后将其变换到同
一量级,在保留一定有效位的基础上取整,根据有效位的个数动态的计
算出基因链的长度。
2 对数据进行正规化处理,即将各维数据都变换到相同的区间,可
以算出此时的基因链长度为 10。
(3) 适应度函数
由于在算法中只使用了聚类中心 V,而未使用虑属矩阵 u,因此需要
对 FCM 聚 类 算 法 的 目 标 函 数 进 行 改 进 , 以 适 用 算 法 的 要 求 ,
和目标函数是等价的,由于遗传算法的
适用度一般取值极大,因此可取上式的倒数作为算法的使用度函数。
(4) 初始种群的确定
初始种群的一般个体由通过采样后运行 FCM 算法得到的结果给出,
另外的一般个体通过随机指定的方法给出,这样既保证了遗传算法在运
算之初就利用背景知识对初始群体的个体进行了优化,使算法能在一个
较好的基础上进行,又使得个体不至于过分集中在某一取值空间,保证
了种群的多样性。
(5) 遗传操作
选择操作采用保持最优的锦标赛法,锦标赛规模为 2,即每次随机取
2 个个体,比较其适应度,较大的作为父个体,并保留每代的最优个体
作为下一代,交叉方式一般采用单点交叉或多点交叉法进行,经过试验
表明单点交叉效果较好,因此采用单点交叉法,同时在交叉操作中,应
该对每维数据分开进行,以保证较大的搜索空间和结果的有效性,变异
操作采用基本位变异法。
(6) 终止条件的确定
遗传算法在以下二种情况下终止
a 最佳个体保持不变的代数达到设定的阈值
b 遗传操作以到达给定的最大世代数
算法具体步骤如下
1 确定参数,如聚类个数 样本集大小 种群规模 最大世代数 交叉概率
和变异概率等。
-.
剩余20页未读,继续阅读

apple_51426592
- 粉丝: 9697
- 资源: 9657
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- 构建智慧路灯大数据平台:物联网与节能解决方案
- 智慧开发区建设:探索创新解决方案
- SQL查询实践:员工、商品与销售数据分析
- 2022智慧酒店解决方案:提升服务效率与体验
- 2022年智慧景区信息化整体解决方案:打造数字化旅游新时代
- 2022智慧景区建设:大数据驱动的5A级管理与服务升级
- 2022智慧教育综合方案:迈向2.0时代的创新路径与实施策略
- 2022智慧教育:构建区域教育云,赋能学习新时代
- 2022智慧教室解决方案:融合技术提升教学新时代
- 构建智慧机场:2022年全面信息化解决方案
- 2022智慧机场建设:大数据与物联网引领的生态转型与客户体验升级
- 智慧机场2022安防解决方案:打造高效指挥与全面监控系统
- 2022智慧化工园区一体化管理与运营解决方案
- 2022智慧河长管理系统:科技助力水环境治理
- 伪随机相位编码雷达仿真及FFT增益分析
- 2022智慧管廊建设:工业化与智能化解决方案
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


