程序员视角:MySQL底层原理与性能优化
25 浏览量
更新于2024-08-27
收藏 311KB PDF 举报
"《从程序员的角度深入理解MySQL》这篇文章主要探讨了数据库的基本原理,特别是从程序员的视角出发,解析了MySQL的工作机制。首先,文章强调了数据库的核心组成部分——存储和实例。存储用于持久化数据,而实例则是对存储操作的抽象,提供了面向应用程序的增删改查接口,增强了系统的负载能力和可用性。通过多实例部署,数据库可以在不同地理位置的服务器间实现数据冗余和灾难恢复。
其次,作者解释了数据库不是按行读取数据,而是基于固定大小的物理块(Block或Page)进行管理和调度。每个Block对应数据库中的一个逻辑区域,通过查找Block地址来实现高效的数据访问。数据库会预加载相邻的Block以减少磁盘I/O,提高数据访问速度和命中率。
磁盘I/O是数据库性能的关键瓶颈,因为与内存读取相比,它的时间消耗显著。为提升性能,文章提到了几种策略,如增加内存容量以缓存数据、利用索引优化查询效率、以及选择性能更好的硬件设备。这些策略有助于减少磁盘I/O次数,降低延迟。
文章还提出了两个问题供读者思考:一是为什么删除表数据时,`DELETE` 操作通常比 `TRUNCATE` 慢,这是因为`DELETE`逐行处理,而`TRUNCATE` 是基于Block操作,效率更高。二是提倡“小表驱动大表”的理念,这是因为小表的处理更快,可以在查询时作为聚集点,驱动大表的并行处理,从而提高整体性能。
本文深入剖析了MySQL的内部工作机制,帮助程序员更好地理解和优化数据库性能,尤其是在面临性能瓶颈和设计决策时。"
从程序员的角度深入理解从程序员的角度深入理解MySQL
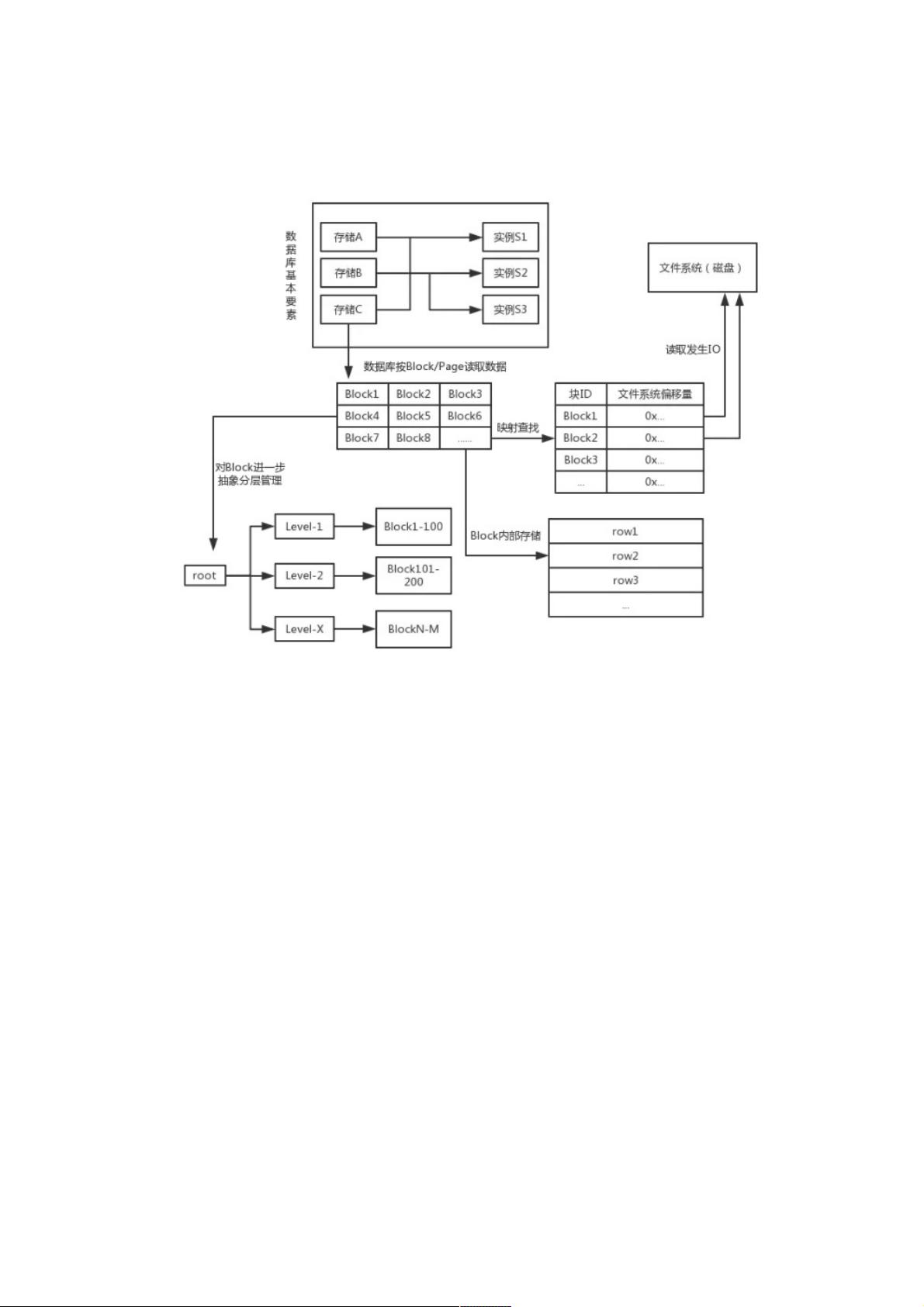
数据库基本原理
我对DB的理解
第一,数据库的组成:存储 + 实例
不必多说,数据当然需要存储;存储了还不够,显然需要提供程序对存储的操作进行封装,对外提供增删改查的API,即实
例。
一个存储,可以对应多个实例,这将提高这个存储的负载能力以及高可用;多个存储可以分布在不同的机房、地域,将实现容
灾。
第二,按Block or Page读取数据
用大腿想也知道,数据库不可能按行读取数据(Why? ? ^_^)。实质上,数据库,如Oracle/MySQL,都是基于固定大小(比
如16K)的物理块(Block or Page,我这里就不区分统一称为Block)来实现调度和管理的。要知道Block是数据库的概念,如
何对应到文件系统呢?显然需要指出“这个Block的地址在哪里”,当查找到地址后,读取固定大小的数据就相当于完成了Block
的读取了。
数据库很聪明的,它不会仅仅只读取需要读取的Block,它还会替我们把附近的Block块都读取加载至内存。实际上,这是为了
减少IO次数,提高命中率。事实上,一个Block块的附近Block也是热点数据,这种处理方式很有必要!
第三,磁盘IO是数据库的性能瓶颈
毫无疑问,数据在磁盘上,少不了磁盘IO。什么磁头旋转,定位磁道,寻址的过程,就不说了,我们是程序员,也管不了这
些。但是这个过程确实是非常耗时的,和内存读取不是一个数量级,所以后来出现了很多方式来减少IO,提升数据库性能。
比如,增加内存,让数据库把数据更多的加载至内存。内存虽好,但也不能滥用,为什么这么说呢?假设数据库中有100G数
据,如果都加载至内存,也就说数据库要管理100G磁盘数据+100G内存数据,你说累不累?(数据库要处理磁盘和内存的映
射关系,数据的同步,还要对内存数据进行清理,如果涉及数据库事务,又是一系列复杂操作......)不过这里需要指出的是,
为了加快内存查找速度,数据库一般对内存进行HASH存放。
比如,利用索引,索引相比内存,是一个性价比非常高的东西,后文详细介绍MySQL的索引原理。
比如,利用性能更好的磁盘...(和咱们就没关系呢)
第四,提出一些问题思考下:
下载后可阅读完整内容,剩余3页未读,立即下载
2011-07-11 上传
点击了解资源详情
2018-03-24 上传
2016-03-17 上传
2020-10-27 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38641876
- 粉丝: 3
- 资源: 942
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
