协同过滤算法在电影推荐系统的应用
版权申诉
176 浏览量
更新于2024-07-03
收藏 833KB DOCX 举报
"基于协同过滤算法的电影推荐系统利用Apache Mahout的Taste库,实现了一个高效的推荐引擎,该系统基于用户评分数据,通过计算用户相似度和寻找邻居用户来生成个性化的电影推荐。"
在电影推荐系统中,协同过滤算法是一种广泛应用的方法,尤其在处理大量用户和项目的数据时。这种算法不依赖于内容分析,而是通过分析用户的行为和偏好,找出具有相似兴趣的用户群体,然后基于这些相似用户的喜好来预测目标用户可能感兴趣的项目。在这个案例中,系统采用了Apache Mahout的Taste框架,这是一个用Java编写的、高度可扩展的推荐引擎,支持多种推荐算法,包括基于用户和基于内容的推荐,以及SlopeOne等更高效的方法。
Taste框架的灵活性在于,它不仅可以在Java应用中使用,还可以作为一个内嵌服务器组件,通过HTTP和Web服务接口对外提供推荐服务。其核心组件包括:
1. DataModel:这是数据模型,存储用户对电影的评分数据,是推荐系统的基础。
2. UserSimilarity:该组件负责计算用户之间的相似度,常用的方法有皮尔逊相关系数、余弦相似度等。
3. UserNeighborhood:用户邻域是指根据相似度找到与目标用户相近的一组用户,它们的喜好可以作为推荐的参考。
4. Recommender:推荐器是整个系统的输出部分,它综合用户相似度和邻域信息,为特定用户生成推荐列表。
5. Evaluation:评估模块用于衡量推荐效果,例如通过离线评估方法如Precision、Recall和F1值,或者在线A/B测试。
协同过滤算法在电影推荐中的具体流程如下:
1. 收集用户对电影的评分数据。
2. 计算用户之间的相似度,形成用户相似度矩阵。
3. 根据相似度确定与目标用户最相似的邻近用户集合。
4. 对于未评分的电影,预测目标用户可能的评分,通常是通过平均邻近用户对电影的评分。
5. 根据预测评分生成推荐列表,评分高的电影优先推荐。
此外,Taste还支持MapReduce编程模型,这意味着它可以利用Hadoop的分布式计算能力,处理大规模数据集,提高推荐算法的计算效率。
这个基于协同过滤算法的电影推荐系统利用了先进的数据挖掘技术和机器学习方法,旨在为用户提供个性化且精准的电影推荐,提升用户体验。同时,其设计考虑到了性能、灵活性和可扩展性,适应了大数据时代的需求。
WORD 格式可编辑
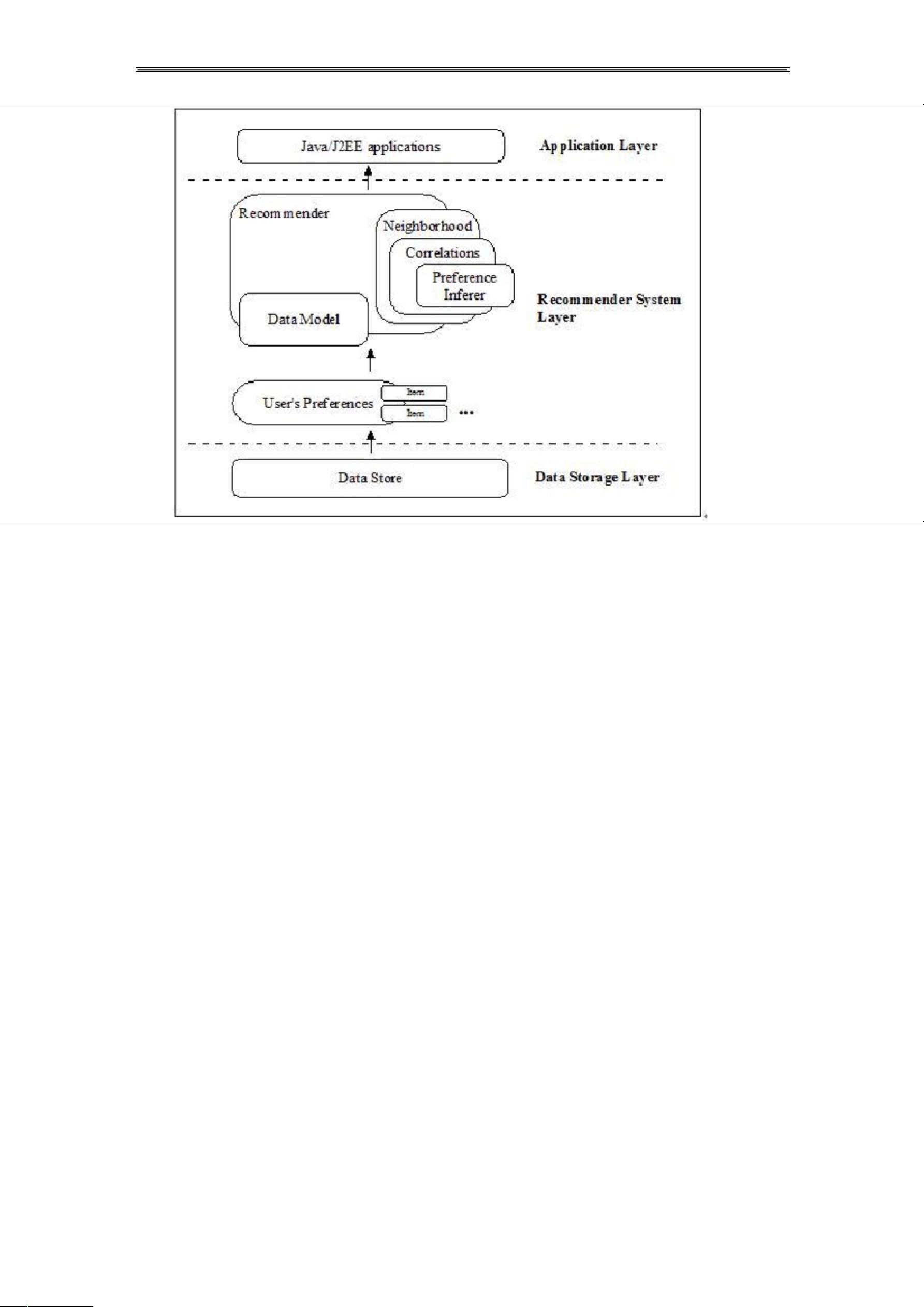
从上图可见,Taste 由以下几个主要组件组成:
DataModel:DataModel 是用户喜好信息的抽象接口,它的具体实现支持从指
定 类 型 的 数 据 源 抽 取 用 户 喜 好 信 息 。 在 Mahout0.5 中 , Taste 提 供
JDBCDataModel 和 FileDataModel 两种类的实现,分别支持从数据库和文件文
件系统中读取用户的喜好信息。对于数据库的读取支持,在 Mahout 0.5 中只提
供了对 MySQL 和 PostgreSQL 的支持,如果数据存储在其他数据库,或者是把数
据导入到这两个数据库中,或者是自行编程实现相应的类。
UserSimilarit 和 ItemSimilarity:前者用于定义两个用户间的相似度,后
者用于定义两个项目之间的相似度。Mahout 支持大部分驻留的相似度或相关度
计算方法,针对不同的数据源,需要合理选择相似度计算方法。
UserNeighborhood:在基于用户的推荐方法中,推荐的内容是基于找到与当
前用户喜好相似的“邻居用户”的方式产生的,该组件就是用来定义与目标用户
相邻的“邻居用户”。所以,该组件只有在基于用户的推荐算法中才会被使用。
Recommender:Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。
利用该组件就可以为指定用户生成项目推荐列表。
专业知识分享
剩余14页未读,继续阅读
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-05-30 上传
2022-06-09 上传
2022-05-30 上传
2022-05-30 上传

苦茶子12138
- 粉丝: 1w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
