知识图谱:表示、获取与应用的全面综述
需积分: 36 40 浏览量
更新于2024-07-15
收藏 1.99MB PDF 举报
本文是一篇深入探讨知识图谱的综合调查报告,"A Survey on Knowledge Graphs: Representation, Acquisition, and Applications"。作者Shaoxiong Ji、Shirui Pan、Erik Cambria(IEEE资深会员)和Pekka Marttinen、Philip S. Yu(IEEE生命院士)共同研究了这一领域在认知和人类级别智能方面的重要性。知识图谱作为一种结构化的实体间关系表示方式,近年来已经成为研究热点。
报告首先关注知识图谱的四个核心主题:1)知识图谱表示学习,即如何将复杂的信息结构转化为易于理解和处理的形式,包括嵌入方法、空间组织、评分函数和辅助信息的优化;2)知识获取与完成,涉及如何从大规模数据中提取和补充知识,这包括基于嵌入的方法、路径推断以及逻辑规则的应用;3)时间知识图谱,强调动态变化和时间依赖性知识的建模和管理;4)知识驱动的应用,展示了知识图谱如何在推荐系统、搜索引擎优化、自然语言处理等实际场景中发挥关键作用。
文章详细梳理了每个主题下的最新进展和突破,提供了对现有技术的深入剖析,并提出了对未来研究的前瞻性和可能的研究方向。为了更好地组织和理解这些内容,报告构建了一个全面的分类体系和新的分类框架,使得读者能够清晰地追踪各个子领域的研究脉络和发展趋势。
这篇论文不仅概述了知识图谱的基础理论和技术,还揭示了其在推动人工智能进步中的关键角色,为研究人员、开发者和实践者提供了一个宝贵的参考资源,以促进知识图谱在不同领域的创新应用。通过阅读这份报告,读者可以深入了解知识图谱的现状、挑战和未来发展,为自己的研究或工作选择合适的技术路线。
5
r 2 R
d
M
r
2 R
d⇥d
c
M
r
2 R
d⇥d⇥k
(a) Point-wise space.
Im(u)
u = a + bi
b 2 R
d
a 2 R
d
u 2 C
d
Re(u)
(b) Complex vector space.
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
−2
−1.5
−1
−0.5
0
0.5
1
1.5
2
0
0.2
0.4
P (x
1
)
P (x
2
)
x
1
x
2
P
0
0.1
0.2
0.3
P (x
1
, x
2
)
(c) Gaussian distribution.
0
(Face, HasInstance, *)
0
(Clock, HasPart, *)
0
Clock Dial
(d) Manifold space.
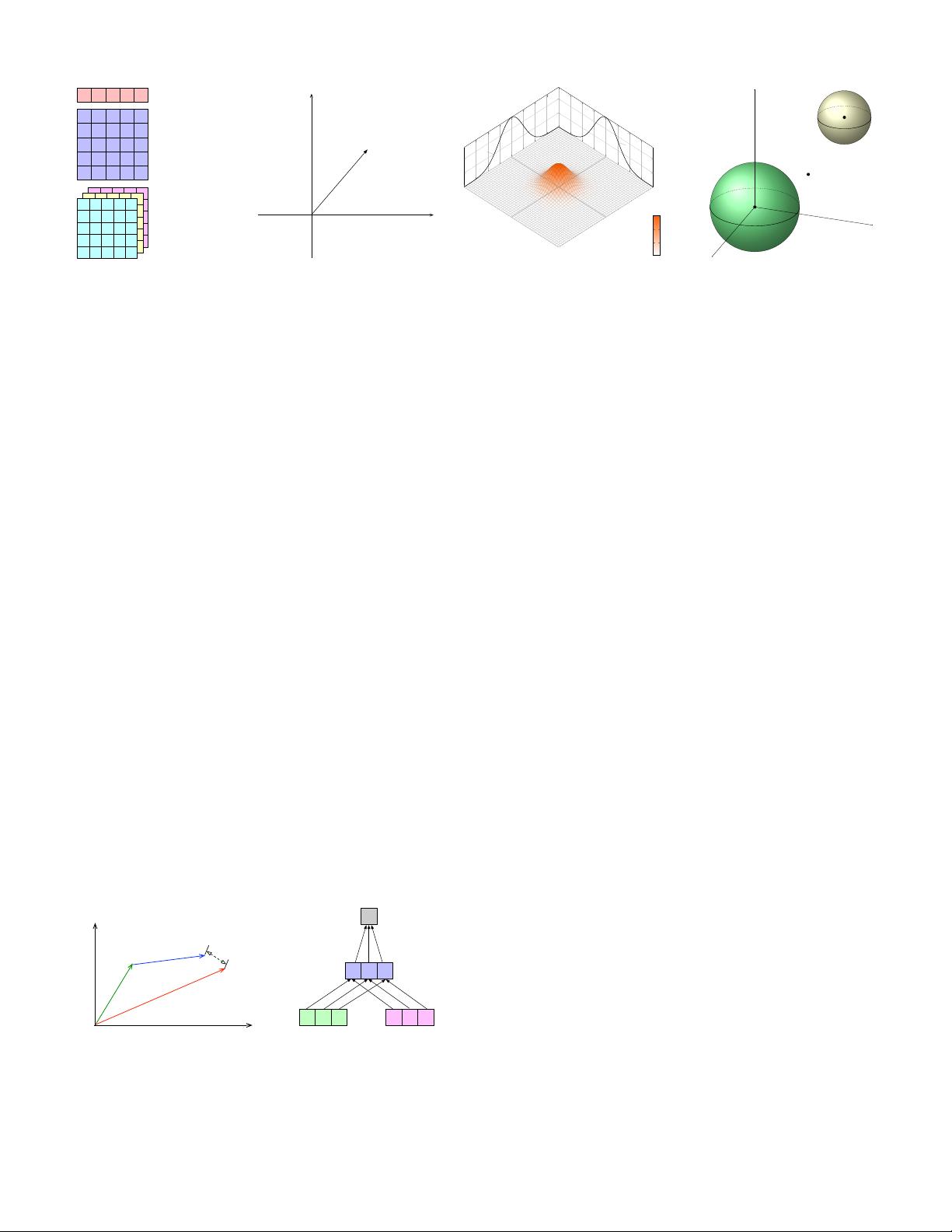
Fig. 4: An illustration of knowledge representation in different spaces.
al. [29] leverages expressive hyperbolic isometries and learns a
relation-specific absolute curvature
c
r
in the hyperbolic space.
TorusE [30] solves the regularization problem of TransE via
embedding in an n-dimensional torus space which is a compact
Lie group. With the projection from vector space into torus
space defined as
π : R
n
→ T
n
, x 7→ [x]
, entities and relations
are denoted as
[h], [r], [t] ∈ T
n
. Similar to TransE, it also
learns embeddings following the relational translation in torus
space, i.e.,
[h] + [r] ≈ [t]
. Recently, DihEdral [31] proposes a
dihedral symmetry group preserving a 2-dimensional polygon.
B. Scoring Function
The scoring function is used to measure the plausibility of
facts, also referred to as the energy function in the energy-
based learning framework. Energy-based learning aims to learn
the energy function
E
θ
(x)
(parameterized by
θ
taking
x
as
input) and to make sure positive samples have higher scores
than negative samples. In this paper, the term of the scoring
function is adopted for unification. There are two typical types
of scoring functions, i.e., distance-based (Fig. 5a) and similarity-
based (Fig. 5b) functions, to measure the plausibility of a
fact. Distance-based scoring function measures the plausibility
of facts by calculating the distance between entities, where
addictive translation with relations as
h + r ≈ t
is widely used.
Semantic similarity based scoring measures the plausibility of
facts by semantic matching. It usually adopts multiplicative
formulation, i.e.,
h
>
M
r
≈ t
>
, to transform head entity near
the tail in the representation space.
h
t
r
distance
(a) Translational distance-
based scoring of TransE.
h t
r
f
r
(h, r)
(b) Semantic similarity-based
scoring of DistMult.
Fig. 5: Illustrations of distance-based and similarity matching
based scoring functions taking TransE [15] and DistMult [32]
as examples.
1) Distance-based Scoring Function: An intuitive distance-
based approach is to calculate the Euclidean distance between
the relational projection of entities. Structural Embedding
(SE) [8] uses two projection matrices and
L
1
distance to learn
structural embedding as
f
r
(h, t) = kM
r,1
h − M
r,2
tk
L
1
. (3)
A more intensively used principle is the translation-based
scoring function that aims to learn embeddings by representing
relations as translations from head to tail entities. Bordes et
al. [15] proposed TransE by assuming that the added embedding
of
h + r
should be close to the embedding of
t
with the scoring
function is defined under L
1
or L
2
constraints as
f
r
(h, t) = kh + r − tk
L
1
/L
2
. (4)
Since that, many variants and extensions of TransE have been
proposed. For example, TransH [19] projects entities and
relations into a hyperplane, TransR [16] introduces separate
projection spaces for entities and relations, and TransD [33]
constructs dynamic mapping matrices
M
rh
= r
p
h
>
p
+ I
and
M
rt
= r
p
t
>
p
+ I
by the projection vectors
h
p
, t
p
, r
p
∈ R
n
. By
replacing Euclidean distance, TransA [34] uses Mahalanobis
distance to enable more adaptive metric learning. Previous
methods used additive score functions, TransF [35] relaxes the
strict translation and uses dot product as
f
r
(h, t) = (h + r)
>
t
.
To balance the constraints on head and tail, a flexible translation
scoring function is further proposed.
Recently, ITransF [36] enables hidden concepts discovery
and statistical strength transferring by learning associations
between relations and concepts via sparse attention vectors,
with scoring function defined as
f
r
(h, t) =
α
H
r
· D · h + r − α
T
r
· D · t
`
, (5)
where
D ∈ R
n×d×d
is stacked concept projection matrices
of entities and relations and
α
H
r
, α
T
r
∈ [0, 1]
n
are attention
vectors calculated by sparse softmax, TransAt [37] integrates
relation attention mechanism with translational embedding,
and TransMS [38] transmits multi-directional semantics with
nonlinear functions and linear bias vectors, with the scoring
function as
f
r
(h, t) = k−tanh(t◦r)◦h+r−tanh(h◦r)◦t+α·(h◦t)k
`
1/2
. (6)
KG2E [25] in Gaussian space and ManifoldE [27] with
manifold also use the translational distance-based scoring

剩余25页未读,继续阅读
2020-02-17 上传
2019-08-16 上传
2019-08-26 上传
2023-10-13 上传
2023-03-16 上传
2023-05-22 上传
2023-10-16 上传
2023-03-20 上传
2023-06-09 上传
2023-07-12 上传

wilosny518
- 粉丝: 0
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
