Spark应用详解:Driver、Executor与RDD关键原理
版权申诉
42 浏览量
更新于2024-07-21
收藏 1.7MB DOCX 举报
"Spark原理详解"
Spark是一个开源的大规模数据处理框架,以其高效、易用和容错性著称。本文将深入解析Spark的核心原理,包括其关键组件和工作流程。
首先,我们来理解Spark中的核心概念。Spark的核心组件主要包括以下几个方面:
1. **Application/App(Spark应用程序)**:Spark应用程序是用户编写的代码,它由一个或多个作业(Job)构成,这些作业通常通过调用Action来完成数据处理。Driver是应用程序的起点,运行用户提供的Main()函数并创建SparkContext,这个上下文负责初始化运行环境并与资源管理器交互。
2. **Driver(驱动程序)**:Driver是应用程序的核心,它负责启动、管理和调度任务。SparkContext在此过程中起到至关重要的作用,它负责与ClusterManager(如Standalone、YARN或Mesos)进行通信,请求资源,分配任务,并监控执行过程。在任务完成后,Driver会关闭SparkContext。
3. **ClusterManager(资源管理器)**:这是外部服务,负责在集群上管理和分配资源。Standalone是Spark自带的简单资源管理器,而Hadoop YARN和Mesos则是更高级别的资源调度平台,它们分别由各自的资源管理者(如YARN的ResourceManager或Mesos的MesosMaster)负责。
4. **Worker(计算节点)**:在集群中,Worker是执行实际计算的节点。在Standalone模式下,Worker通过配置文件指定;而在Spark on YARN或Mesos模式中,Worker可能对应于YARN的NodeManager或Mesos的MesosSlave。
5. **Executor(执行器)**:Executor是运行在Worker节点上的进程,负责执行由Driver分发的任务。每个Spark应用程序有一组独立的Executor实例,它们共同协作完成任务的计算和数据处理。
6. **RDD(弹性分布式数据集)**:RDD是Spark的基本计算单元,它是Resilient Distributed Dataset的缩写。RDD是一种容错的数据结构,支持各种变换(Transformation)操作,如map、filter、reduce等,以及最终的Action操作,用于将结果返回到Driver。
7. **Narrow Dependency(窄依赖)**:这是RDD之间的一种依赖关系,表示子RDD的分区只依赖于父RDD的单一分区。这种依赖关系使得Spark能够进行更高效的优化,避免全数据重新分区。
Spark的工作流程通常包括:Driver启动时创建SparkContext,然后根据需求提交Job,Job会被拆分成多个Task,这些Task通过Executor在Worker节点上执行,最后Driver接收和处理Action的结果。在整个过程中,Spark利用其强大的内存计算能力和容错机制,提供了快速、灵活的大规模数据处理能力。理解这些核心概念对于深入学习和使用Spark至关重要。
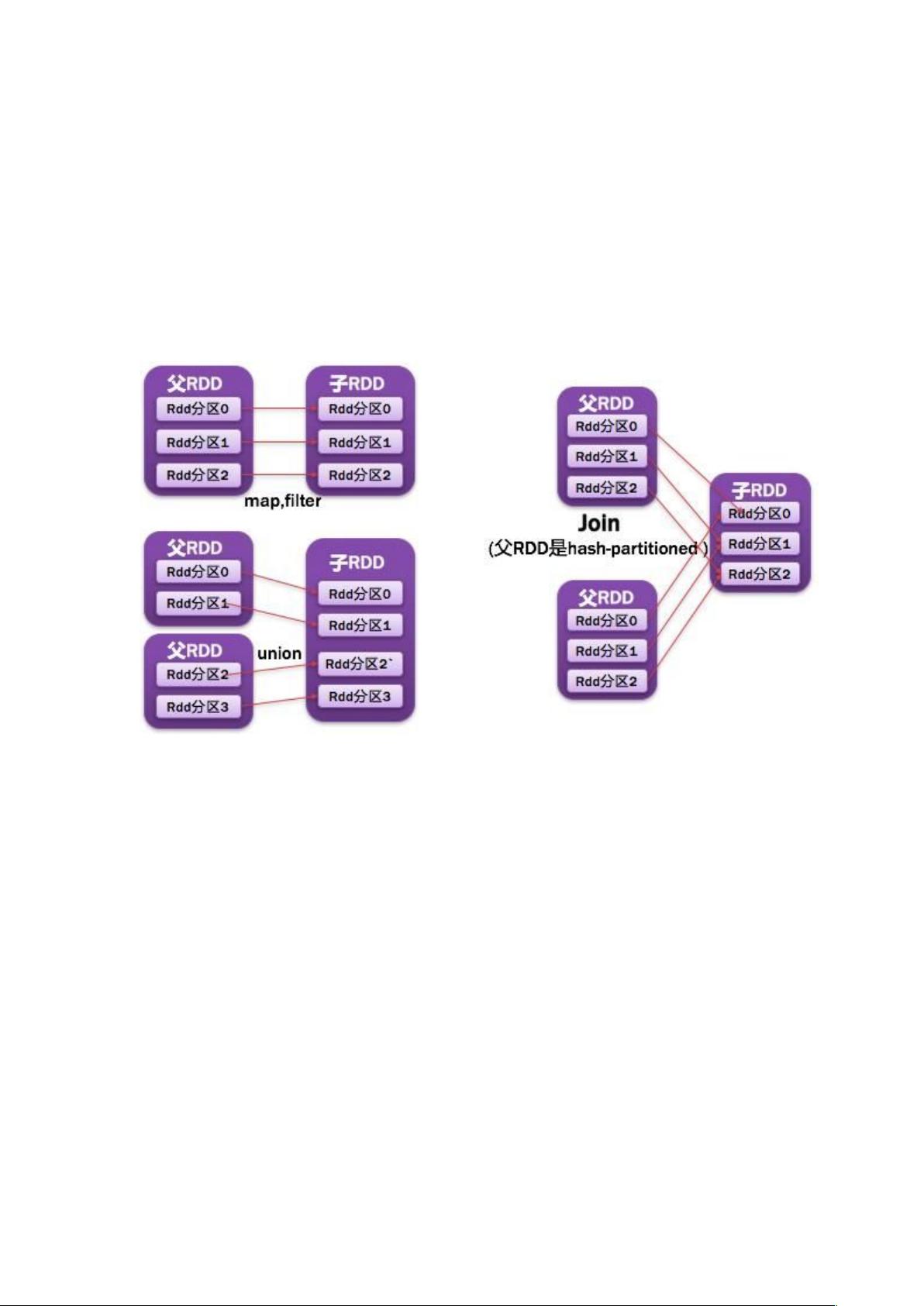
一.1.7. NarrowDependency 窄依赖
父 RDD 一个分区被子 RDD 的一个分区所依赖;
如图所示:
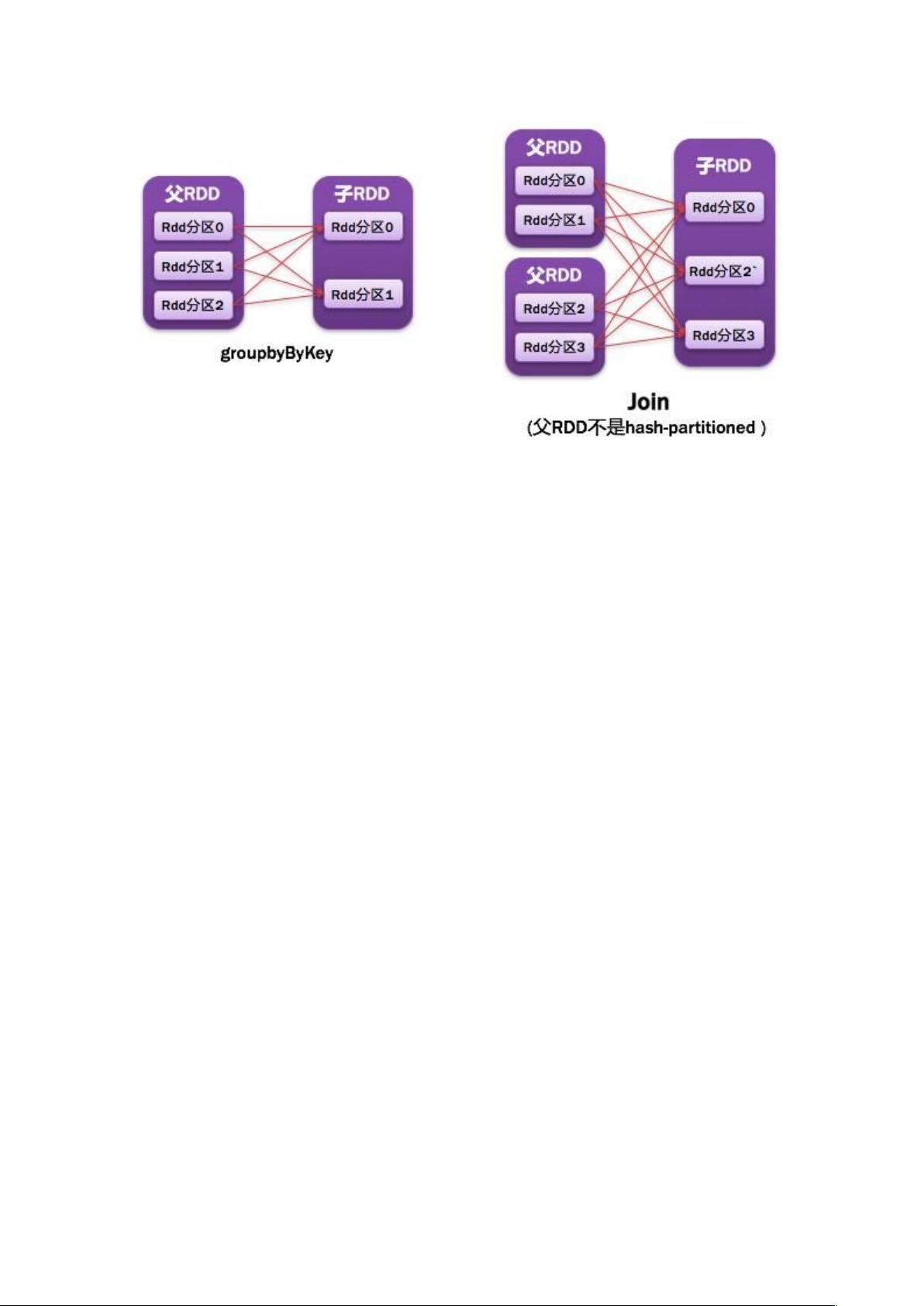
一.1.8. Shu,eDependency 宽依赖
父 RDD 的一个分区都被子 RDD 多个分区所使用/依赖
如图所示:
剩余31页未读,继续阅读
124 浏览量
175 浏览量
2023-03-11 上传
594 浏览量
732 浏览量
628 浏览量
579 浏览量
533 浏览量
713 浏览量

终年i
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 大酒店员工手册
- xoak-feedstock:一个xoak的conda-smithy仓库
- 文件夹
- 易语言源码易语言使用脚本开关系统还原源码.rar
- SleepDisplay:命令行工具可让您的Mac显示器直接进入睡眠状态
- Papara Excel İşlem Özeti-crx插件
- python程序设计(基于网络爬虫的电影评论爬取和分析系统)
- OlaMundo:Primeiro存储库
- 零售业管理:价格策略
- 投资组合
- java笔试题算法-Complete-Striped-Smith-Waterman-Library:Complete-Striped-Smit
- ros_arm_control.7z
- tripitaka:Tripitaka的依赖性很低,没有针对Node.js的简洁记录器
- 以品类管理为导向的连锁企业管理功能重组
- 长颈鹿
- 三菱Q系列PLC选型工具软件.zip
