机器学习面试:特征工程中的异常检测与无量纲化
需积分: 0 90 浏览量
更新于2024-08-05
收藏 606KB PDF 举报
"这篇内容是关于机器学习与深度学习面试中的特征工程专题,涉及数据清洗、异常点检测、特征类型、无量纲化(归一化)及其应用场景以及缺失值处理方法。"
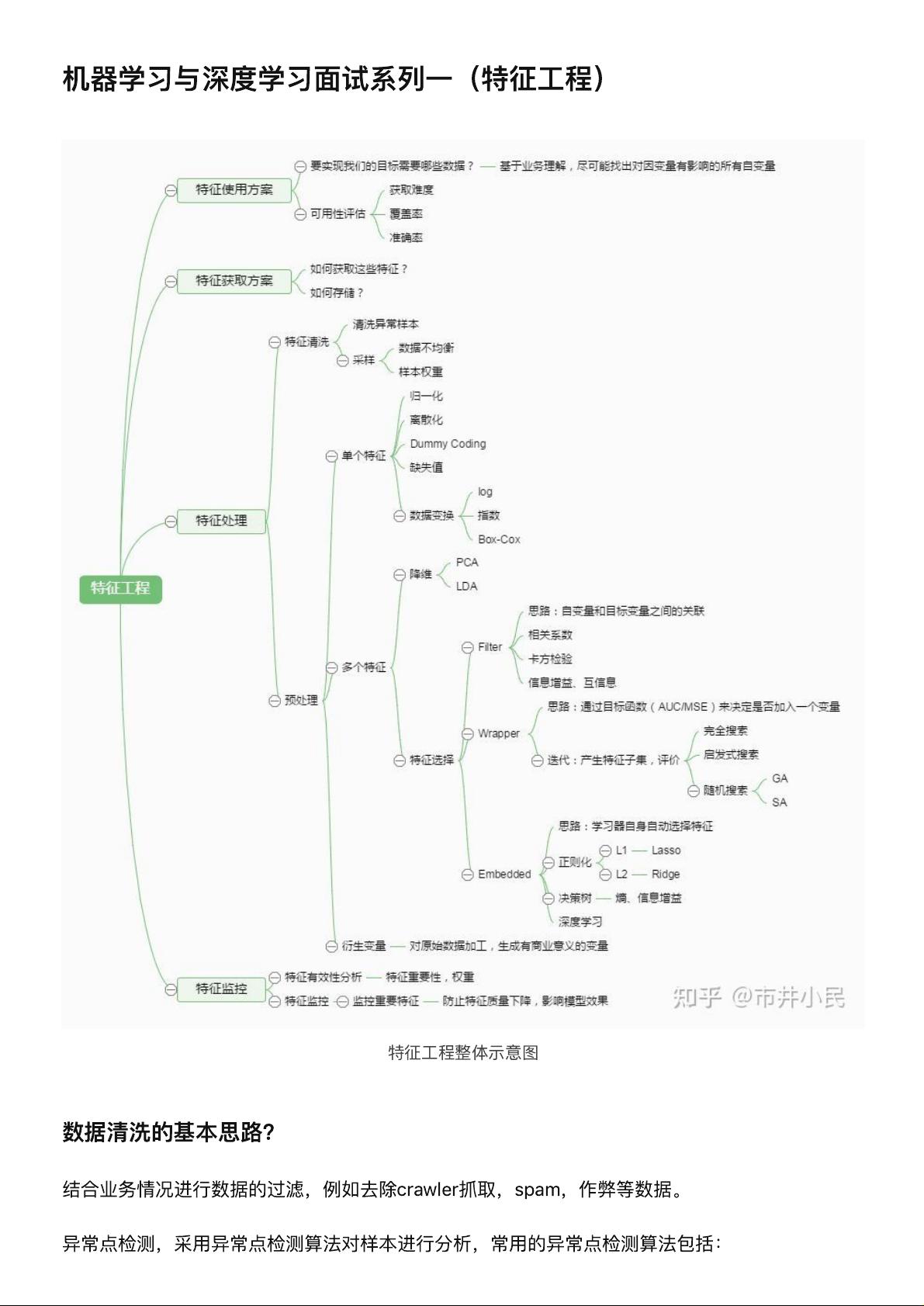
在机器学习和深度学习的面试中,特征工程是极其关键的一环。特征工程是指将原始数据转化为对模型训练有用的输入特征的过程。在这个系列的第一部分,我们重点关注数据清洗和异常点检测。
数据清洗是特征工程的首要步骤,主要是去除无关或有害的数据。这包括删除 crawler 抓取的无效数据、spam 信息以及识别并处理作弊数据。异常点检测则用于识别数据集中的异常值,这些值可能会影响模型的训练和性能。常见的异常点检测算法有:
1. 偏差检测,比如使用聚类算法,通过将数据点分配到不同的群组中,发现远离群中心的点作为异常点;还有最近邻方法,依据数据点与其最近邻居之间的距离判断是否为异常。
2. 基于统计的异常点检测,利用统计指标如极差、四分位数间距、均差和标准差来识别偏离正常范围的数据点。
3. 基于距离的检测,通过计算数据点与大多数点之间的距离,当这个距离超过某个阈值时,认为该点为异常点。常用的距离度量包括绝对距离(如曼哈顿距离)、欧氏距离和马氏距离。
4. 基于密度的异常点检测算法,如LOF(Local Outlier Factor),通过考察数据点周围邻域的密度来发现局部异常。
特征可以分为结构化和非结构化特征。结构化特征通常是有固定格式的数据,如数值和类别型数据,而非结构化特征包括文本、图片、视频等,它们无法用固定长度的行来表示,且长度各异。
无量纲化(归一化)是处理数值型特征的重要手段,主要有两种方法:标准化和归一化。标准化将数据映射到均值为0、标准差为1的分布,而归一化则将数据映射到[0,1]的区间。进行无量纲化的目的是提高模型精度、加快模型收敛速度,并确保不同特征在同一尺度上具有可比性。某些特定模型,如基于距离的KNN、线性回归、逻辑回归和神经网络,以及使用梯度下降优化的模型,需要特征的无量纲化。然而,决策树类模型一般不需要,因为它们的划分策略不受数值缩放影响。
处理缺失值的方法包括不处理(如果缺失值比例较小且模型能自动处理)、删除(若缺失值对预测影响不大或大量存在)以及填充(用统计值如中位数、平均数、众数填充,或者使用插值法、线性回归、K近邻等算法预测填充)。正确处理缺失值对于保持数据质量和模型的准确性至关重要。
机
器
学
习
与
深
度
学
习
⾯
试
系
列
⼀(
特
征
⼯
程
)
特
征
⼯
程
整
体
示
意
图
数据
清洗
的
基
本
思
路
?
结
合
业
务
情
况
进
⾏
数据
的
过
滤
,
例
如
去
除
c
r
a
w
le
r
抓
取
,
sp
a
m
,
作
弊
等
数据
。
异常
点
检
测
,
采
⽤
异常
点
检
测
算
法
对
样本
进
⾏
分
析
,
常
⽤
的
异常
点
检
测
算
法
包
括
:
下载后可阅读完整内容,剩余5页未读,立即下载
2023-07-14 上传
2022-08-03 上传
2021-09-30 上传
2022-01-11 上传
2024-06-13 上传
2024-05-14 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

石悦
- 粉丝: 19
- 资源: 285
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
