SQLServer查询技巧:解决复杂表单问题与逻辑顺序解析
144 浏览量
更新于2024-08-30
收藏 117KB PDF 举报
"本文主要探讨了SQL Server中关于表单查询的问题及解决方法,包括如何查询每门课程分数都超过80分的学生、删除重复数据、生成比赛组合以及理解SQL语句的逻辑处理顺序。文章深入浅出地解析了SELECT语句的各个组成部分,如FROM, WHERE, GROUP BY, HAVING, SELECT, ORDER BY等,并给出了相应的示例来展示其执行顺序。"
在SQL Server中,处理复杂的查询时,理解查询语句的逻辑处理顺序至关重要。这个顺序通常被称为SQL的"执行计划"或"解析顺序",它决定了数据如何被筛选、分组、计算和排序。以下是对各个子句的详细解释:
1. **FROM** 子句:首先执行,用于指定要从中选取数据的表或视图。在示例中,FROM Sales.Orders选择了Orders表作为数据源。
2. **WHERE** 子句:紧跟其后,根据指定的条件过滤行。在例子中,WHERE custid=71限制了结果只包含那些customer id为71的订单。
3. **GROUP BY** 子句:对数据进行分组,使得每个组内的数据具有相同的值。GROUP BY empid, YEAR(orderdate)将订单按销售员ID和订单年份分组。
4. **HAVING** 子句:与WHERE类似,但它用于对GROUP BY后的结果集进行过滤。HAVING COUNT(*)>1保留了每个销售员每年有多个订单的记录。
5. **SELECT** 子句:定义要从结果集中选择的列。在示例中,SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) numorders选取了销售员ID、订单年份(重命名为orderyear)和每个组的订单数量。
6. **ORDER BY** 子句:最后,按照指定的列对结果进行排序。ORDER BY empid, orderyear确保结果按销售员ID和订单年份升序排列。
了解这些子句的执行顺序有助于优化查询性能,尤其是在处理大数据集时。例如,通过先应用WHERE子句过滤掉大部分不相关的行,可以减少后续步骤的数据量,提高效率。
对于题目中给出的问题:
**Q1**: 可以使用`GROUP BY`和`HAVING`子句结合`COUNT()`函数来找出所有课程得分都超过80分的学生。首先按学生分组,然后检查每门课程的平均分数是否都大于80。
**Q2**: 删除DEMO_DELTE表中冗余的学生信息,可以通过自连接查找并删除重复记录,保留唯一自动编号不同的记录。
**Q3**: 生成团队比赛的所有可能组合,可以使用自连接和UNION ALL操作,将所有可能的对战组合列出。
**Q4**: 提供的SQL语句展示了在Microsoft SQL Server中,从选择数据源开始,经过过滤、分组、条件筛选、选择字段、再到排序的整个过程。
通过掌握这些基本的SQL查询技巧和理解执行顺序,可以有效地解决实际的数据库查询问题,提升数据库管理和分析能力。
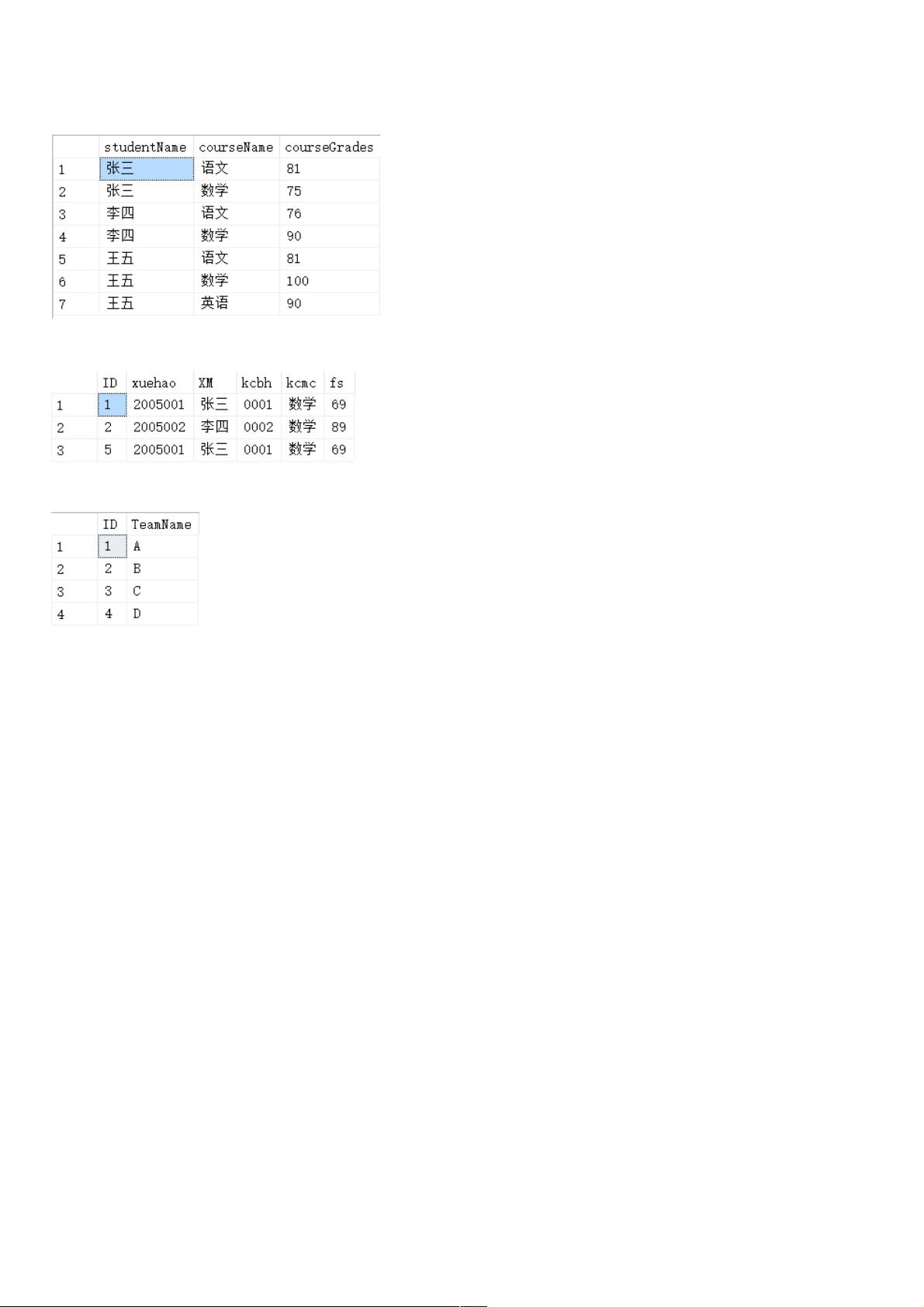
SqlServer 表单查询问题及解决方法表单查询问题及解决方法
Q1:表StudentScores如下,用一条SQL语句查询出每门课都大于80分的学生姓名
Q2:表DEMO_DELTE如下,删除除了自动编号不同,其他都相同的学生冗余信息
Q3:Team表如下,甲乙丙丁为四个球队,现在四个球对进行比赛,用一条sql语句显示所有可能的比赛组合
Q4:请考虑如下SQL语句在Microsoft SQL Server 引擎中的逻辑处理顺序
USE TSQLFundamentals2008
SELECT empid,YEAR(orderdate) AS orderyear,COUNT(*) numorders
FROM Sales.Orders
WHERE custid=71
GROUP BY empid,YEAR(orderdate)
HAVING COUNT(*)>1
ORDER BY empid,orderyear
本篇文章将剖析一般查询过程中,涉及到的处理逻辑子句,主要包括FROM,WHERE,GROUP BY,HAVING,SELECT,ORDER
BY,TOP,OVER等子句。
2 SELECT语句的元素语句的元素
2.1 常规查询子句和逻辑处理顺序常规查询子句和逻辑处理顺序
对数据表进行检索查询时,查询语句一般包括FROM,WHERE,GROUP BY,HAVING,SELECT,ORDER BY,TOP,OVER等子
句,请考虑如下例子的逻辑处理顺序。
USE TSQLFundamentals2008
SELECT empid,YEAR(orderdate) AS orderyear,COUNT(*) numorders
FROM Sales.Orders
WHERE custid=71
GROUP BY empid,YEAR(orderdate)
HAVING COUNT(*)>1
ORDER BY empid,orderyear
如上代码,在SQL中逻辑处理顺序如下:
USE TSQLFundamentals2008
下载后可阅读完整内容,剩余3页未读,立即下载
2021-01-19 上传
2022-05-27 上传
2012-11-07 上传
2023-08-27 上传
2024-11-09 上传
2024-11-09 上传
2024-11-07 上传
2024-11-07 上传
2024-11-07 上传
2023-06-09 上传

weixin_38618315
- 粉丝: 1
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







