Rough-DBSCAN:大数据集的快速混合密度聚类方法
需积分: 9 182 浏览量
更新于2024-09-12
1
收藏 646KB PDF 举报
Rough-DBSCAN是一种针对大型数据集的快速混合密度聚类方法,它结合了经典的DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法的优势和改进。DBSCAN以其能发现任意形状的簇以及有效处理噪声点而受到欢迎,但其时间复杂度为O(n^2),对于大规模数据集来说效率较低。为此,Rough-DBSCAN提出了一种解决方案,首先利用领导者聚类(Leaders Clustering)技术。
领导者聚类是指从原始数据集中提取出具有代表性的样本,即“领导者”,这些样本不仅能保留数据的密度信息,还能作为后续聚类过程的基础。这种方法通过首先对数据进行预处理,将高密度区域的样本作为原型(或领导者),从而显著降低了DBSCAN在大数据集上的时间消耗。这样做之后,Rough-DBSCAN使用这些领导者来划分和聚合邻域,而不是对整个数据集进行逐个比较,从而极大地提高了聚类效率。
在Rough-DBSCAN中,关键步骤包括:
1. **密度估计**:通过计算每个数据点周围的邻居数量或密度,确定高密度区域。
2. **领导者提取**:从高密度区域中选择那些代表性的样本作为领导者,它们可以是核心对象(拥有足够多的邻域点)或边界对象(介于核心和噪声之间)。
3. **领导者聚类**:使用领导者为中心,应用DBSCAN算法,但只对领导者及其邻域内的点进行处理,而非整个数据集。
4. **聚类结果扩展**:基于领导者聚类的结果,将相邻的低密度区域合并到相应的簇中。
这种方法的优势在于:
- **时间复杂度降低**:通过减少密集区域的搜索范围,大大减少了计算量。
- **可扩展性**:适合处理大规模数据集,不会因为数据量大而造成性能瓶颈。
- **保持密度信息**:领导者不仅包含原始数据的密度特性,还可以用作构建簇的有效参考。
Rough-DBSCAN作为一种高效的数据挖掘算法,尤其适用于处理大规模数据集中的复杂聚类任务,通过引入领导者概念,实现了在保持DBSCAN核心思想的同时,显著提高了聚类效率。研究者们可以借此方法在实际应用中处理实时或者大数据场景中的分类和异常检测问题。
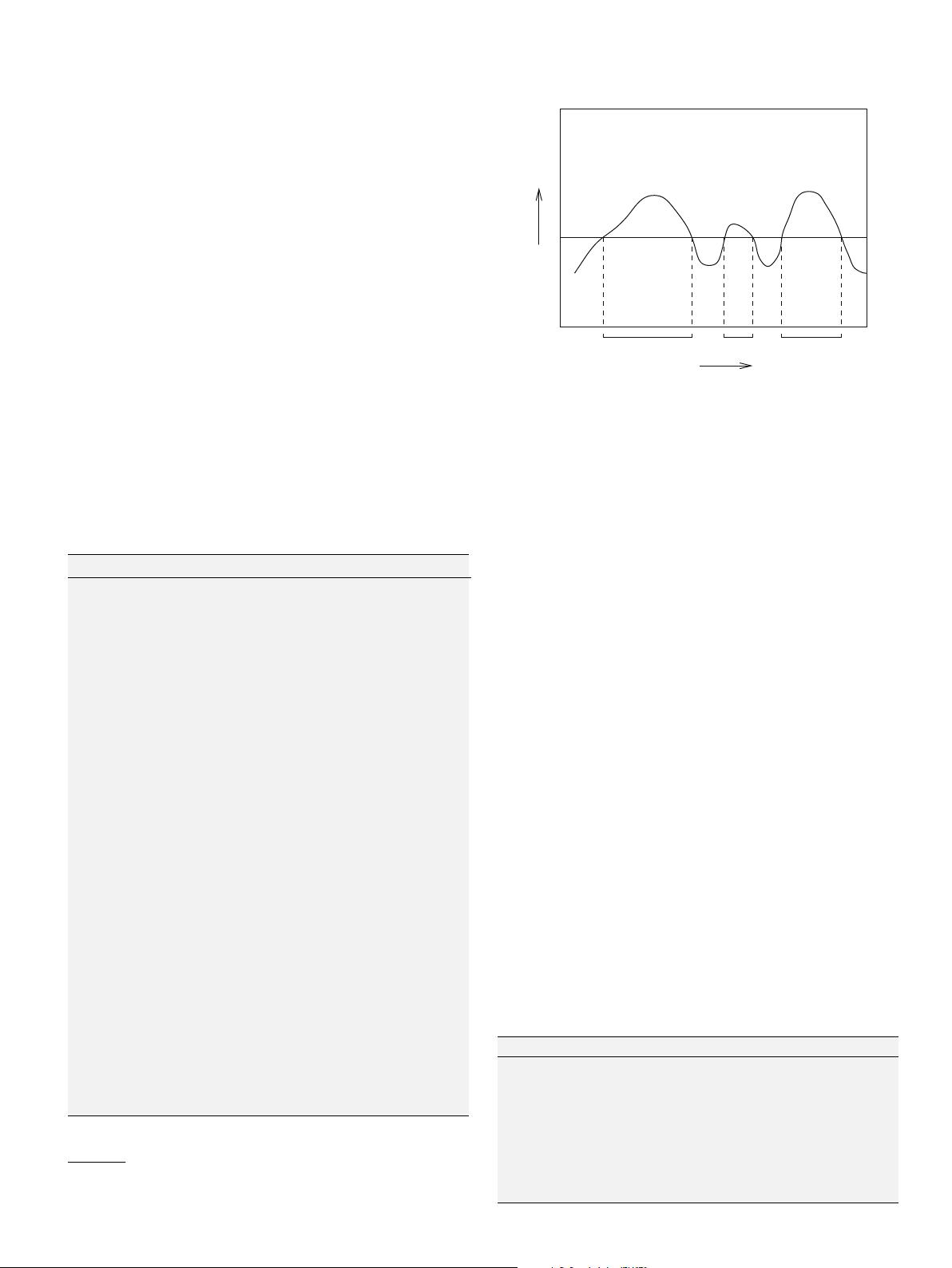
According to DBSCAN if a pattern x is dense
1
then it is part of a
cluster. A non-dense pattern can also be part of a cluster as a border
pattern of the cluster if it is at a distance less than or equal to
from
a dense pattern, otherwise it is a noisy outlier. Two patterns x
1
and
x
2
are in a cluster if there is a sequence of patterns x
1
; y
1
; y
2
; ...; y
m
; x
2
in the dataset such that:
(1) the distance between successive patterns in the sequence is
less than or equal to
,
(2) if m ¼ 0, then at least one of x
1
and x
2
is dense, and
(3) if m > 0, then the patterns y
1
; y
2
; ...; y
m
are dense.
The method DBSCAN is given in Algorithm 1 where D is the in-
put dataset, N
ðx; DÞ is the subset of patterns in D that are present
in the hyper-sphere of radius
at x where x 2 D. cardðN
ðx; DÞÞ is
the cardinality of the set which is nothing but jN
ðx; DÞj. For given
and MinPts, DBSCAN finds a dense point in the input set and ex-
pands it by merging neighboring dense regions together. The algo-
rithm marks each pattern of D with a cluster identifier (cid) which
gives the cluster to which the pattern belongs or gives a mark
‘‘noise” indicating that the pattern is a noisy one. One additional
mark ‘‘seen” is used to distinguish between the patterns which
are processed from that which are not. Note that a pattern which
is initially marked as ‘‘noise” can later become a border point of a
cluster and hence the ‘‘noise” mark can be deleted.
Algorithm 1. DBSCAN(D,
, MinPts)
{Each cluster is given an identifier cid}
cid =0;
for each pattern x in D do
if x is not marked as ‘‘seen” then
Mark x as ‘‘seen”;
Find N
ðx; DÞ;
if cardðN
ðx; DÞÞ <MinPts then
Mark x as ‘‘noise”;
else
Mark x as ‘‘seen”;
cid = cid +1;
Mark each pattern of N
ðx; DÞ with cluster
identifier cid;
Add each pattern of N
ðx; DÞ which is not marked
as ‘‘seen” to the list queue(cid).
while queue(cid) is not empty do
Take a pattern y from queue(cid) and mark it as
‘‘seen”;
if cardðN
ðy; DÞÞ >MinPts then
Mark each pattern of N
ðy; DÞ with cluster
identifier cid;
If any pattern of N
ðy; DÞ is marked as
‘‘noise” then remove this mark.
Add each pattern of N
ðy; DÞ which is not
marked as ‘‘seen” to the list queue(cid).
end if
Remove y from queue(cid).
end while
end if
end if
end for
Output all patterns of D along with their cid or ‘‘noise” mark;
It can be seen that the time consuming step in the DBSCAN is in
finding N
ðx; DÞ which can take OðnÞ time where x 2 D and jDj¼n.
Hence the time complexity of the method is Oðn
2
Þ. On the other-
hand, if we derive k leaders first by applying the leaders clustering
method and subsequently applying DBSCAN only with leaders has
a total time complexity of Oðn þ k
2
Þ. This is because the leaders
clustering method, as explained in subsequent sections, takes only
OðnÞ time to derive the leaders. Also it is formally established that
an upper-bound on the number of leaders i.e., k exists which is
independent of both n and the distribution from which the dataset
is drawn, provided the assumption that the data is drawn from a
bounded region of the feature space holds. Nevertheless, in gen-
eral, based on the experimental studies, it is shown that k is con-
siderably smaller than n, especially with large datasets. Hence
the hybrid scheme can be a faster one to work with large datasets.
Table 1 describes the space and time complexities of well known
clustering methods and rough-DBSCAN.
3. Leaders
In this section, we first present the leaders clustering method
(Spath, 1980; Hartigan, 1975) then as an improvement of this we
present the counted-leaders method which preserves the crucial
density information when the cluster representatives called leaders
are derived.
Leaders method finds a partition of the given dataset like most
of the clustering methods. Its primary advantage is its running
time which is linear in the size of the input dataset. To be more
precise, it can find the partition in OðnÞ time where n is the dataset
size. It needs to read (or scan) the dataset only once from the sec-
ondary memory and hence is also termed as an on-line clustering
method. Because of these factors the leaders method is gaining
Table 1
Time and space complexities of the well known clustering methods.
Method Time complexity Space complexity
Single/complete link
Oðn
3
Þ Oðn
2
Þ
K-means Oðn K tÞ OðKÞ
K-medians
Oðn
2
tÞ
OðnÞ
K-medoids (PAM)
OðK ðn KÞ
2
Þ
OðKÞ
DBSCAN
Oðn
2
Þ
OðnÞ
CURE
OðN
2
sample
Þ OðN
2
sample
Þ
BIRCH OðnÞ (2 database scans) OðN BÞ
Leader OðnÞ (1 database scan)
OðkÞ
Rough-DBSCAN
Oðn þ k
2
Þ (1 database scan)
OðkÞ
x
p(x)
CCC
123
T
Fig. 1. Clusters found by DBSCAN.
1
DBSCAN given in (Ester et al., 1996) calls a dense point as a core point and a non-
dense point as a non-core point. This modification is done to bring the material closer
to the pattern recognition community.
P. Viswanath, V. Suresh Babu / Pattern Recognition Letters 30 (2009) 1477–1488
1479
剩余11页未读,继续阅读
2014-04-30 上传
308 浏览量
2021-10-06 上传
2023-07-13 上传
2023-08-28 上传
2023-05-31 上传
2023-07-08 上传
2023-06-02 上传
2023-05-25 上传

xfd521
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
