Spark集群内部集成Elasticsearch实践
需积分: 0 171 浏览量
更新于2024-07-17
收藏 2.8MB PDF 举报
"SparkClusterwithElasticsearchInside.pdf" 是一份由Oscar Castañeda-Villagrán在SPARK SUMMIT 2017上发表的演讲材料,内容聚焦于如何在Spark集群内部集成Elasticsearch,以及如何进行读取/写入操作,创建内部ES服务器,使用S5快照和恢复ES索引等技术。
### Spark与Elasticsearch集成的背景与动机
在开发过程中,当Elasticsearch运行在Spark集群之外时,会带来诸多不便,例如通信延迟、管理复杂性增加以及对运维(DevOps)的额外需求。这种情况下,将Elasticsearch集成到Spark集群内部可以简化架构,提高数据处理效率,并优化整体性能。
### Spark与Elasticsearch的内部集成
1. **读/写内部ES服务器**: Spark可以直接与运行在集群内的Elasticsearch节点通信,进行数据的读取和写入。这种方式减少了网络开销,提高了数据传输速度,有利于大数据实时分析和检索。
2. **创建内部ES服务器**: 演讲详细介绍了如何在Spark集群内部部署和配置Elasticsearch服务,使得两者能够紧密协作,共同处理数据。这样做的好处是减少了外部依赖,提升了系统的可扩展性和可靠性。
3. **使用S3进行ES索引的快照/恢复**: 利用Amazon S3作为持久化存储,可以对Elasticsearch的索引进行快照和恢复操作。这对于数据备份、灾难恢复和版本管理至关重要,同时S3的高可用性和稳定性也保证了数据的安全性。
4. **现场演示:在Spark上实时索引带有Elasticsearch的推文**:演讲中通过一个现场演示展示了如何利用Spark处理实时数据流(如推文),并将其实时索引入到内部的Elasticsearch中。这展示了Spark和Elasticsearch集成的强大实时处理能力。
### 结构与流程
- **问题声明**:指出了传统架构中ES与Spark分离的挑战。
- **架构**:对比了传统架构和集成架构,强调了内部集成的优势。
- **恢复ES快照**:描述了如何从S3中恢复Elasticsearch索引的过程。
- **读取CSV文件**:展示了如何从CSV数据源读取数据并导入到Elasticsearch。
- **创建ES快照**:解释了如何在Spark中对Elasticsearch索引进行快照操作。
### 总结
"SparkClusterwithElasticsearchInside"深入探讨了如何在Spark集群内高效地整合Elasticsearch,以实现更优化的数据处理流程。通过这种方式,可以提高数据处理效率,简化运维,同时提供可靠的数据备份和恢复策略,对于处理大规模实时数据的场景尤其适用。这份演讲资料对于理解和实践Spark与Elasticsearch的集成具有极高的参考价值。
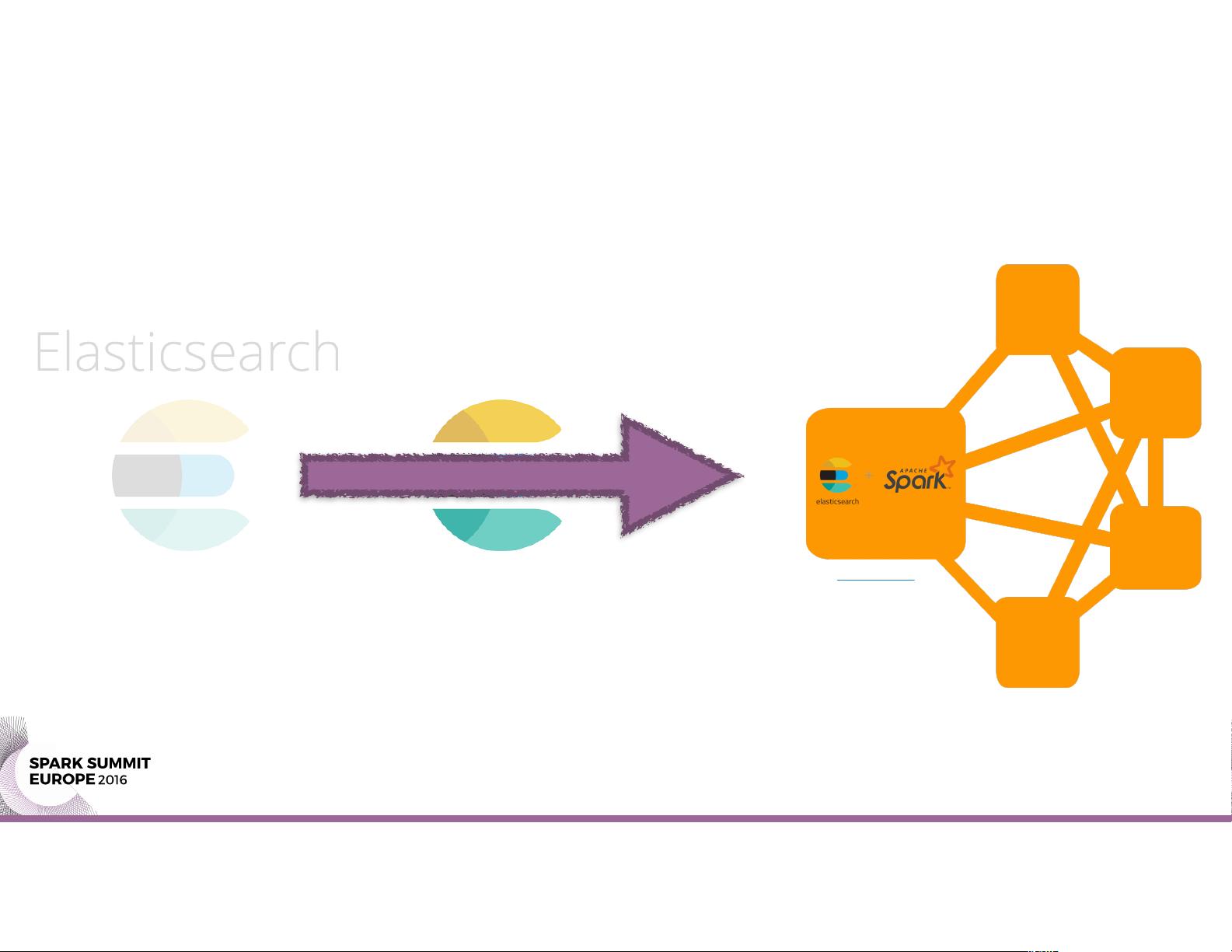
Spark cluster with Elasticsearch
http://bit.ly/2em6RUK
剩余27页未读,继续阅读
568 浏览量
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传
2025-01-05 上传

weixin_38743506
- 粉丝: 351
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 保护栏:从OpenAPI规范中生成有原则的代码
- BootstrapTask
- webapp:模拟社交媒体统计网站
- 园区交换机(Visio图标)
- ISI:类似 Eliza 的聊天机器人
- 具有Django和A-Frame的360 Image Web Gallery
- adapter-change_management:Itential学院IDEV102 Itential Adapter Essentials II课程
- PHP解析器:用PHP编写PHP解析器
- FreeIva:Kerbal Space Program的进行中模块,允许在IVA上坐下并在船上四处走动
- 心理测评操作材料.rar
- jdk-8u271-linux64 版本
- 易语言-易语言制作属于你的系统一键备份还原
- Bicycles HD Wallpapers Bikes New Tab Theme-crx插件
- fetching
- AppTracker前端
- react-helmet:React的文档主管
