数据挖掘:关联规则与频繁模式分析
需积分: 10 170 浏览量
更新于2024-07-26
收藏 1.23MB PPT 举报
"数据挖掘中的关联规则是数据挖掘领域的一个重要概念,主要涉及到频繁模式分析、大规模数据集处理、约束条件下的关联挖掘以及从关联到相关性分析等多个方面。这一技术最早由Agrawal, Imielinski和Swami在1993年提出,主要用于发现数据中的内在规律,例如购物篮分析中的啤酒与尿布问题,购买电脑后的后续购买行为,对特定药物敏感的DNA序列,以及自动分类网络文档等。关联规则广泛应用于市场篮子分析、交叉营销、目录设计、销售活动分析、网络日志分析和DNA序列分析等场景。"
关联规则挖掘是数据挖掘中的核心算法之一,它旨在发现数据集中频繁出现的项集(频繁模式)以及这些项集之间的关联关系。Agrawal等人提出的Apriori算法是最早的关联规则挖掘算法,它通过生成频繁项集并构建关联规则来找出数据集中的常见购买模式。例如,在超市购物数据中,可能发现购买啤酒的顾客往往也会购买尿布,这种关联关系可以用于指导商家制定促销策略。
除了基本的Apriori算法,随着大数据时代的到来,处理大规模数据集的需求日益增长,出现了许多可扩展的频繁项集挖掘方法,如Eclat、FP-Growth等,它们通过优化数据结构和算法效率,能够高效地处理海量数据。
关联规则挖掘不仅可以找出频繁项集,还可以进一步挖掘各种类型的关联规则,如强规则、近似规则、置信度规则等。这些规则可以用来描述项集之间的概率关系,例如,“如果一个顾客购买了啤酒,那么他有80%的可能性会购买尿布”。同时,约束条件下的关联挖掘允许我们根据业务需求设置特定的条件,如最小支持度和最小置信度,以过滤出更有价值的规则。
从关联规则到相关性分析的转变,意味着我们可以将挖掘的焦点从简单的“如果-那么”形式扩展到更复杂的变量间的关系,例如时间序列分析中的相关性或因果关系。这在诸如股票市场预测、医疗研究等领域具有广泛应用。
最后,挖掘庞大的模式是指处理包含大量项的频繁模式,这对于理解复杂数据集中的深层次结构至关重要。例如,在DNA序列分析中,寻找长串的共享序列可以帮助识别基因家族或疾病相关的遗传变异。
总结来说,关联规则挖掘是数据挖掘中一个关键的技术,它不仅有助于发现数据集中的隐藏模式,还能为企业决策、市场策略、科学研究等提供有价值的洞察。通过不断演进的算法和方法,关联规则挖掘在面对大规模、复杂数据时依然保持其强大的分析能力。
2021年8月4日 Data Mining: Concepts and Techniques 11
!89:.
;
<.
=
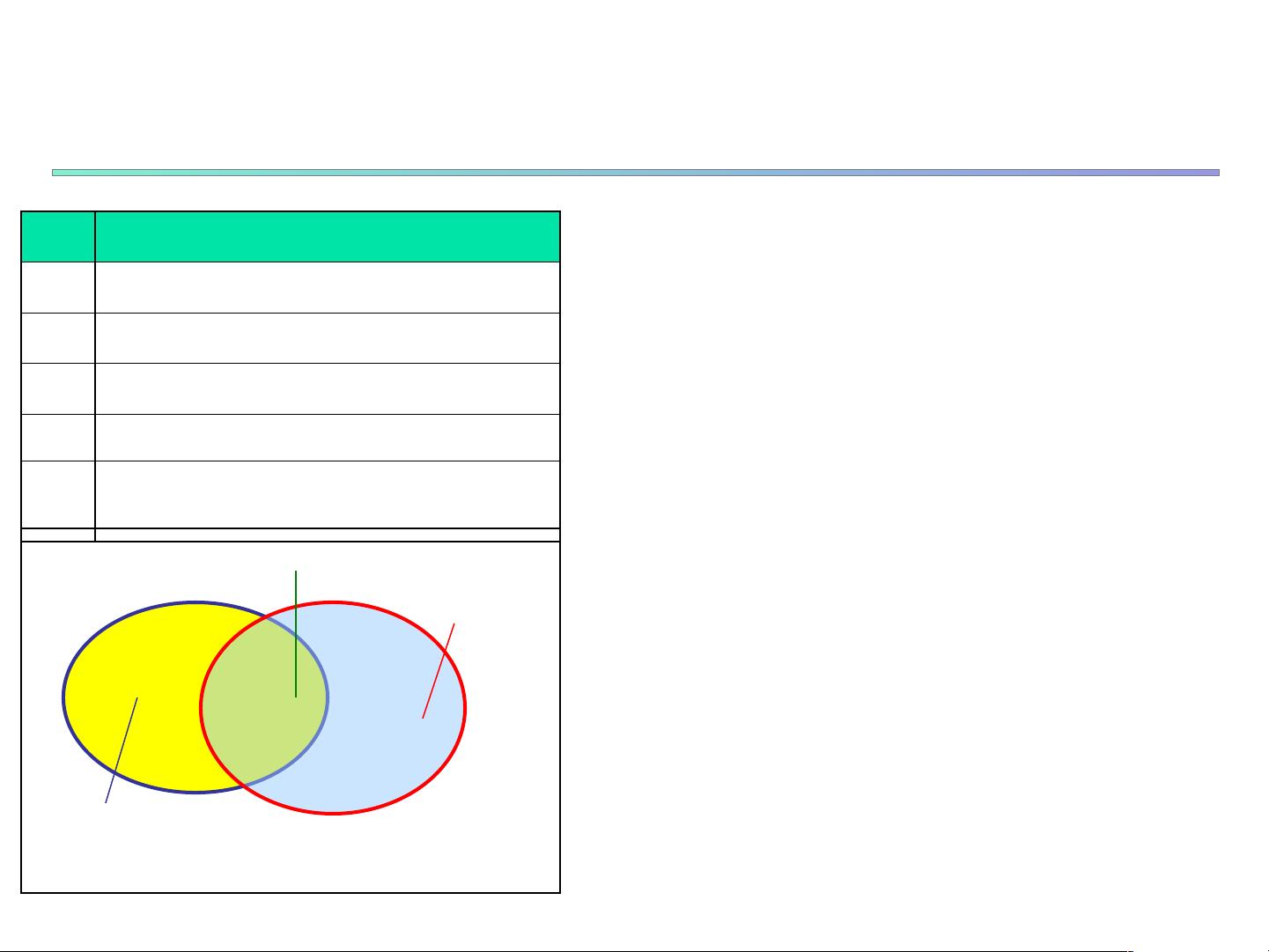
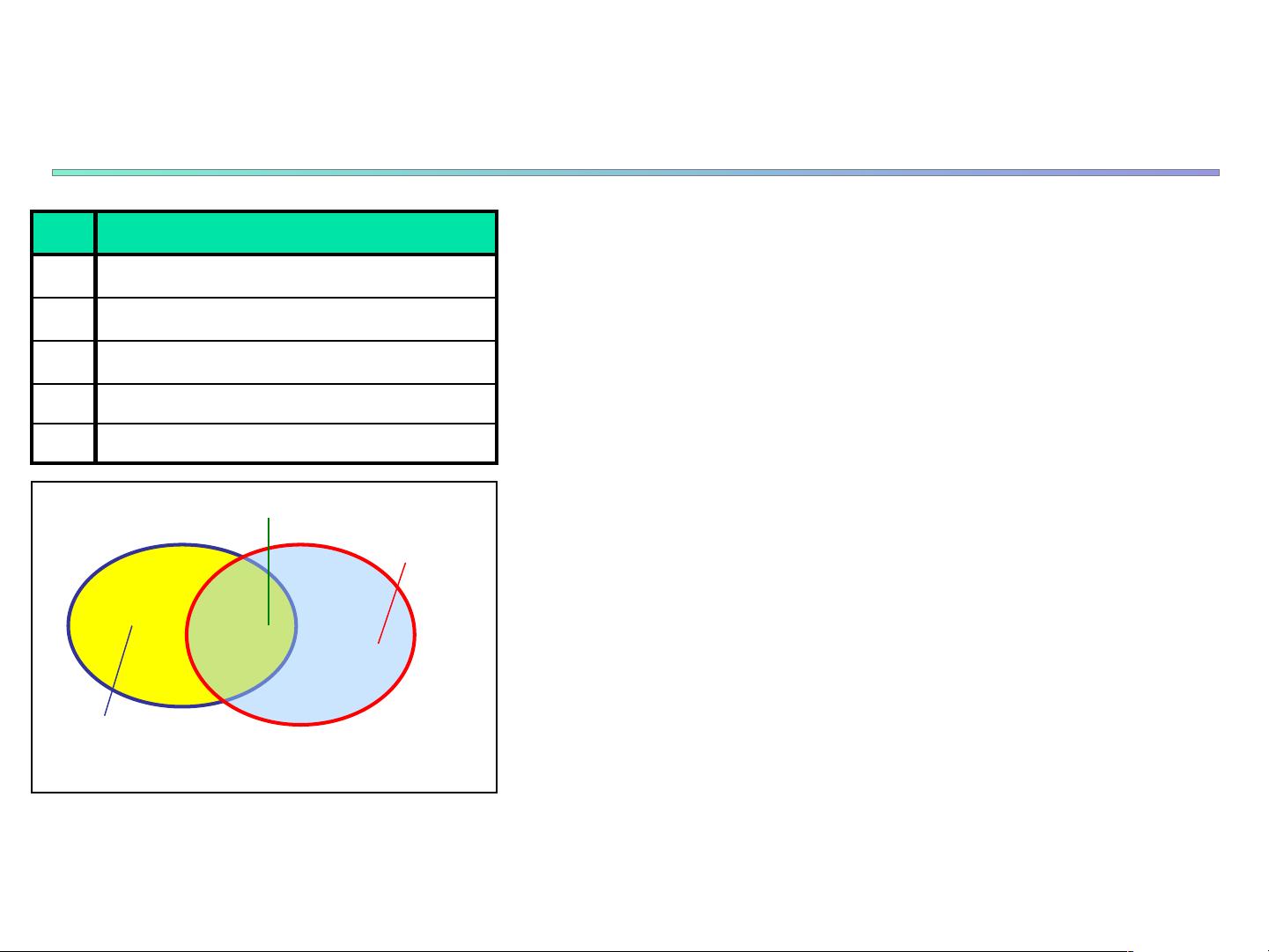
(absolute) support
support count8"
8
(relative)supports
8&''
"
8(
8frequent8F
minsup
Customer
buys diaper
Customer
buys both
Customer
buys beer
Tid Items bought
;? 21
C? G1
,? 1D
? 2D
>? 2G1D

剩余63页未读,继续阅读
388 浏览量
2022-06-11 上传
2009-06-08 上传
2020-05-04 上传
2024-06-30 上传
515 浏览量
2021-07-14 上传

Eleven_Trista_11
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
