
1 AES Datapaths on FPGAs: A State of the Art Analysis 7
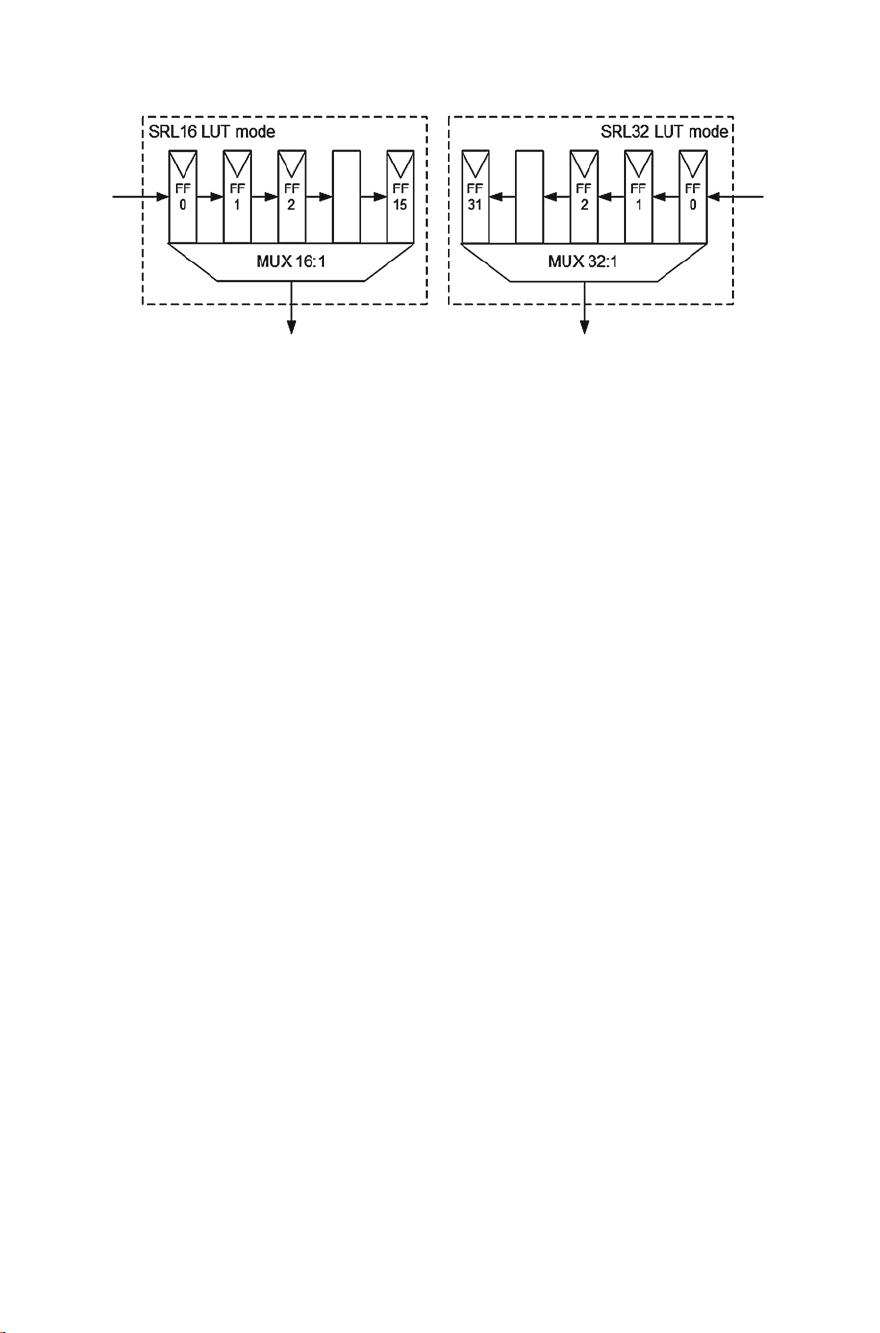
Fig. 1.4 The SRL16 (previous Xilinx FPGAs) and SRL32 (current Xilinx FPGAs) LUT modes
typically not requiring any additional functional logic components. This specific
routing is performed when mapping, placing, and routing the structure onto the
FPGA. However, ShiftRows and InvShiftRows (used on encryption and decryption,
respectively) have opposite shifting directions. Thus the routing path of each opera-
tion cannot be shared.
Performing the (Inv)ShiftRows operation through routing is often the preferred
choice in several proposed 128-bit datapaths such as Bulens et al. [2] and Liu et al.
[17]. However, this implies that a particular implementation can only handle one
ciphering mode. With this approach, two AES cores need to be deployed when
supporting encryption and decryption, as used in HELION Standard and HELION
Fast AES cores [13]. In order to support both encryption and decryption on a single
AES design, both routing options need to coexist. If properly designed, and given
the similarity of the remaining computations, only minimum multiplexing logic is
needed, as presented in Chaves et al. [4].
In smaller datapaths of 32 and 8-bit widths, performing the (Inv)ShiftRows
through routing is not viable, since the 16 bytes of the State are not available at
the same time. The predominant state of the art s olution for the (Inv)ShiftRows in
compact FPGA structures is using addressable memory, as introduced in Chodowiec
and Gaj [5]. These authors show how a RAM memory can be used to temporarily store
the State matrix between rounds, and perform either the ShiftRows or InvShiftRows
by properly addressing the writing and reading operations of the consecutive 32-bit
columns, or 8-bit cells, of the State [8, 11]. The authors further optimize this byte
shift operation by eliminating the need to specify the writing address. This approach
is optimized on Xilinx FPGAs using particular LUTs. On these devices, several LUTs
have an operational mode called SRL32 (SRL16 in older versions). This mode allows
for a single LUT to work as a 32-bit deep shift register with an addressable reading
port, resulting i n improved resource usage efficiency, as depicted in Fig. 1.4.This
approach can be found in 32-bit [5, 20, 23] and 8-bit [6, 25] AES designs.


剩余253页未读,继续阅读

soctest2010
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- IPQ4019 QSDK开源代码资源包发布
- 高频组电赛必备:掌握数字频率合成模块要点
- ThinkPHP开发的仿微博系统功能解析
- 掌握Objective-C并发编程:NSOperation与NSOperationQueue精讲
- Navicat160 Premium 安装教程与说明
- SpringBoot+Vue开发的休闲娱乐票务代理平台
- 数据库课程设计:实现与优化方法探讨
- 电赛高频模块攻略:掌握移相网络的关键技术
- PHP简易简历系统教程与源码分享
- Java聊天室程序设计:实现用户互动与服务器监控
- Bootstrap后台管理页面模板(纯前端实现)
- 校园订餐系统项目源码解析:深入Spring框架核心原理
- 探索Spring核心原理的JavaWeb校园管理系统源码
- ios苹果APP从开发到上架的完整流程指南
- 深入理解Spring核心原理与源码解析
- 掌握Python函数与模块使用技巧
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


