YOLOv1-v5算法详解:网络结构、代码解析、性能对比
版权申诉
160 浏览量
更新于2024-03-10
收藏 5.13MB DOCX 举报
YOLOv1是由2016年CVPR论文《You Only Look Once:Unified, Real-Time Object Detection》提出的一种目标检测算法。该算法的核心思想是将输入的图像经过backbone提取特征后,将得到的特征图划分为S x S的网格,然后通过对这些网格进行预测来实现目标检测。具体来说,物体的中心坐标落在哪一个网格内,这个网格就负责预测该物体的置信度、类别以及坐标位置。
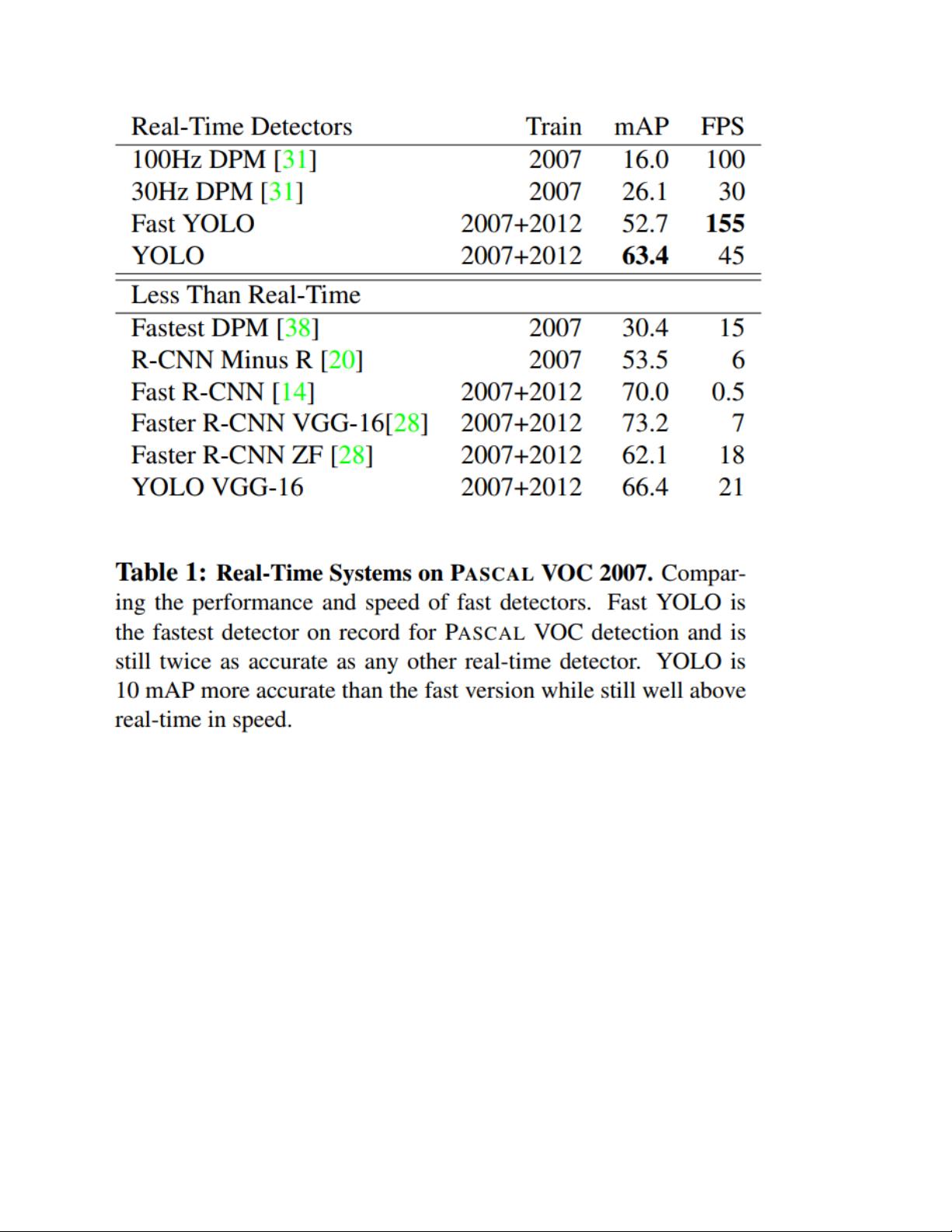
YOLOv1的整体架构非常快速,基础版本的帧率可以达到每秒45帧,而较小版本的帧率甚至可以达到每秒155帧。相比之前的检测方法如DPM和R-CNN等,YOLOv1的性能更加优越。作者提出了一种端到端的检测方法,即一次运行就可以同时得到所有目标的边界框和类别概率,避免了重复利用分类器的缺点。
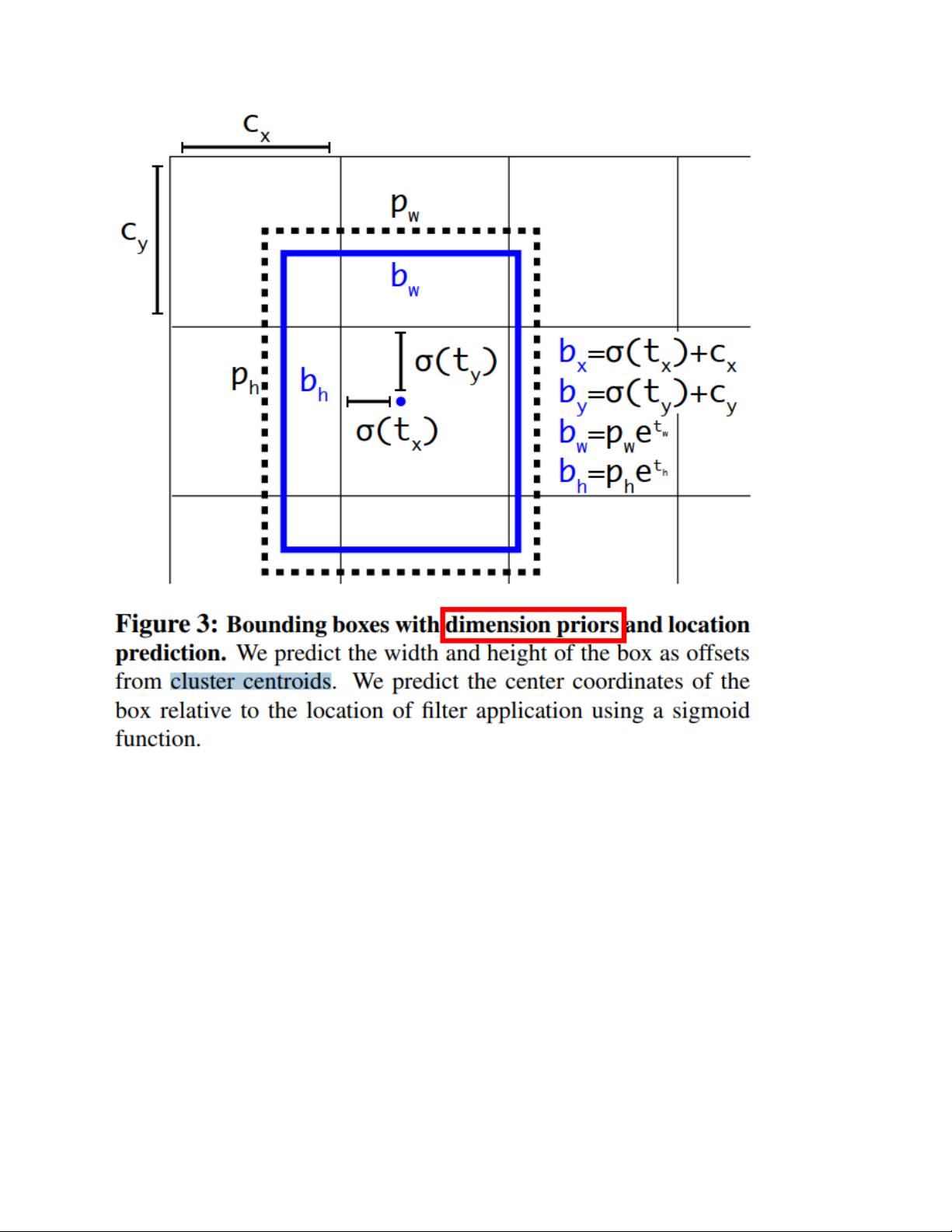
具体来说,YOLOv1算法首先通过预训练的卷积神经网络提取图像特征,然后将特征图分成S x S的网格,每个网格负责检测其中心位置位于该网格内的目标。对于每个网格,算法会预测出目标的类别、置信度以及坐标位置信息。最终通过阈值筛选和非极大值抑制等方法来得到最终的目标检测结果。
虽然YOLOv1在速度和性能上有着显著的优势,但也存在一些问题。由于将图像划分为网格,目标尺寸较小或者密集分布时容易漏检,同时对于长宽比较大的目标定位不准确。此外,YOLOv1的检测精度并不高,容易出现漏检和误检的情况。
为了优化这些问题,后续推出了YOLOv2、YOLOv3、YOLOv4和YOLOv5等版本。这些版本在网络结构、损失函数、调优方法等方面都有所改进,提高了目标检测的性能和准确率。例如,YOLOv2引入了多尺度预测和锚框机制,YOLOv3采用了更深的网络结构和FPN技术,YOLOv4利用了各种新的技术来提高目标检测的精度,而YOLOv5则采用了轻量级网络结构和精心设计的数据增强方法来实现更好的检测效果。
总的来说,YOLOv1到YOLOv5算法都是目标检测领域的经典算法,在实时性和准确性之间取得了很好的平衡。随着技术的不断发展和优化,相信未来会有更多更好的目标检测算法出现,为实时目标检测应用带来更大的价值。
Yolov1
实验对比结果
5,代码实现思考
一些思考:快速的阅读了网上的一些 YOLOv1 代码实现,发现整个 YOLOv1 检测系统的代码
可以分为以下几个部分:
• 模型结构定义:特征提器模块 + 检测头模块(两个全连接层)。
• 数据预处理,最难写的代码,需要对原有的 VOC 数据做预处理,编码成 YOLOv1 要
求的格式输入,训练集的 label 的 shape 为 (bach_size, 7, 7, 30)。
• 模型训练,主要由损失函数的构建组成,损失函数包括 5 个部分。
• 模型预测,主要在于模型输出的解析,即解码成可方便显示的形式。


剩余65页未读,继续阅读
2024-03-26 上传
2023-11-01 上传
2024-07-10 上传
2023-02-24 上传
2023-06-10 上传
2023-09-04 上传
2023-05-31 上传
2023-11-10 上传
2023-07-01 上传

码农张三疯
- 粉丝: 1w+
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
