机器学习模型性能评估与比较
版权申诉
195 浏览量
更新于2024-06-27
收藏 1.07MB PPTX 举报
"该资源是一份关于机器学习中模型比较方法的PPT,主要讨论了如何评价和比较机器学习模型的性能。涉及的关键概念包括DBSCAN算法,以及一系列的评估方法和统计检验,如正确率、错误率、查全率、查准率、PR曲线、ROC曲线与AUC、留出法、交叉验证法、自助法、二项分布、t检验、McNemar检验、Friedman检验和Nemenyi检验等。"
在机器学习领域,模型的比较和评估是至关重要的步骤,以确定哪种模型最适合特定任务。这份资料详细介绍了模型性能比较中的三个核心问题:获取测试结果、评估性能优劣以及判断实质差别。
1. 获取测试结果:测试结果通常通过将数据集分为训练集和测试集来获得。模型在训练集上学习,然后在未见过的测试集上评估其性能。
2. 评估性能优劣:常见的性能度量包括准确率、错误率、查全率(Recall)、查准率(Precision),以及通过PR(Precision-Recall)曲线和ROC(Receiver Operating Characteristic)曲线及AUC(Area Under the Curve)来综合评估模型的性能。这些指标帮助我们了解模型在识别正负样本上的表现。
3. 判断实质差别:直接比较不同模型的评估指标并不总是准确的,因为测试性能可能因测试集变化和算法的随机性而变化。因此,需要统计检验,如二项分布检验(针对单个学习器的测试误差率)、t检验(比较多个测试误差率)、McNemar检验(适用于分类任务中两个模型的比较)、Friedman检验(多组模型间的总体比较)和Nemenyi检验(确定显著差异的临界距离)。
4. 模型比较方法:包括留出法(将数据集的一部分作为测试集)、交叉验证法(如K折交叉验证)和自助法(通过数据重采样创建新的训练和测试集)。这些方法旨在减少过拟合和提高评估的稳定性。
5. Friedman检验和Nemenyi后续检验:Friedman检验用于比较多个学习器在多个数据集上的平均性能,而Nemenyi检验则提供了一个临界距离(CD),如果不同学习器的平均排名超过这个距离,则认为它们的性能有显著差异。
这份资料提供了全面的视角,帮助我们理解如何系统地比较和选择机器学习模型,确保我们的选择基于可靠的评估和统计依据,而非简单的指标比较。
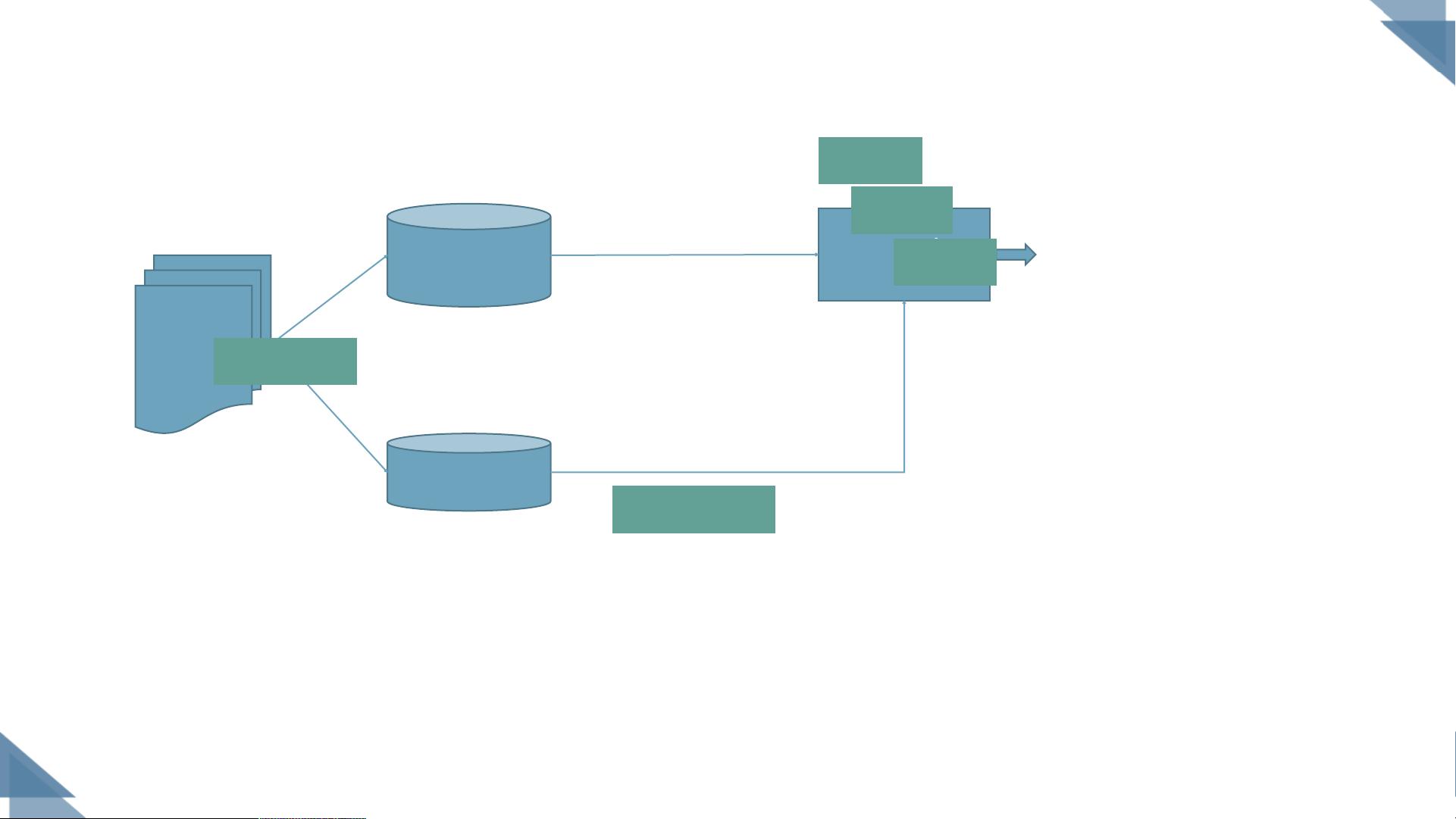
模型性能比较
训练集
测试集
模型
学习/训练
数
据
集
性能评估
投放使用
评估方法
评估指标
模型A
模型B
模型C
正确率、错误率
查全率、查准率
PR曲线
ROC与AUC
……
留出法
交叉验证法
自助法
剩余14页未读,继续阅读
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传
2023-01-14 上传

知识世界
- 粉丝: 373
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
