BERT模型的参数高效迁移学习策略
需积分: 0 20 浏览量
更新于2024-08-05
收藏 707KB PDF 举报
“Parameter-Efficient Transfer Learning for NLP - 迁移学习+BERT1”
在自然语言处理(NLP)领域,迁移学习已经成为一种有效的技术,它通过预先训练的大型模型来提升下游任务的性能。尤其是BERT(Bidirectional Encoder Representations from Transformers)模型,由于其强大的语义理解和生成能力,已经在多个NLP任务中取得了显著成果。然而,针对每个新任务进行完整的微调过程(fine-tuning)是参数效率低下的,因为这需要为每个任务训练一个全新的模型,占用大量计算资源。
为了解决这个问题,研究者提出了参数高效的迁移学习方法——适配器模块(Adapter Modules)。适配器模块提供了一种紧凑且可扩展的模型架构,它们只针对每个任务添加少量的可训练参数,而且在添加新任务时,无需重新训练先前的任务。原始网络的参数保持固定,实现了高度的参数共享,从而降低了存储和计算的需求。
在实践中,研究者将BERT模型应用于26个不同的文本分类任务,包括GLUE(General Language Understanding Evaluation)基准测试。通过使用适配器,他们能够在保持接近最先进的性能的同时,仅对每个任务增加少量参数。在GLUE基准上,适配器模块的表现与完整微调的性能差距不超过0.4%,而增加的参数量仅为任务总参数的3.6%。相比之下,传统的微调方法会为每个任务引入大量的额外参数,这在处理多个任务时显得效率低下。
适配器模块的引入,不仅提高了模型在多任务环境中的效率,还允许模型在不牺牲性能的前提下,更加灵活地适应新的任务需求。这对于资源有限的环境或者需要处理众多任务的场景尤其有价值。此外,适配器的引入也为持续学习和模型更新提供了新的可能性,使得模型可以随着新数据和新任务的出现而持续优化,而不会对已有的学习成果造成重大影响。
参数高效的迁移学习方法,如适配器模块,为NLP领域的模型泛化和资源管理带来了革命性的变化。它降低了大规模预训练模型的使用门槛,同时保持了高精度,是未来NLP研究和应用的一个重要方向。
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby
1
Andrei Giurgiu
1 *
Stanisław Jastrze¸bski
2 *
Bruna Morrone
1
Quentin de Laroussilhe
1
Andrea Gesmundo
1
Mona Attariyan
1
Sylvain Gelly
1
Abstract
Fine-tuning large pre-trained models is an effec-
tive transfer mechanism in NLP. However, in the
presence of many downstream tasks, fine-tuning
is parameter inefficient: an entire new model is
required for every task. As an alternative, we
propose transfer with adapter modules. Adapter
modules yield a compact and extensible model;
they add only a few trainable parameters per task,
and new tasks can be added without revisiting
previous ones. The parameters of the original
network remain fixed, yielding a high degree of
parameter sharing. To demonstrate adapter’s ef-
fectiveness, we transfer the recently proposed
BERT Transformer model to
26
diverse text clas-
sification tasks, including the GLUE benchmark.
Adapters attain near state-of-the-art performance,
whilst adding only a few parameters per task. On
GLUE, we attain within
0.4%
of the performance
of full fine-tuning, adding only
3.6%
parameters
per task. By contrast, fine-tuning trains
100%
of
the parameters per task.
1. Introduction
Transfer from pre-trained models yields strong performance
on many NLP tasks (Dai & Le, 2015; Howard & Ruder,
2018; Radford et al., 2018). BERT, a Transformer network
trained on large text corpora with an unsupervised loss,
attained state-of-the-art performance on text classification
and extractive question answering (Devlin et al., 2018).
In this paper we address the online setting, where tasks
arrive in a stream. The goal is to build a system that per-
forms well on all of them, but without training an entire new
model for every new task. A high degree of sharing between
tasks is particularly useful for applications such as cloud
services, where models need to be trained to solve many
*
Equal contribution
1
Google Research
2
Jagiellonian University.
Correspondence to: Neil Houlsby <neilhoulsby@google.com>.
Proceedings of the
36
th
International Conference on Machine
Learning, Long Beach, California, PMLR 97, 2019. Copyright
2019 by the author(s).
10
5
10
6
10
7
10
8
10
9
Num trainable parameters / task
−25
−20
−15
−10
−5
0
5
Accuracy delta (%)
Adapters (ours)
Fine-tune top layers
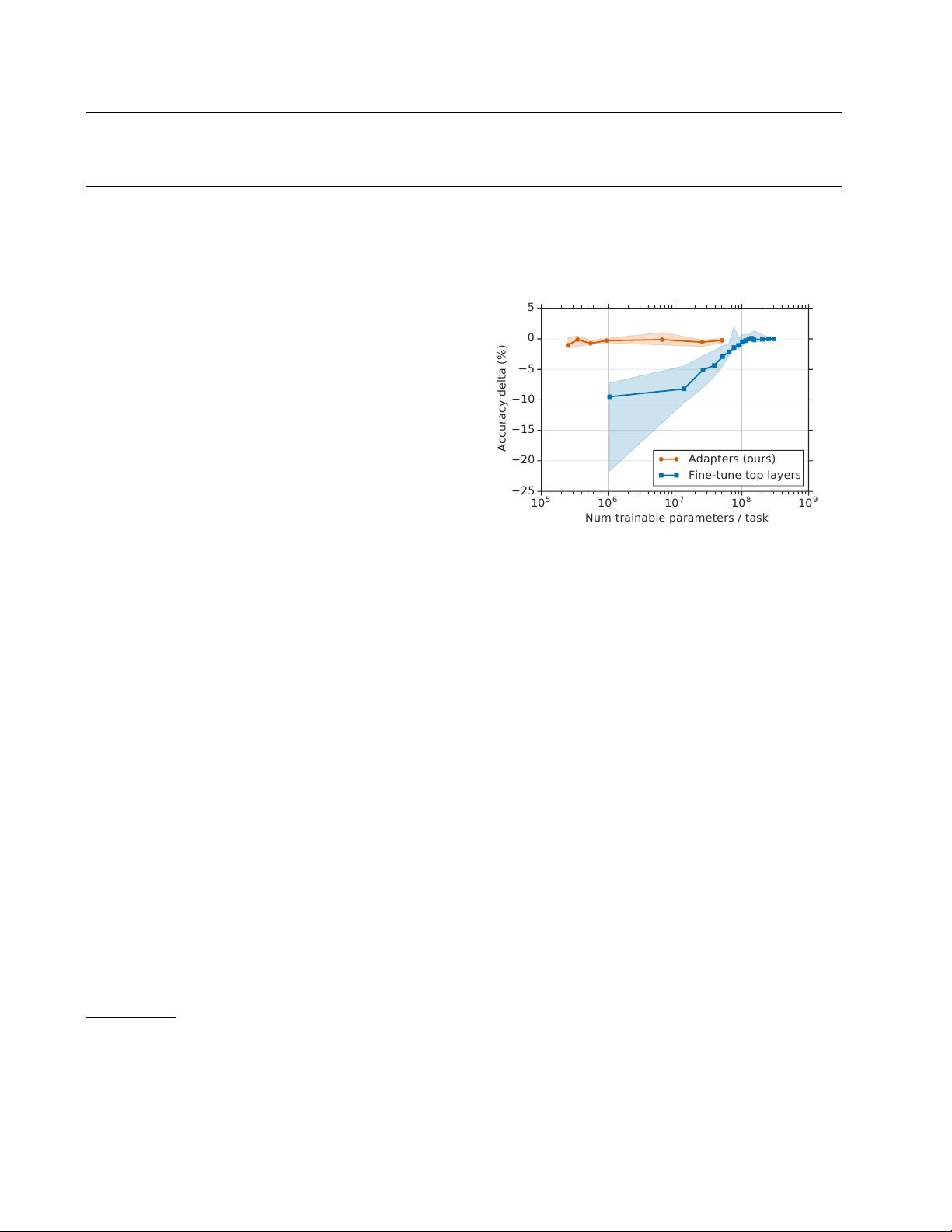
Figure 1.
Trade-off between accuracy and number of trained task-
specific parameters, for adapter tuning and fine-tuning. The y-axis
is normalized by the performance of full fine-tuning, details in
Section 3. The curves show the
20
th,
50
th, and
80
th performance
percentiles across nine tasks from the GLUE benchmark. Adapter-
based tuning attains a similar performance to full fine-tuning with
two orders of magnitude fewer trained parameters.
tasks that arrive from customers in sequence. For this, we
propose a transfer learning strategy that yields compact and
extensible downstream models. Compact models are those
that solve many tasks using a small number of additional
parameters per task. Extensible models can be trained in-
crementally to solve new tasks, without forgetting previous
ones. Our method yields a such models without sacrificing
performance.
The two most common transfer learning techniques in NLP
are feature-based transfer and fine-tuning. Instead, we
present an alternative transfer method based on adapter
modules (Rebuffi et al., 2017). Features-based transfer in-
volves pre-training real-valued embeddings vectors. These
embeddings may be at the word (Mikolov et al., 2013), sen-
tence (Cer et al., 2019), or paragraph level (Le & Mikolov,
2014). The embeddings are then fed to custom downstream
models. Fine-tuning involves copying the weights from a
pre-trained network and tuning them on the downstream
task. Recent work shows that fine-tuning often enjoys better
performance than feature-based transfer (Howard & Ruder,
2018).
下载后可阅读完整内容,剩余9页未读,立即下载
2018-10-06 上传
2018-10-18 上传
2024-04-06 上传
2018-10-06 上传
2019-08-22 上传
2021-02-03 上传
2024-03-07 上传
2021-03-19 上传

FelaniaLiu
- 粉丝: 31
- 资源: 332
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
