ARM Neon SIMD指令集参考:ACLEQ32020版
需积分: 36 82 浏览量
更新于2024-07-09
1
收藏 4.04MB PDF 举报
ARM Neon Intrinsics是专为ARM架构设计的一种高级SIMD(Single Instruction Multiple Data)指令集,它在 Armv8架构中引入,旨在提升处理器的性能,特别是在处理并行计算和数据密集型任务时。这些内建指令允许开发人员利用ARM NEON(单指令流多数据流)硬件加速,实现对128位单精度浮点数和整数数据的高效操作。
该文档《NEON-intrinsics.pdf》详细介绍了ARM NEON Intrinsics的功能、用法和更新历史,从最早的版本ACLEQ12019到ACLEQ32020,反映了其不断演进以适应新版本的ARM架构(如ARMv8.1)。ArmNeonIntrinsics Reference文档涵盖了诸如向量运算(vector arithmetic)、数据移动(data movement)、逻辑与比较(logical and comparison)、转换(conversion)以及控制流程(control flow)等方面的一系列内核函数。
在使用这些内建函数时,开发者可以编写更加简洁、高效的代码,比如进行快速的矩阵乘法、快速傅里叶变换(FFT)等高性能计算任务。然而,值得注意的是,ArmNeonIntrinsics并非适用于所有ARM处理器,只有支持NEON扩展的处理器(如 Cortex-A系列)才能充分利用这些功能。
文档还强调了版权和保密性问题,指出这份文档受版权保护,可能涉及专利权,因此任何实施或使用其中技术的行为都需遵循相应的授权协议。对于开发者而言,在使用这些内建指令时,不仅要注意性能优化,还要确保遵循版权规定,避免侵犯知识产权。
ARM Neon Intrinsics是现代ARM架构下提高性能的关键工具,对于那些寻求在移动设备和嵌入式系统中实现高性能计算的工程师来说,理解和掌握这一特性至关重要。随着技术的迭代更新,开发者应关注最新的文档以获取最新的指令集和最佳实践。
Arm Neon Intrinsics Reference
IHI 0073G
Copyright © 2014 - 2020 Arm Limited (or its affiliates). All rights reserved.
Non-Confidential
Page 16 of 185
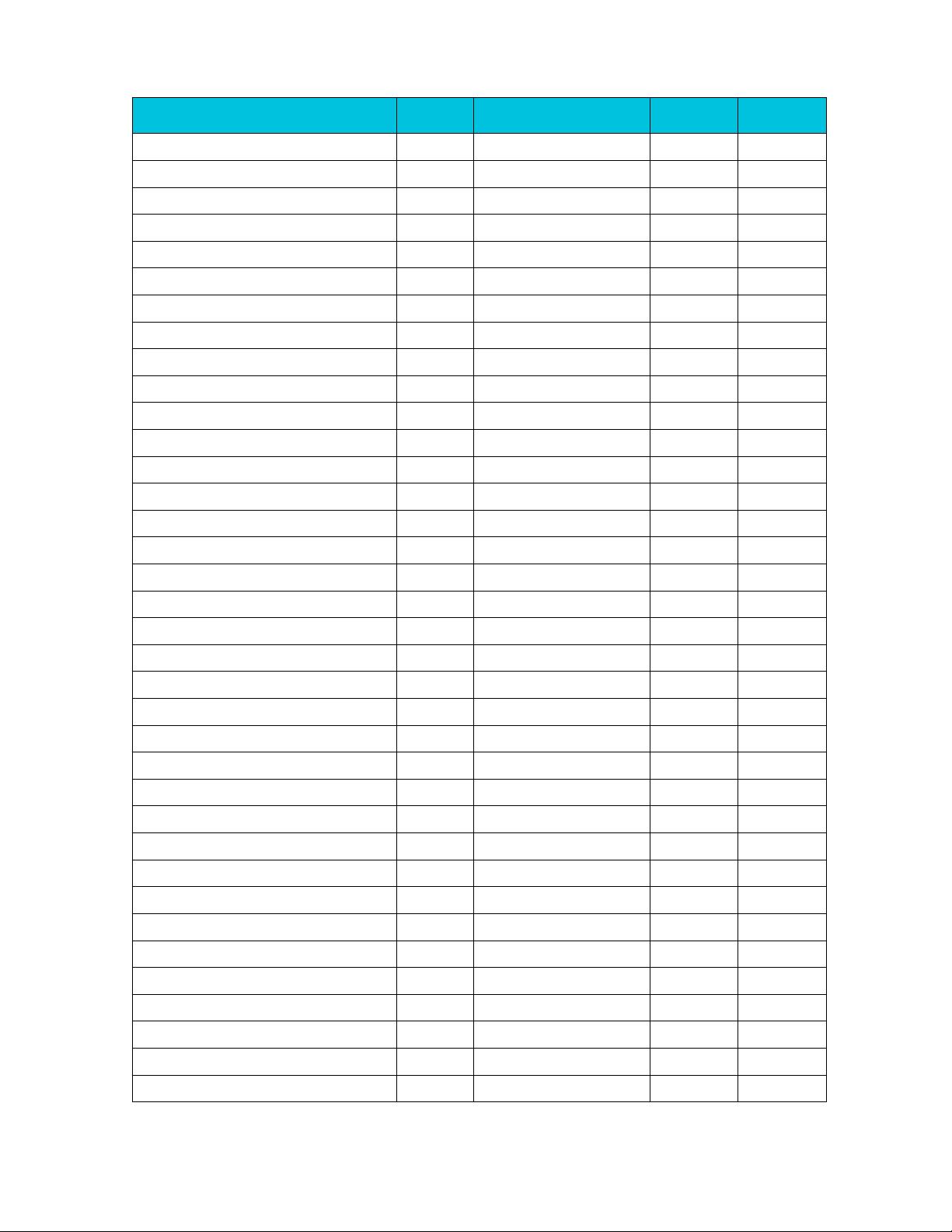
Intrinsic
Argument
Preparation
Instruction
Result
Supported
Architectures
poly16x8_t vmull_high_p8(poly8x16_t a, poly8x16_t
b)
a -> Vn.16B
b -> Vm.16B
PMULL2 Vd.8H,Vn.16B,Vm.16B
Vd.8H -> result
A64
int32x4_t vqdmull_s16(int16x4_t a, int16x4_t b)
a -> Vn.4H
b -> Vm.4H
SQDMULL Vd.4S,Vn.4H,Vm.4H
Vd.4S -> result
v7/A32/A64
int64x2_t vqdmull_s32(int32x2_t a, int32x2_t b)
a -> Vn.2S
b -> Vm.2S
SQDMULL Vd.2D,Vn.2S,Vm.2S
Vd.2D -> result
v7/A32/A64
int32_t vqdmullh_s16(int16_t a, int16_t b)
a -> Hn
b -> Hm
SQDMULL Sd,Hn,Hm
Sd -> result
A64
int64_t vqdmulls_s32(int32_t a, int32_t b)
a -> Sn
b -> Sm
SQDMULL Dd,Sn,Sm
Dd -> result
A64
int32x4_t vqdmull_high_s16(int16x8_t a, int16x8_t b)
a -> Vn.8H
b -> Vm.8H
SQDMULL2 Vd.4S,Vn.8H,Vm.8H
Vd.4S -> result
A64
int64x2_t vqdmull_high_s32(int32x4_t a, int32x4_t b)
a -> Vn.4S
b -> Vm.4S
SQDMULL2 Vd.2D,Vn.4S,Vm.4S
Vd.2D -> result
A64
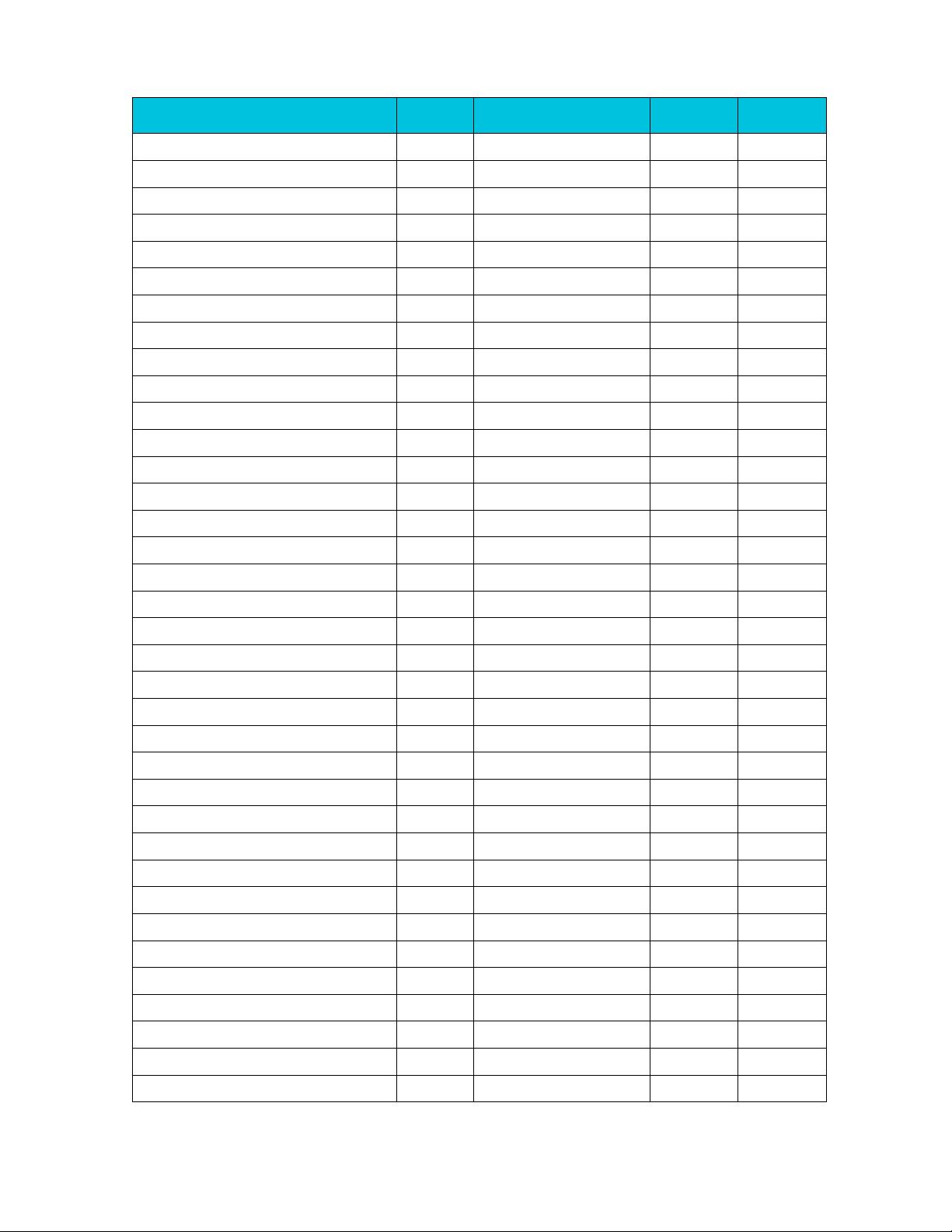
int8x8_t vsub_s8(int8x8_t a, int8x8_t b)
a -> Vn.8B
b -> Vm.8B
SUB Vd.8B,Vn.8B,Vm.8B
Vd.8B -> result
v7/A32/A64
int8x16_t vsubq_s8(int8x16_t a, int8x16_t b)
a -> Vn.16B
b -> Vm.16B
SUB Vd.16B,Vn.16B,Vm.16B
Vd.16B ->
result
v7/A32/A64
int16x4_t vsub_s16(int16x4_t a, int16x4_t b)
a -> Vn.4H
b -> Vm.4H
SUB Vd.4H,Vn.4H,Vm.4H
Vd.4H -> result
v7/A32/A64
int16x8_t vsubq_s16(int16x8_t a, int16x8_t b)
a -> Vn.8H
b -> Vm.8H
SUB Vd.8H,Vn.8H,Vm.8H
Vd.8H -> result
v7/A32/A64
int32x2_t vsub_s32(int32x2_t a, int32x2_t b)
a -> Vn.2S
b -> Vm.2S
SUB Vd.2S,Vn.2S,Vm.2S
Vd.2S -> result
v7/A32/A64
int32x4_t vsubq_s32(int32x4_t a, int32x4_t b)
a -> Vn.4S
b -> Vm.4S
SUB Vd.4S,Vn.4S,Vm.4S
Vd.4S -> result
v7/A32/A64
int64x1_t vsub_s64(int64x1_t a, int64x1_t b)
a -> Dn
b -> Dm
SUB Dd,Dn,Dm
Dd -> result
v7/A32/A64
int64x2_t vsubq_s64(int64x2_t a, int64x2_t b)
a -> Vn.2D
b -> Vm.2D
SUB Vd.2D,Vn.2D,Vm.2D
Vd.2D -> result
v7/A32/A64
uint8x8_t vsub_u8(uint8x8_t a, uint8x8_t b)
a -> Vn.8B
b -> Vm.8B
SUB Vd.8B,Vn.8B,Vm.8B
Vd.8B -> result
v7/A32/A64
uint8x16_t vsubq_u8(uint8x16_t a, uint8x16_t b)
a -> Vn.16B
b -> Vm.16B
SUB Vd.16B,Vn.16B,Vm.16B
Vd.16B ->
result
v7/A32/A64
uint16x4_t vsub_u16(uint16x4_t a, uint16x4_t b)
a -> Vn.4H
b -> Vm.4H
SUB Vd.4H,Vn.4H,Vm.4H
Vd.4H -> result
v7/A32/A64
uint16x8_t vsubq_u16(uint16x8_t a, uint16x8_t b)
a -> Vn.8H
b -> Vm.8H
SUB Vd.8H,Vn.8H,Vm.8H
Vd.8H -> result
v7/A32/A64
uint32x2_t vsub_u32(uint32x2_t a, uint32x2_t b)
a -> Vn.2S
b -> Vm.2S
SUB Vd.2S,Vn.2S,Vm.2S
Vd.2S -> result
v7/A32/A64
uint32x4_t vsubq_u32(uint32x4_t a, uint32x4_t b)
a -> Vn.4S
b -> Vm.4S
SUB Vd.4S,Vn.4S,Vm.4S
Vd.4S -> result
v7/A32/A64
uint64x1_t vsub_u64(uint64x1_t a, uint64x1_t b)
a -> Dn
b -> Dm
SUB Dd,Dn,Dm
Dd -> result
v7/A32/A64
uint64x2_t vsubq_u64(uint64x2_t a, uint64x2_t b)
a -> Vn.2D
b -> Vm.2D
SUB Vd.2D,Vn.2D,Vm.2D
Vd.2D -> result
v7/A32/A64
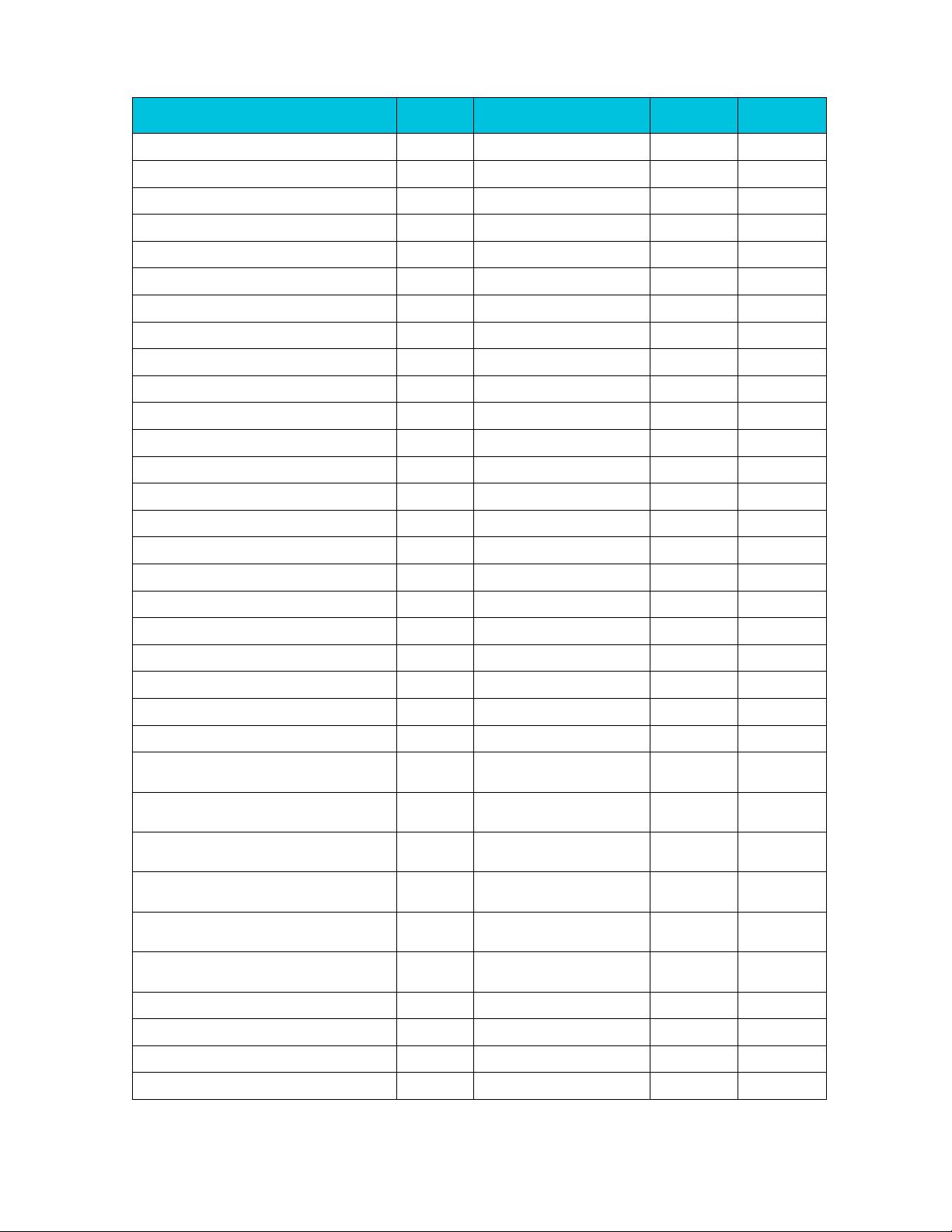
float32x2_t vsub_f32(float32x2_t a, float32x2_t b)
a -> Vn.2S
b -> Vm.2S
FSUB Vd.2S,Vn.2S,Vm.2S
Vd.2S -> result
v7/A32/A64
float32x4_t vsubq_f32(float32x4_t a, float32x4_t b)
a -> Vn.4S
b -> Vm.4S
FSUB Vd.4S,Vn.4S,Vm.4S
Vd.4S -> result
v7/A32/A64
float64x1_t vsub_f64(float64x1_t a, float64x1_t b)
a -> Dn
b -> Dm
FSUB Dd,Dn,Dm
Dd -> result
A64
float64x2_t vsubq_f64(float64x2_t a, float64x2_t b)
a -> Vn.2D
b -> Vm.2D
FSUB Vd.2D,Vn.2D,Vm.2D
Vd.2D -> result
A64
int64_t vsubd_s64(int64_t a, int64_t b)
a -> Dn
b -> Dm
SUB Dd,Dn,Dm
Dd -> result
A64
uint64_t vsubd_u64(uint64_t a, uint64_t b)
a -> Dn
b -> Dm
SUB Dd,Dn,Dm
Dd -> result
A64
int16x8_t vsubl_s8(int8x8_t a, int8x8_t b)
a -> Vn.8B
b -> Vm.8B
SSUBL Vd.8H,Vn.8B,Vm.8B
Vd.8H -> result
v7/A32/A64
int32x4_t vsubl_s16(int16x4_t a, int16x4_t b)
a -> Vn.4H
b -> Vm.4H
SSUBL Vd.4S,Vn.4H,Vm.4H
Vd.4S -> result
v7/A32/A64
int64x2_t vsubl_s32(int32x2_t a, int32x2_t b)
a -> Vn.2S
b -> Vm.2S
SSUBL Vd.2D,Vn.2S,Vm.2S
Vd.2D -> result
v7/A32/A64
uint16x8_t vsubl_u8(uint8x8_t a, uint8x8_t b)
a -> Vn.8B
b -> Vm.8B
USUBL Vd.8H,Vn.8B,Vm.8B
Vd.8H -> result
v7/A32/A64
uint32x4_t vsubl_u16(uint16x4_t a, uint16x4_t b)
a -> Vn.4H
b -> Vm.4H
USUBL Vd.4S,Vn.4H,Vm.4H
Vd.4S -> result
v7/A32/A64
uint64x2_t vsubl_u32(uint32x2_t a, uint32x2_t b)
a -> Vn.2S
b -> Vm.2S
USUBL Vd.2D,Vn.2S,Vm.2S
Vd.2D -> result
v7/A32/A64
int16x8_t vsubl_high_s8(int8x16_t a, int8x16_t b)
a -> Vn.16B
b -> Vm.16B
SSUBL2 Vd.8H,Vn.16B,Vm.16B
Vd.8H -> result
A64


剩余184页未读,继续阅读
2017 浏览量
199 浏览量
2022-07-13 上传
287 浏览量
2024-07-17 上传
235 浏览量
105 浏览量

Pasding
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- GNU/Linux操作系统线程库glibc-linuxthreads解析
- Java实现模拟淘宝登录的方法与工具库解析
- Arduino循迹智能小车DIY电路制作与实现
- Android小鱼儿游戏源码:重力感应全支持
- ScalaScraper:Scala HTML内容抽取神器解析
- Angular CLI基础:创建英雄角游项目与运行指南
- 建筑隔振降噪技术新突破:一种橡胶支座介绍
- 佳能MG6880多功能一体机官方驱动v5.9.0发布
- HTML4 自适应布局设计与应用
- GNU glibc-libidn库压缩包解析指南
- 设备装置行业开发平台的应用与实践
- ENVI 5.1发布:新功能与改进亮点概述
- 实现IOS消息推送的JAVA依赖包与实例解析
- Node.js 新路由的设计与实现
- 掌握SecureCRT与FileZilla:高效Linux工具使用指南
- CMDAssist V1.0.10:简化操作的快捷键管理工具
