2020 MathorCup大数据竞赛赛道A优秀论文:基站流量分类与特征提取
需积分: 0 154 浏览量
更新于2023-12-27
收藏 3.31MB PDF 举报
2020年MathorCup大数据竞赛赛道A优秀论文21在时间序列特征提取与分类方面取得了显著的成果。该论文团队编号335赛道(A)通过基于Kmeans和Kshape、LSTM和Cornish-Fisher展式的基站流量分类与阈值设定研究,实现了对相关小区的历史流量数据进行时间序列特征的提取并进行“小区”分类,并描述了每类的特点。
论文中提到,题目要求需要基于相关小区的历史流量数据提取时间序列数据特征进行“小区”分类,并描述每类的特点。但由于题目所提供的数据过于庞大,直接对原始数据进行清洗并在处理后的原始数据基础上进行数学建模会导致时间效率与处理机器性能的限制,因此该团队考虑随机抽取3万个小区作为训练测试样本集进行初步聚类分析,再基于改进的KNN算法将剩余样本小区归为与其距离最近的类别。
论文的聚类流程主要包括以下几步:第一步是对原始数据进行数据预处理,采取随机抽样获得测试用样本小区数据集;第二步利用tsfresh工具提取时间序列的统计特征、熵特征和分段特征等作为对应的特征向量进行聚类,得到特征向量F。同时,基于随机森林法对构成的特征向量各个特征之间的重要性进行分析;第三步根据轮廓系数和肘部法则获取最优聚类数,再利用kmeans方法进行基于特征向量的聚类分析。
该论文的创新之处在于通过对大量原始数据进行随机抽样的方式,避免了数据处理过程中的时间和性能限制问题。同时,基于tsfresh工具提取了多种时间序列特征,通过随机森林法对特征重要性进行分析,得到了更加全面的特征向量,为后续的聚类分析提供了更加可靠的数据基础。最终通过优化的KNN算法对剩余的样本小区进行了分类,实现了对所有小区的时间序列特征提取与分类。
总的来说,该论文在大数据竞赛赛道A上取得了显著的成就,为时间序列数据的特征提取与分类问题提供了一种新的解决思路,对于类似的大规模时间序列数据分析问题具有一定的借鉴意义。
第 6 页 共 43 页
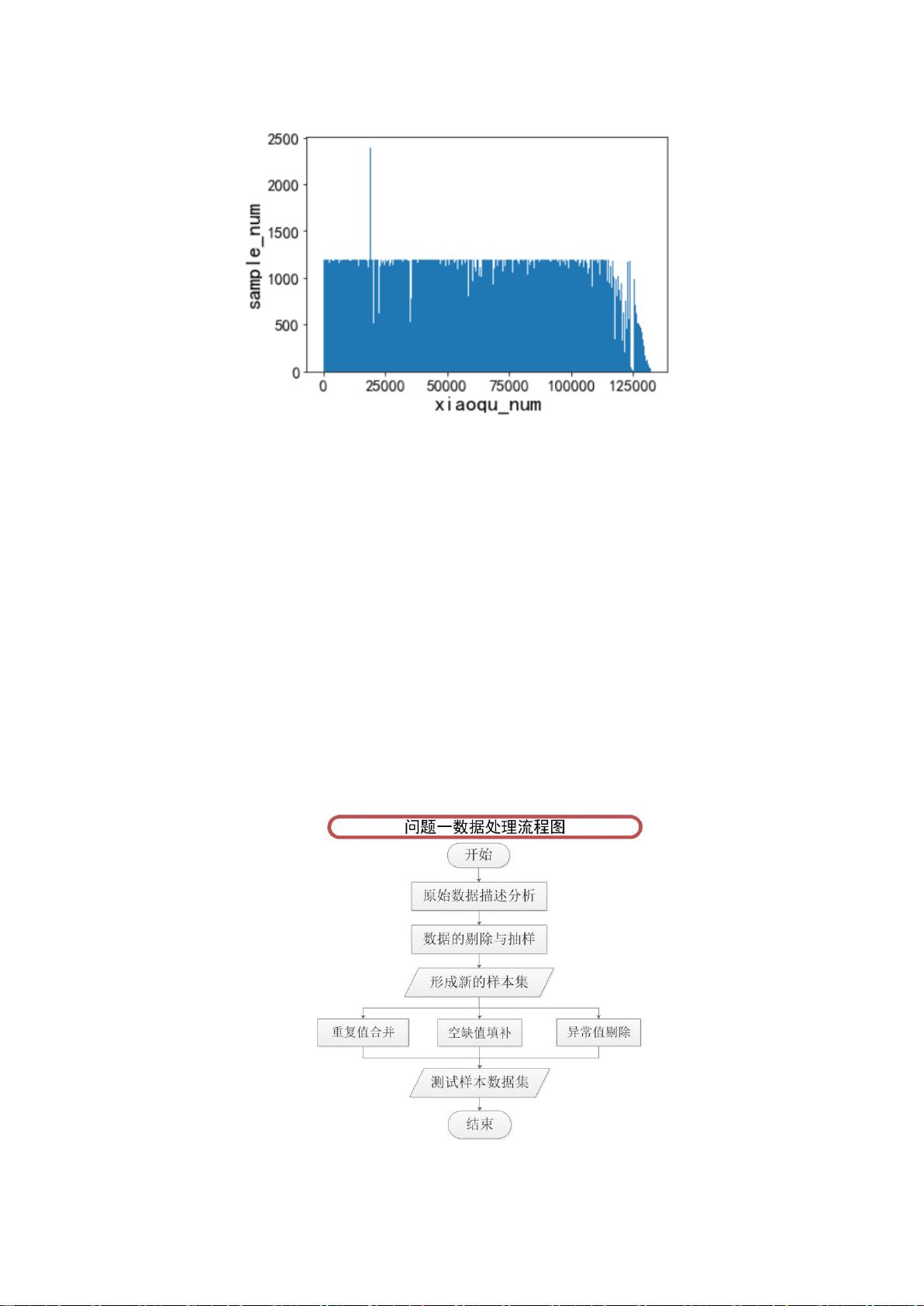
图 5.1 各小区样本数据量分布直方图
5.1.2 样本数据清洗
此外,可发现题目所给附件的数据量过于庞大。基于处理效率与机器运行性能的考
量,本文从所有小区中随机抽取 30000 个小区作为样本集进行特征提取和聚类分析。同
时,对其采取进一步的数据清洗与处理。针对随机抽取的 30000 个小区进一步的分析,
发现部分小区数据仍然存在较多缺失值,且不同小区缺失值存在的时间点不同。其中,
对于所有小区 4 月 15 号当天所有数据均缺失。基于同一小区在相邻日期内无显著差异
的假设,针对空缺值本文选用同一时刻相邻日期的流量均值来填补。对数据样本重复情
况进行统计分析可知,共有 23 个小区样本量大于 2000,通过 python 中 pandas 库自带
的函数删除重复值。对于异常值,删除后同样用同一时刻相邻日期的流量均值填补,数
据预处理流程图如图 5.2 所示。
图 5.2 数据预处理流程图

剩余44页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传

BellWang
- 粉丝: 28
- 资源: 315
 我的内容管理
展开
我的内容管理
展开







最新资源
- PyPI 官网下载 | luma.oled-3.2.0-py2.py3-none-any.whl
- 【推荐】城市云数据大屏
- NDISCfg.zip_网络编程_Visual_C++_
- 重点:受鲍里斯启发的程序,通过对视频的视觉检查来记录观察结果
- notes-client:用React编写的Markdown编辑器
- 微博小助手-crx插件
- notes-python:中文Python笔记
- nitpick-styles:nitpick样式的集合
- 教育科研-学习工具-一种COG邦定机对位平台.zip
- pycrashcourse:这是Python Crash Course的存储库
- Hide That-crx插件
- node-rplidar
- 多选按钮代码matlab-guyezi.github.io:IT日志:http://guyezi.github.io或
- BOTBUKI
- sassy-exists:Sass中的实体检查
- 6-1JavaJDBC.rar_Java编程_Java_
