深入理解Kafka:复制、请求处理与存储机制解析
133 浏览量
更新于2024-07-15
收藏 2.87MB PDF 举报
"本文将深入探讨Kafka的复制机制、请求处理方式以及存储细节,帮助读者理解Kafka的内部工作原理,以便更好地开发和维护Kafka应用。文章还将涉及Kafka与ZooKeeper的协作,解释如何通过ZooKeeper管理集群中的关系。"
Kafka是一个分布式流处理平台,其强大的功能和高吞吐量使其在大数据处理领域广泛使用。Kafka的核心特性之一是它的数据复制,这保证了数据的可用性和容错性。Kafka的复制是基于分区(Partition)的,每个分区都有一个主副本和多个副本,主副本负责接收和处理生产者和消费者的请求,其他副本则作为备份,一旦主副本失效,其中一个备份副本将接管成为新的主副本。
Kafka处理来自生产者和消费者的请求是异步的,生产者将消息发送到特定主题的分区,而消费者则可以从这些分区中消费消息。Kafka使用高效的批量生产和消费策略,允许一次性发送或接收大量消息,从而提高了效率。此外,Kafka还支持acks机制,生产者可以设置不同级别的确认,以平衡可靠性和性能。
在存储细节方面,Kafka将消息存储在磁盘上,并且通过日志压缩(Log Compaction)等技术管理数据。每个分区的日志由一系列消息组成,每个消息都有一个唯一的序列号(offset),用于追踪和定位消息。Kafka会定期清理旧消息,以保持数据存储的大小可控。
ZooKeeper在Kafka中的作用至关重要,它负责元数据管理,包括主题、分区和broker的配置信息。每个broker在ZooKeeper中注册,通过/brokers/ids路径下的临时节点表示其状态。当broker加入或离开集群时,ZooKeeper会自动更新集群状态,确保生产者和消费者能发现可用的broker。
Kafka集群的扩展性和高可用性离不开ZooKeeper的支持。在集群中,多个生产者和消费者可以通过ZooKeeper协调工作,确定消息的处理顺序和负载均衡。每个broker的唯一标识是broker.id,它在ZooKeeper中注册,确保集群成员间的唯一性和一致性。
总结来说,了解Kafka的内部工作原理,包括复制机制、请求处理和存储细节,对于优化性能、排查问题和设计高可用系统至关重要。通过ZooKeeper的协助,Kafka能够实现高效的集群管理和故障恢复,确保数据的可靠传输和处理。因此,无论是开发者还是运维人员,深入理解这些原理都将对实际工作大有裨益。
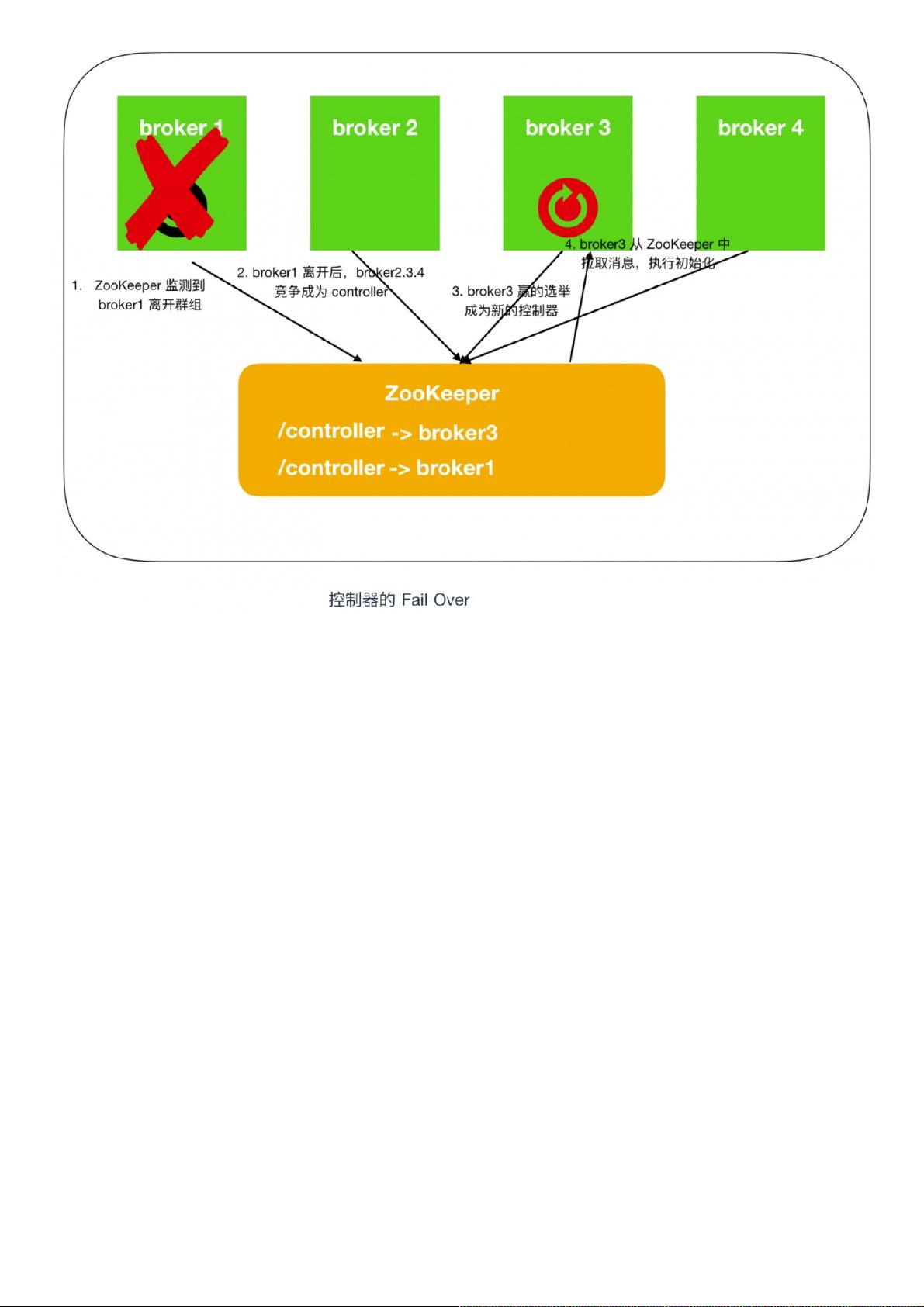
最一开始,broker1 会抢先注册成功成为 controller,然后由于网络抖动或者其他原因致使 broker1 掉线,ZooKeeper 通过 Watch 机制觉察到 broker1 的掉线,之后所有存活的
brokers 开始竞争成为 controller,这时 broker3 抢先注册成功,此时 ZooKeeper 存储的 controller 信息由 broker1 -> broker3,之后,broker3 会从 ZooKeeper 中读取元数据信息,
并初始化到自己的缓存中。
注意:ZooKeeper 中存储的不是缓存信息,broker 中存储的才是缓存信息。
broker controller 存在的问题存在的问题
在 Kafka 0.11 版本之前,控制器的设计是相当繁琐的。我们上面提到过一句话:Kafka controller 被设计为一种模拟状态机的多线程控制器,这种设计其实是存在一些问题的
controller 状态的更改由不同的监听器并罚执行,因此需要进行很复杂的同步,并且容易出错而且难以调试。状态传播不同步,broker 可能在时间不确定的情况下出现多种状态,这会
导致不必要的额外的数据丢失controller 控制器还会为主题删除创建额外的 I/O 线程,导致性能损耗controller 的多线程设计还会访问共享数据,我们知道,多线程访问共享数据是线
程同步最麻烦的地方,为了保护数据安全性,控制器不得不在代码中大量使用ReentrantLock 同步机制同步机制,这就进一步拖慢了整个控制器的处理速度。broker controller 内部设计原理内部设计原理
在 Kafka 0.11 之后,Kafka controller 采用了新的设计,把多线程的方案改成了单线程加事件队列的方案把多线程的方案改成了单线程加事件队列的方案。如下图所示
剩余17页未读,继续阅读
1447 浏览量
340 浏览量
225 浏览量
282 浏览量
458 浏览量
102 浏览量
800 浏览量

weixin_38611877
- 粉丝: 5
- 资源: 925
 我的内容管理
展开
我的内容管理
展开







最新资源
- computer-vision:我以前和正在进行的计算机视觉领域的小型项目的集合
- matlab代码做游戏-Graphics-Projects:我已经完成的与图形编程相关的项目
- OpenCV3计算机视觉python语言实现.zip
- 钢结构施工组织设计-钢结构吊装方案
- 显控HMI连接4站变频器示例.rar
- ICLR2019-OpenReviewData:从ICLR OpenReview网页抓取元数据的脚本。 在Ubuntu上安装和使用Selenium和ChromeDriver的教程
- Isabelle:与定理证明有关的代码
- Covid-19-info
- phaser-plugin-game-gui:检查和操纵一些常见的游戏设置。 移相器2CE
- extract-video-keyframe:提取视频中的关键帧以进行处理以存储在其他位置
- 基于多线性结构光的标定方法
- mysql-5.6.10-win32.zip
- strongbox-web-ui:这是Strongbox工件存储库管理器的UI模块。 请在https报告问题
- 基于GEC6818智能家居项目包.zip
- chaoscosmos.online:chaoscosmos.online网站
- 混凝土工程施工组织设计-CECS02-88超声回弹综合法检测混凝土强度技术规程
