2022年Kaggle竞赛:常见交叉验证陷阱及策略
需积分: 0 154 浏览量
更新于2024-08-03
收藏 310KB PDF 举报
标题《2022-11-29 交叉验证常见的6个错误.pdf》是一篇关于机器学习竞赛和人工智能咨询中的关键知识点,主要关注于交叉验证这一重要技术的正确应用和常见误区。交叉验证是评估模型性能和防止过拟合的有效工具,它通过将数据集划分为多个互斥的子集来进行模型训练和验证,从而提供更为准确和稳定的模型性能评估。
1. **错误1:选择错误的折数(K值)**
K值决定着数据集被分成的份数,用于执行交叉验证的轮数。理想的K值通常设置为5,因为它提供了足够的多样性以减少偏差,同时避免过度训练。较小的K值可能导致验证集偏差较大,而较大的K值虽然能减小偏差,但计算成本增加。在实践中,应根据数据规模和实验需求尝试不同的K值,并观察模型精度是否稳定。
2. **错误2:数据分布不同**
保证训练集和验证集之间的标签分布一致性是关键。标准的交叉验证如KFold可能会导致样本分布失衡。StratifiedKFold被推荐用于处理类别不平衡的数据,确保每个折叠都有相同比例的各类别样本。对于复杂情况下,如数值标签或多标签问题,可能需要进一步的处理,例如离散化和分箱后使用StratifiedKFold。
3. **其他可能的错误和注意事项**
- **数据划分策略**:除了标签分布,还需要考虑其他因素,如对照组、数值标签等,可能需要 StratifiedGroupKFold来适应这些特殊场景。
- **模型训练和验证**:每次折叠后都要独立训练模型,并用该折叠留出的数据进行验证,以确保所有数据都被充分利用。
- **性能评估**:交叉验证的结果通常以平均精度或其他评估指标来衡量,这有助于理解模型的泛化能力。
总结,这篇文档详述了在使用交叉验证时需要避免的陷阱,包括如何合理选择K值、确保数据分布的一致性,以及针对不同类型数据进行适当的划分。理解和避免这些错误对于提高机器学习模型的准确性和可靠性至关重要。
交叉验证常见的6个错误
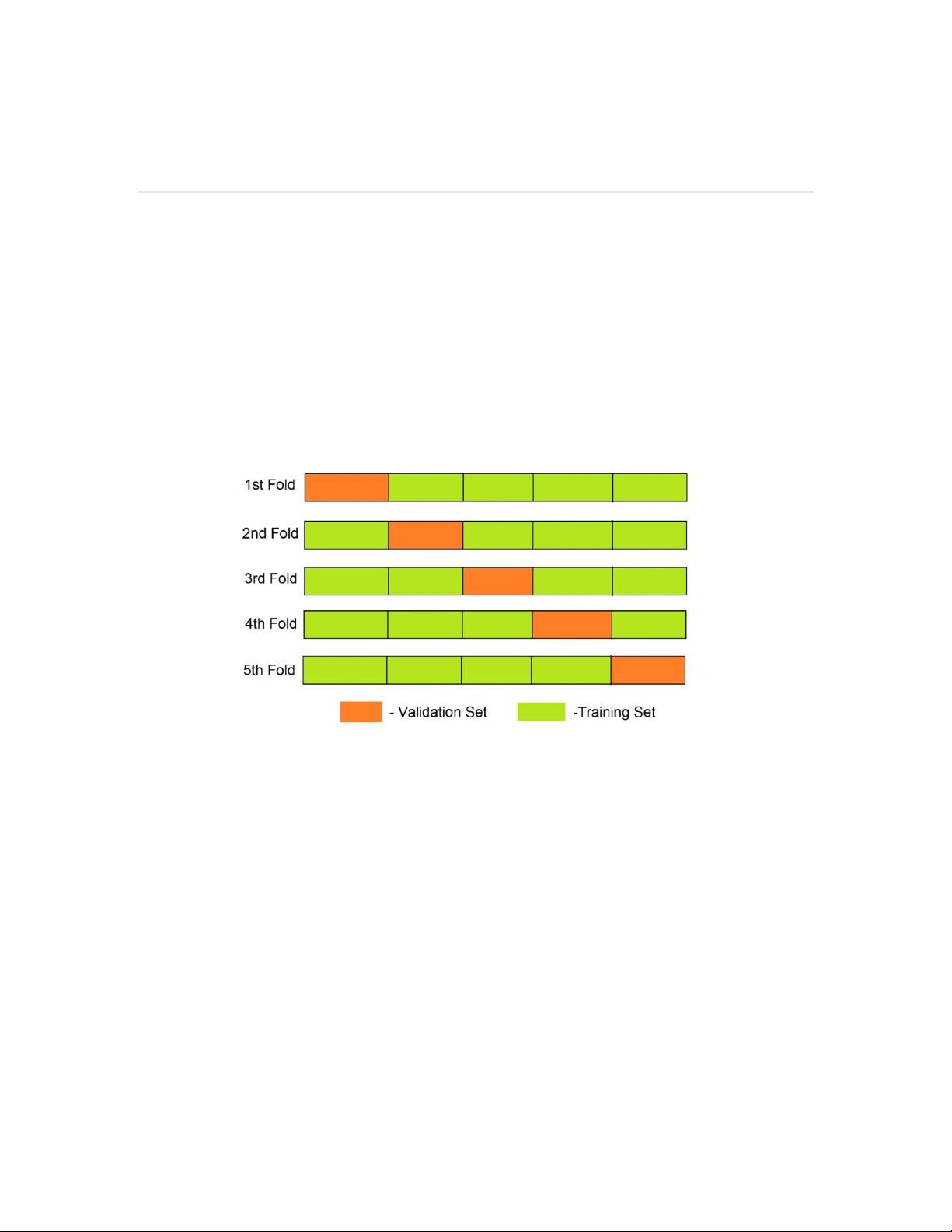
交叉验证(Cross-
Validation)是验证模型有效性的方法,具体的实践流程如下:
步骤1:数据集划分为K份,其中K-
1份作为训练集,剩余1份作为验证集。
步骤2:训练集并记录验证集精度。
步骤3:将操作上述循环K次。
交叉验证与按照比例划分的方法,与如下优点:
交叉验证可以验证模型多次,减少了模型误差中的偏差,验证集精度更
加可信。
交叉验证可以得到多个模型,在测试集上可以进行多次预测,增加预测
结果的多样性。
错误1:选择错误的折数
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-09-14 上传
2021-04-30 上传
2020-07-23 上传
2022-10-11 上传
2019-12-01 上传
2018-04-15 上传

毕业小助手
- 粉丝: 2761
- 资源: 5583
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
