设计链家网站二手房数据爬虫
需积分: 50 2 浏览量
更新于2024-09-06
收藏 1.03MB PDF 举报
“爬取链家网站房屋信息.pdf”
在当今数据驱动的时代,获取网络上的有用信息变得至关重要。链家作为国内知名的房地产交易平台,其网站上包含了大量的二手房房源数据,这对于研究房地产市场、数据分析或者个人购房决策都具有很高的价值。本项目旨在通过编写Python爬虫程序,实现对链家网站(https://sz.lianjia.com/ershoufang/)上所有二手房信息的自动化抓取。
首先,我们需要理解网页结构和HTML元素。在链家网站的二手房页面,每个房源信息都是由一系列HTML标签组成的。例如,一个房源条目可能包括`<a>`标签(链接)、`<img>`标签(图片)以及`<div>`标签(内容容器)。在示例中,房源链接的数据属性如`data-housecode`用于唯一标识房源,图片的`src`属性则指向房源图片的URL,而标题和详细信息则可能在`<div class="infoclear">`内的子元素中。
编写爬虫程序时,我们将使用Python的网络请求库,如`requests`来获取网页源代码,然后使用解析库,如`BeautifulSoup`或`lxml`解析HTML内容。以下是一般的步骤:
1. **设置URL**:根据链家网站的结构,我们需要遍历所有页面,通常页码信息会出现在URL中,如`https://sz.lianjia.com/ershoufang/`后可能跟着页码参数。
2. **发送HTTP请求**:使用`requests.get()`函数获取指定URL的HTML响应。
3. **解析HTML**:利用`BeautifulSoup`解析HTML响应,找到房源信息的标签和属性。
4. **提取数据**:通过CSS选择器或XPath表达式定位到特定的HTML元素,提取`data-housecode`、图片URL、标题等关键信息。
5. **存储数据**:将抓取到的数据存储在文件或数据库中,便于后续分析。可以考虑CSV、JSON或数据库格式,如SQLite。
6. **处理分页**:如果页面有分页,需要循环遍历每一页,直到没有更多房源为止。
7. **异常处理**:考虑到网络问题和网页结构的变化,应添加异常处理机制,确保爬虫的稳定运行。
8. **反爬策略**:链家网站可能有反爬措施,如验证码、IP限制等,我们可能需要使用代理IP、设置延时等方法来规避。
9. **遵守规则**:在进行网络爬虫时,必须遵守网站的robots.txt协议,尊重网站的版权,并且不进行过于频繁的请求,以免对服务器造成负担。
通过以上步骤,我们可以构建一个功能完善的链家二手房信息爬虫,系统地收集和整理深圳地区的房源数据,为进一步的数据分析和应用打下基础。在实际操作中,还需要注意定期更新爬虫,以应对网站结构的可能变化。同时,爬虫编程也需要遵循良好的编程规范,确保代码的可读性和可维护性。
1
爬取链家网站房屋信息
任务:
链家网站 https://sz.lianjia.com/ershoufang/有很多二手房信息,该项目的目标是设计一
个爬虫程序,爬取所有二手房的数据。
一、解析页面
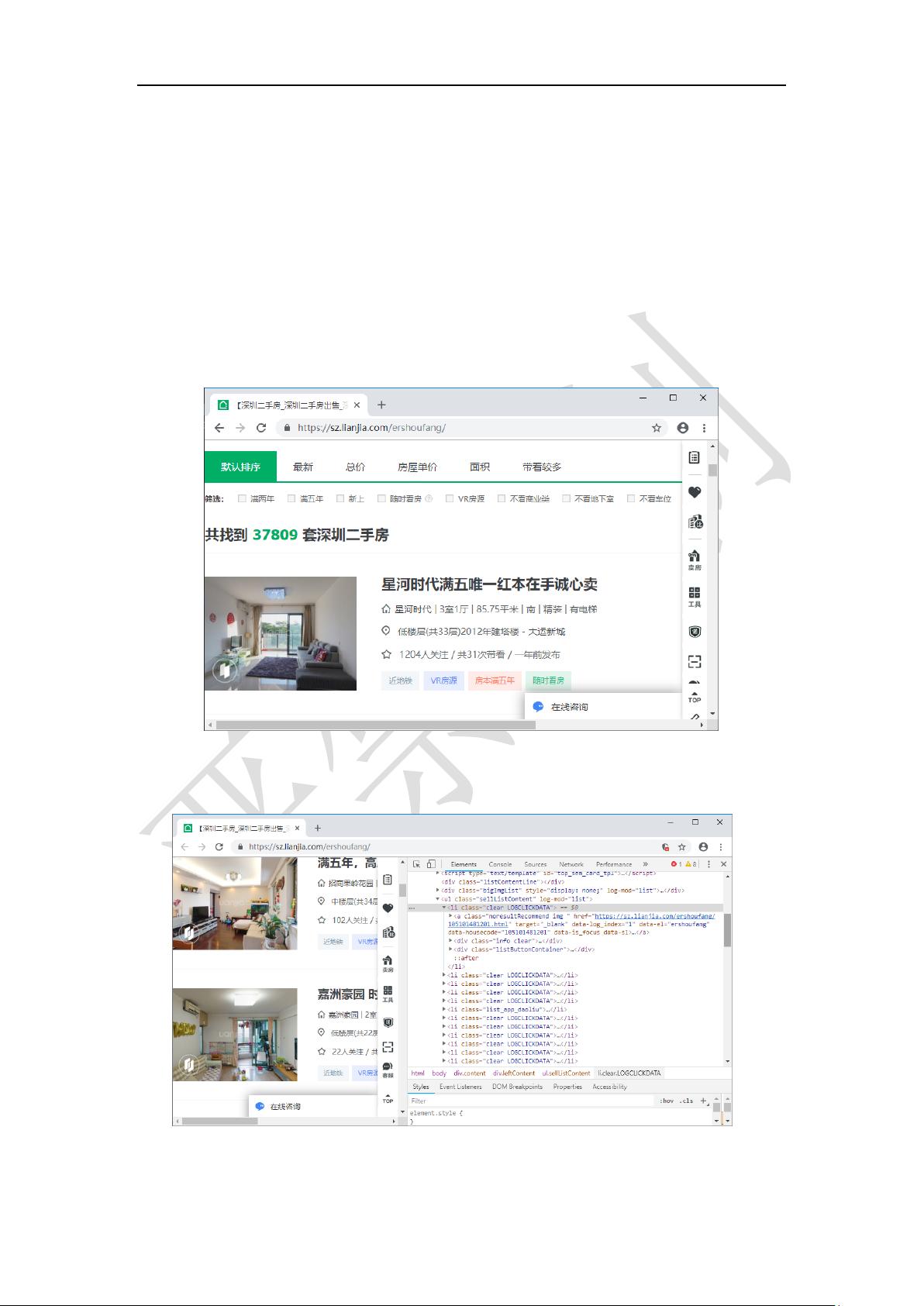
进入链家网站 https://sz.lianjia.com/ershoufang/的二手房栏目,如图 1,可以看见深圳
市的 37809 套房屋的信息。
图 1
查看其中一个的 HTML 代码,如图 2 所示。
图 2
下载后可阅读完整内容,剩余9页未读,立即下载
221 浏览量
214 浏览量
695 浏览量
2021-10-14 上传
118 浏览量
221 浏览量
120 浏览量
155 浏览量

wangyqid
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 安装Oracle必备:unixODBC-2.2.11-7.1.x86_64.rpm
- Spring Boot与Camel XML聚合快速入门教程
- React开发新工具:可拖动、可调整大小的窗口组件
- vlfeat-0.9.14 图像处理库深度解析
- Selenium自动化测试工具深度解析
- ASP.NET房产中介系统:房源信息发布与查询平台
- SuperScan4.1扫描工具深度解析
- 深入解析dede 3.5 Delphi反编译技术
- 深入理解ARM体系结构及编程技巧
- TcpEngine_0_8_0:网络协议模拟与单元测试工具
- Java EE实践项目:在线商城系统演示
- 打造苹果风格的Android ListView实现与下拉刷新
- 黑色质感个人徒步旅行HTML5项目源代码包
- Nuxt.js集成Vuetify模块教程
- ASP.NET+SQL多媒体教室管理系统设计实现
- 西北工业大学嵌入式系统课程PPT汇总
