Python高级数据处理与K-Means聚类实战
需积分: 9 164 浏览量
更新于2024-07-16
收藏 2.55MB PDF 举报
"《6-python高级数据处理与可视化.pdf》是一本针对Python高级数据分析和可视化的教材,主要关注于如何利用Python的强大功能进行数据处理和探索。该书深入介绍了数据处理的基础概念,如聚类分析,特别是K-Means算法,这是一种常用的无监督学习方法,通过将数据集划分为多个基于相似性的簇来发现数据的内在结构。
在K-Means算法中,关键步骤包括:
1. 初始化:随机选择k个数据点作为初始聚类中心。
2. 分配:对于每个数据点,将其分配到与其最近的聚类中心对应的簇。
3. 更新:根据当前簇内的所有点重新计算每个聚类的中心位置。
4. 检查收敛:如果聚类中心不再变化或达到预定迭代次数,算法结束;否则返回步骤2继续迭代。
在提供的代码示例中,首先展示了如何使用`scipy.cluster.vq`库中的`kmeans`函数进行学生分数数据的聚类,将数据分为两组(结果输出为[011101],可能表示学生分别属于两个不同的类别)。接着,由于`scipy.cluster.vq`在更新过程中只支持浮点数,所以在实际应用中,数值需要转换为浮点格式,如`list1=[88.0, 74.0, 96.0, 85.0]`等。
另一个示例是使用K-Means对股票指数数据(如道琼斯工业平均指数,DJI)进行聚类分析,这可以用来分析股市动态或者寻找市场趋势。通过Python的统计和可视化工具,可以将复杂的数据转化为直观易懂的图表,帮助分析师更好地理解和解释数据模式。
《6-python高级数据处理与可视化.pdf》不仅涵盖了Python在数据预处理、清洗、特征工程等方面的知识,还强调了数据可视化的重要性,让读者能够运用Python在实际项目中高效地进行数据挖掘和洞察。无论是初学者还是经验丰富的开发者,都可以从中获取到深入理解和操作高级数据处理技术的宝贵资源。"
Nanjing University
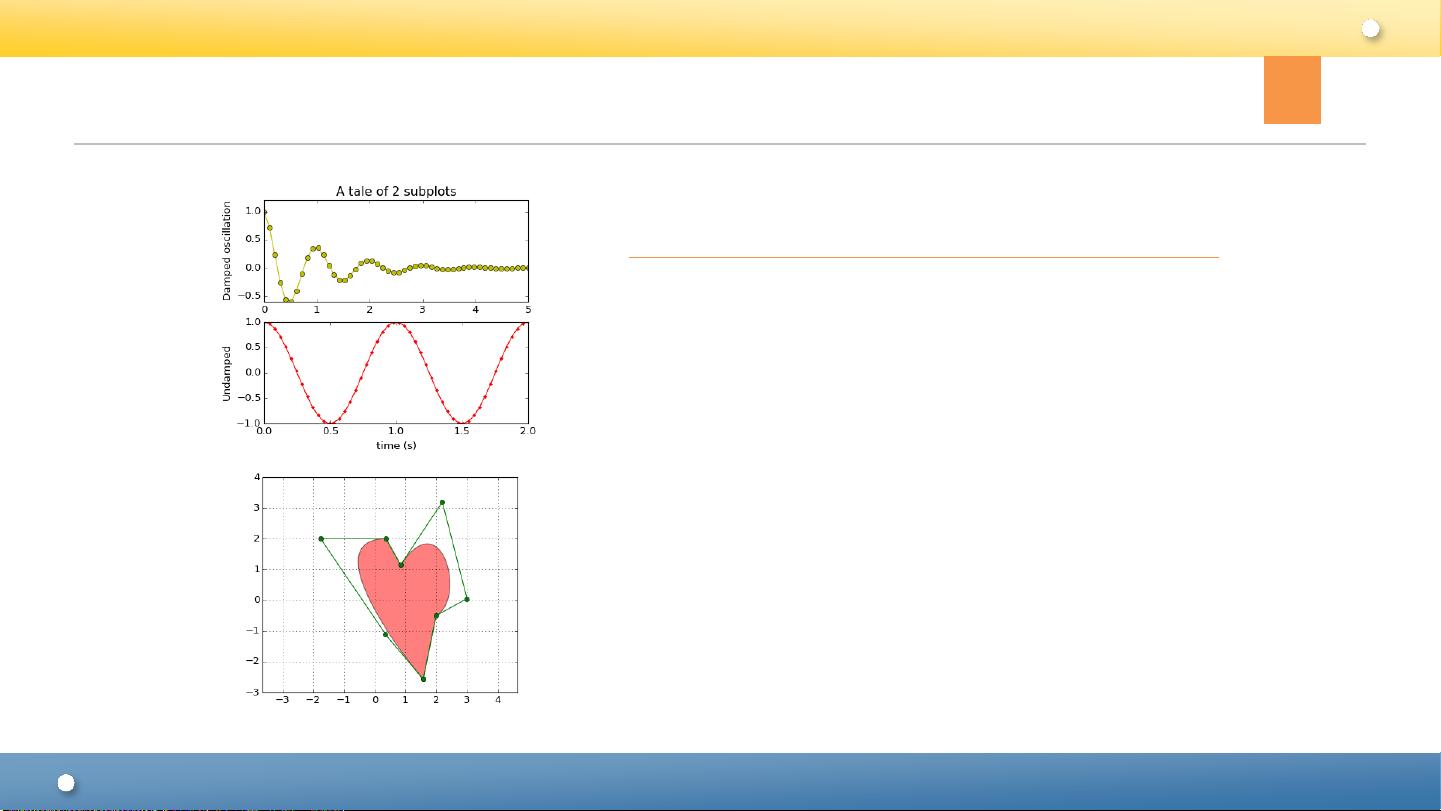
Matplotlib绘图
• Matplotlib绘图
最著名Python绘图库,
主要用于二维绘图
– 画图质量高
– 方便快捷的绘图模块
• 绘图API——pyplot模块
• 集成库——pylab模块(包含NumPy和
pyplot中的常用函数)
9
剩余49页未读,继续阅读
301 浏览量
106 浏览量
252 浏览量
2021-11-27 上传
126 浏览量
1313 浏览量
582 浏览量
230 浏览量

luyan_1987
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- vb.net中ADO.NET数据访问教程:操作UserManage.mdb数据库
- JBoss3.0下EJB配置与部署教程
- JBOSS EJB3.0教程:实战入门与部署详解
- EJB3.0第五版翻译:持久化单元详解
- C++编程规范与最佳实践
- 病毒分析与清除指南:Dropper.Win32.Agent.bd, Trojan.DL.IeFrame, Worm.Win32.Agent
- 整合JSF、Spring与Hibernate:构建JCatalog Web应用
- 在JSP中嵌入多媒体与JavaApplet
- 以太网技术详解:从基础到千兆以太网
- IBM Eclipse RCP教程:构建富客户端应用
- 探索搜索算法实战:从穷举到随机化
- 揭秘常见文件扩展名及打开方法
- Windows操作系统命令大全
- Oracle数据库实用指南:SQL与SQL*PLUS命令速查
- Oracle与MySQL数据库特性比较
- IIS 7与ASP.NET集成编程深度指南
