Python瀑布流爬虫教程:从基础到实战
需积分: 10 22 浏览量
更新于2024-08-26
收藏 4.41MB DOCX 举报
"这是一份关于Python瀑布流爬虫的授课笔记,涵盖了爬虫的基本概念、Python在爬虫中的应用,以及如何实现瀑布流爬虫,包括百度图片的爬取和批量下载图片的实战。此外,还涉及到了爬取360网站图片和哔哩哔哩小视频的实战案例,并布置了封装爬虫模块的作业。"
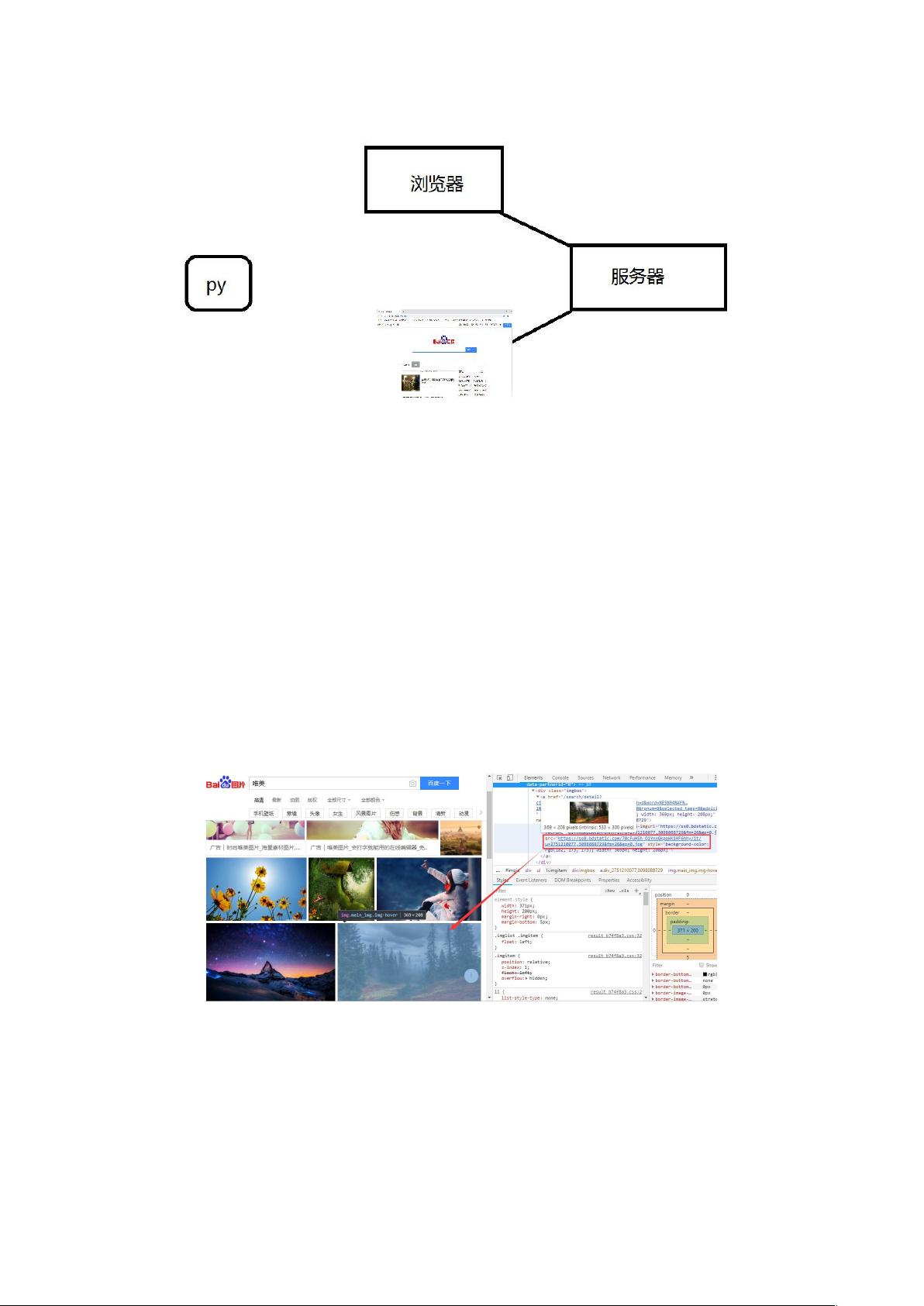
在这份Python瀑布流爬虫的授课笔记中,首先介绍了爬虫的基本知识。爬虫,又称网络蜘蛛,是一种通过脚本自动向服务器发送请求并获取资源的程序。它的主要作用在于数据收集,例如用于数据分析和人工智能,以及模拟操作和接口操作等场景。在实际应用中,当数据量大时,为了提升用户体验和节约服务器资源,通常会采用瀑布流布局,这是一种渐进式加载的方式。瀑布流通常依赖于JavaScript和Ajax技术,Ajax返回的数据通常是JSON格式。
接着,笔记讲解了Python与爬虫的关系。在分析爬虫时,我们需要理解网页的结构,特别是当图片等内容是通过JavaScript渲染时,需要通过抓包工具来分析请求和响应。课程推荐使用Pycharm作为编译器,Python 3.5作为编程语言,并介绍了requests库的安装和使用。
实战部分,课程展示了如何使用Python进行瀑布流爬虫的实现,包括爬取360网站的图片并保存到本地。这一部分涉及到requests库的使用,如发送HTTP请求,获取响应,并解析响应内容。此外,还详细讲解了如何爬取百度图片,利用Ajax请求获取数据,并实现批量下载图片。
最后,课程布置了作业,要求学生对本节课学到的知识进行封装,使得模块化,可以灵活地应用于不同的内容下载和数量控制。这也意味着学生需要进一步理解和掌握爬虫的动态加载、数据解析以及文件保存等核心技能。
这份授课笔记对于初学者来说是非常实用的学习材料,它不仅讲解了理论知识,还提供了具体的实战案例,有助于读者更好地理解和实践Python爬虫技术,特别是针对瀑布流网站的爬取。
数据收集(数据分析、人工智能)
模拟操作(测试、数据采集)
接口操作(自动化)
瀑布流
我们数据比较多的时候,为了更好用户体验和节省服务器资源,我们进行渐进式的加载。
数据量很大
瀑布流的图片通常是用 js 加载
瀑布流一定用的 ajax 技术
注意:Ajax 技术通常返回的是一个 json 文本格式
2、Python 与爬虫
爬虫分析
结构分析
1、 当前的图片来源于 js 的渲染
2、 使用的 ajax 技术
3、 使用 ajax 通常返回 json 数据
抓包分析
剩余11页未读,继续阅读
288 浏览量
219 浏览量
153 浏览量
2024-07-20 上传
2022-07-09 上传
115 浏览量
123 浏览量
2021-10-25 上传
162 浏览量

weixin_57113910
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- LINUX-1.2.13内核网络栈实现源代码分析
- EXT 中文手册.pdf
- see mips run 2nd edition(CN)
- 制造业常用英语词汇.pdf
- Spoon_User_Guide_3_0
- Apress - The.Definitive.Guide.to.SOA.BEA.AquaLogic.Service.Bus.May.2007.pdf
- 管理信息系统分析与设计—图书馆管理信息系统
- oracle体系结构
- 计算机等级考试(pc技术)
- after effect 插件应用指南(英文).pdf
- linux 网络编程笔记
- 测试知识文件(软件测试背景)
- IBM Ratioal技术白皮书_软件测试自动化技术
- spring struts hibernate 自己整理的 很不错 收集了许多题型
- sql 笔试题包含了sql的基础知识 有好几种题型 有答案
- sql 笔试题包含了sql的基础知识 有好几种题型 有答案
