知识相似性检测:结合语义和数据挖掘技术的新方法
67 浏览量
更新于2024-06-18
收藏 986KB PDF 举报
"基于语义和数据挖掘技术的知识相似性检测"
本文主要探讨的是如何利用语义和数据挖掘技术来检测知识的相似性,特别是在科学研究领域。随着互联网的发展,科学出版物的数量急剧增长,这对研究人员寻找相关文献、追踪研究历史以及寻找潜在合作者带来了巨大挑战。在这种背景下,该研究提出了一种新的架构,旨在整合多种文献来源,通过丰富基础数据模型,如利用本体、词汇表和关联数据技术,以识别共同的研究领域和潜在的合作网络。
首先,作者强调了当前学术信息的分散性和混乱性,这些信息分散在各种数字存储库、文本文件和书目数据库中,这使得研究人员很难有效查找和组织信息。为了解决这个问题,他们设计并实现了一个原型系统,这个系统集中了来自不同书目来源的数据,构建了一个知识库。通过应用数据挖掘技术,系统能够分析和比较知识领域,从而帮助研究人员找到相似的研究方向。
在方法论方面,论文提到了数据挖掘和语义网技术的应用。数据挖掘技术被用来从大量文献中提取关键信息,识别模式和关系,而语义网技术则提供了对信息更深层次的理解和链接,使得机器可以理解并处理这些数据的含义。关联数据技术则是为了实现数据的集成和互操作性,确保不同来源的信息可以被有效地连接和比较。
此外,关键词“数据集成”和“查询语言”表明,研究中可能涉及到如何整合不同来源的数据,并开发适应这种环境的查询工具,以便研究人员能更方便地检索和分析相关文献。这种方法不仅有助于缩小搜索范围,还可以揭示潜在的协同研究机会,促进研究人员之间的合作。
这篇论文提出了一种创新的方法,利用语义技术和数据挖掘手段,帮助科研人员在海量的科学文献中找到具有相似研究兴趣的同行,从而优化文献检索,提升研究效率,并可能推动跨学科的合作。这一工作对于改善科研信息的管理和利用,以及推动学术交流具有重要的意义。
152
X. Sumba
等人
/
理论计算机科学电子笔记
329
(
2016
)
149
一个指标,用于确定出版物之间的关系,并使用出版物关键字确定共同领域。
在分析了处理确定研究主题的方法的相关工作之后,我们可以说,现有的工作并
不能自动丰富从不同来源(如Google Scholar或DBLP
)
获得的书目资源。此外,
我们建议使用数据挖掘算法来检测相似领域的知识和语义本体来描述和重用提取和
处理的数据
3
用于检测相似知识领域的架构
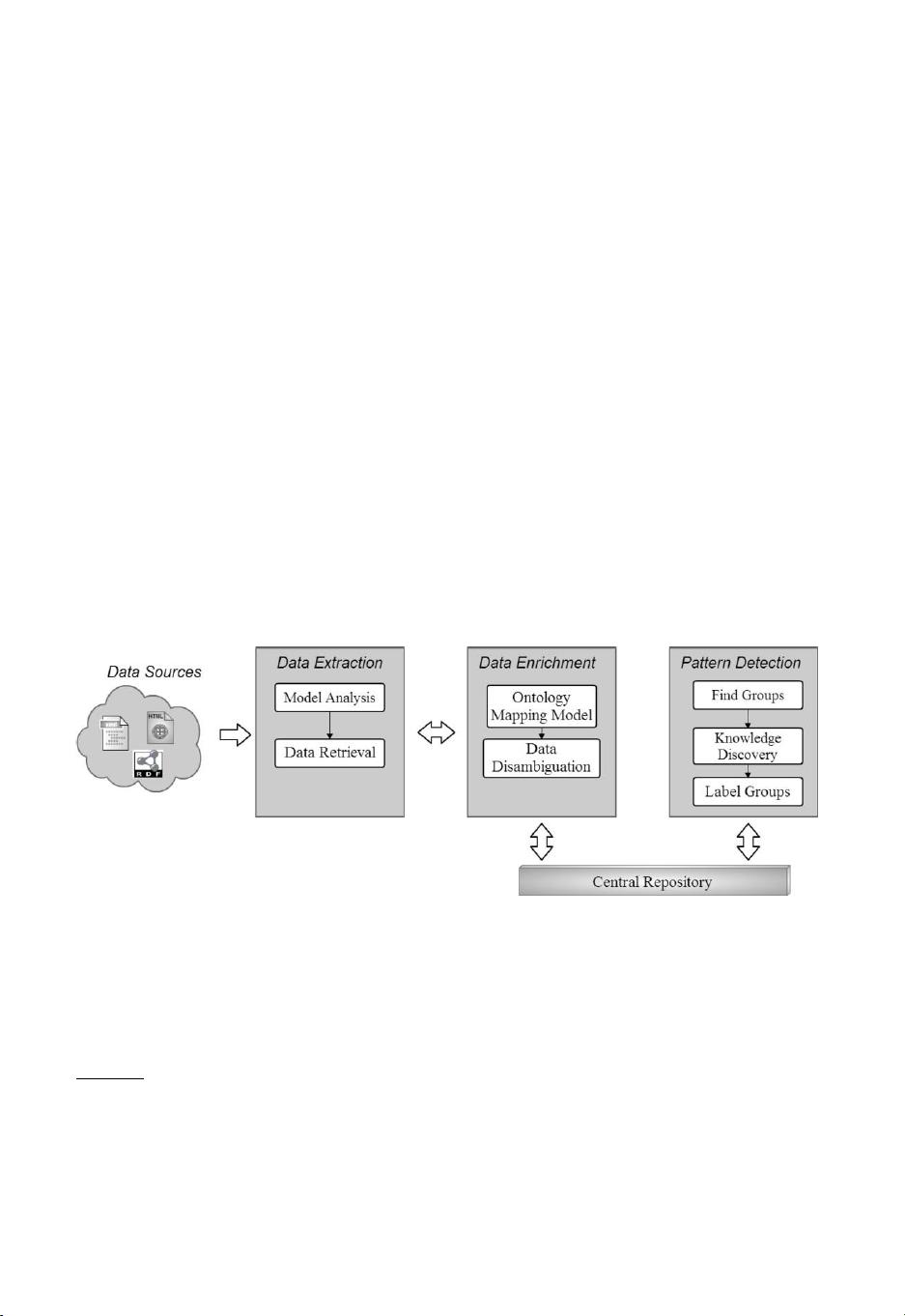
在本节中,我们详细介绍了我们的架构,旨在丰富网络上可用的学术文献,并找到
作者与其出版物之间的关系。我们的方法依赖于三个不同的主要模块,即:
1
)数据
提取,它描述和存储作者和出版物,有几个数据模型。2)数据丰富,这需要每个作
者的出版物,并丰富他们使用语义技术和3)模式检测,这使得使用数据挖掘算法
来检测类似的知识领域和潜在的合作网络。该架构的高级模块如图
1
所示,其特征将
在本节中进行说明。最后,我们提供了一个SPARQL端点
9
,
用于查询作者、出版
物、知识领域和协作网络。
图1.一、从书目数据源中检测模式的通用架构
3.1
数据源
我们使用网络上的几个数据源来支持探索 学术数据。其中一些提供了一个接口
到书目数据的特定存储库,其他集成多个数据源,以提供对更丰富的数据集的访
问,提供更丰富的功能集。然而,有两种类型的书目来源检索数据。首先,访问是
免费的,信息可以在网上获得第二,需要使用费,因为它们是
9
http://redi.cedia.org.ec/sparql/admin/squebi.html
剩余18页未读,继续阅读
2011-07-25 上传
2021-07-14 上传
2021-07-14 上传
点击了解资源详情
2021-04-18 上传
2013-04-14 上传
2021-09-29 上传

cpongm
- 粉丝: 5
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 单片机串口通信仿真与代码实现详解
- LVGL GUI-Guider工具:设计并仿真LVGL界面
- Unity3D魔幻风格游戏UI界面与按钮图标素材详解
- MFC VC++实现串口温度数据显示源代码分析
- JEE培训项目:jee-todolist深度解析
- 74LS138译码器在单片机应用中的实现方法
- Android平台的动物象棋游戏应用开发
- C++系统测试项目:毕业设计与课程实践指南
- WZYAVPlayer:一个适用于iOS的视频播放控件
- ASP实现校园学生信息在线管理系统设计与实践
- 使用node-webkit和AngularJS打造跨平台桌面应用
- C#实现递归绘制圆形的探索
- C++语言项目开发:烟花效果动画实现
- 高效子网掩码计算器:网络工具中的必备应用
- 用Django构建个人博客网站的学习之旅
- SpringBoot微服务搭建与Spring Cloud实践
