"Spark:高速大数据处理引擎与持续性数据流介绍"
需积分: 9 19 浏览量
更新于2024-02-03
收藏 748KB DOCX 举报
Spark是一款专为大规模数据处理而设计的快速通用计算引擎。相比于传统的基于硬盘计算的MapReduce,Spark采用内存计算的方式,因此具有更快的计算速度。此外,Spark还支持迭代计算,即将计算结果代回原变量进行重复计算,直到满足特定数值条件为止。与此相对应的是,MapReduce并非流式计算。
在Spark中,持续性数据流的抽象称为DStream,它是一种微批处理的RDD(弹性分布式数据集)。DStream将连续不断的数据流划分为一系列小的批次进行处理,具备了高容错性和低延迟的特点。DStream还提供了丰富的转换和操作函数,使得对数据流的处理更加灵活和高效。
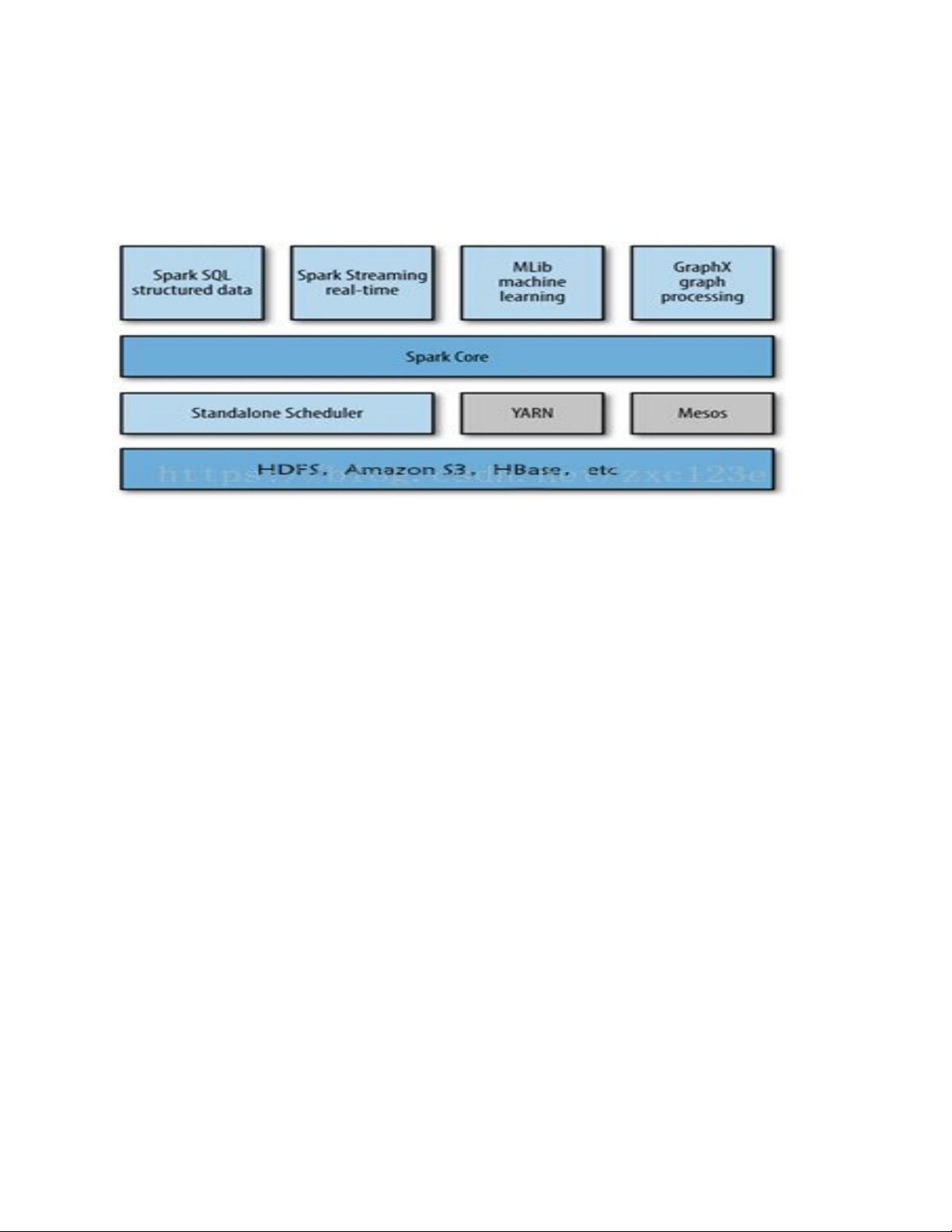
Spark由多个组件组成,包括Spark Core、Spark SQL、Spark Streaming、Spark MLlib和Spark GraphX等。Spark Core是Spark的基础组件,提供了分布式任务调度、内存管理、容错机制等核心功能。Spark SQL提供了用于查询结构化数据的接口,支持使用SQL语句进行查询和操作。Spark Streaming是Spark处理实时数据的组件,通过将实时数据切分成小批次进行处理,实现了对连续数据流的高效处理。Spark MLlib是Spark的机器学习库,提供了丰富的机器学习算法和工具,可用于数据挖掘和预测分析等任务。Spark GraphX是Spark的图计算库,用于处理大规模图结构数据,支持常用的图算法和操作。
与Hadoop相比,Spark具有更高的性能和更丰富的功能。在数据处理方面,由于采用内存计算,Spark可以大幅提升计算速度,特别适用于迭代计算和实时数据处理。同时,Spark提供了丰富的库和工具,包括SQL查询、机器学习、图计算等,使得用户可以更方便地进行复杂的分析任务。此外,Spark还提供了与Hadoop兼容的接口,可以无缝地与Hadoop生态系统的其他组件进行集成。
总之,Spark是一款快速通用的计算引擎,适用于大规模数据处理和实时数据处理等应用场景。它通过采用内存计算和提供丰富的组件和功能,提升了计算性能和用户体验。在大数据领域,Spark正逐渐成为最重要的数据处理工具之一,并受到越来越多企业和研究机构的广泛关注和应用。
Hadoop 平台技术研究
处理图的库(例如,社交网络图),并进行图的并行计算。像 Spark Streaming,Spark
SQL 一样,它也继承了 RDD API。它提供了各种图的操作,和常用的图算法,例如
PangeRank 算法。
2.2 Spark 运行模式
Local(本地模式):使用本地模式,有一个 executor 与 driver 运行在同一个 JVM 中,这
种模式的主 URL 为 local(一个线程),local(n)(n 个线程)或 local(*) (机器的每个内核一
个线程)。这种模式一般用于开发测试。
Standalone(独立模式):Standalone 是 Spark 自带的资源管理器,无需依赖任何其他资
源管理系统。它运行了一个 master 以及一个或多个 worker.当 spark 应用启动
时,master 要求 worker 代表应用生成多个 executor 进程,这种模式的主 URL 为
spark://host:port
yarn(集群模式):集群运行在 Yarn 资源管理器上,资源管理交给 Yarn,Spark 只负责进
行任务调度和计算。每个运行的 spark 应用对应于一个 yarn 应用案例,每个 executor
在自己的 yarn 容器中运行,这种模式的主 URL 为 yarn-client 或 yarn-cluster
mesos(集群模式):Mesos 是一个通用的集群资源管理器,它允许根据组织策略在不同的
应用之间细化资源共享。细粒度模式(默认):每个任务可以根据任务运行的情况在运行
过程中获得 mesos 动态资源分配,但是以额外的进程启动开销为代价。粗粒度模式:每
个任务会一直占有一定的资源,直到整个任务结束后才会释放资源。这种模式的主 URL
剩余23页未读,继续阅读
2018-01-16 上传
2022-11-24 上传
2021-04-15 上传
2018-06-01 上传
2020-03-29 上传
2019-07-19 上传
2017-06-20 上传

HighSuper520
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动夜灯:自动夜灯在天黑时打开 - 使用 Arduino 和 LDR-matlab开发
- RadarEU-crx插件
- torchinfo:在PyTorch中查看模型摘要!
- FFT的应用,所用数据为局部放电信号,实测可用。matalab代码有详细注释
- 邦德游戏
- LTI 系统的 POT:LTI 系统的参数化[非线性]优化工具-matlab开发
- Information-System-For-Police:警务协助申请系统
- Mondkalender-crx插件
- 麦田背景的商务下载PPT模板
- tsdat:时间序列数据实用程序,用于将标准化,质量控制和转换声明性地应用于数据流
- ubersicht-quote-of-the-day:他们说Übersicht的当日行情
- intensivao_python:主题标签treinamentosintensivãopython
- 豆瓣网小说评论爬虫程序
- bdf_ChanOps:在 BDF 上读、写和执行任何数学运算的函数。-matlab开发
- 幕墙节点示意图
- Shalini-Blue55:蓝色测试55
