MySQL EXPLAIN分析与索引优化实践
版权申诉
142 浏览量
更新于2024-08-05
收藏 1.58MB PDF 举报
"本资源详细介绍了SQL中的EXPLAIN关键字及其在优化查询性能中的应用,通过一个具体的示例展示了如何创建和使用EXPLAIN来分析查询执行计划。内容包括创建测试表、插入数据,以及如何利用EXPLAIN分析JOIN操作的执行计划。"
在MySQL中,`EXPLAIN`是一个非常重要的工具,它可以帮助我们理解数据库引擎如何执行SQL查询,从而找到可能的性能瓶颈。通过在查询语句前添加`EXPLAIN`关键字,我们可以获取到关于查询计划的详细信息,这包括了表的扫描方式、是否使用了索引、排序和临时表的使用情况等。
首先,我们创建了三个测试表:`actor`、`film`和`film_actor`。`actor`表有主键`id`,以及`name`和`update_time`字段;`film`表同样有主键`id`和字段`name`,并创建了一个名为`idx_name`的索引;`film_actor`表用于存储电影和演员的关系,包含了`film_id`、`actor_id`主键和`remark`字段,还有一个`idx_film_actor_id`的联合索引。
然后,我们向这些表中插入了一些数据。为了演示`EXPLAIN`的功能,我们假设要进行一个JOIN查询,比如找出所有电影(`film`)与其对应的演员(`actor`)的关联信息。
当我们对这样的查询使用`EXPLAIN`时,MySQL会展示以下关键信息:
1. **id**:查询的序列号,用于表示查询中的子查询层次。
2. **select_type**:查询类型,例如SIMPLE(没有子查询或JOIN)、PRIMARY(主查询)或SUBQUERY(子查询)。
3. **table**:被查询的表。
4. **type**:访问类型,如ALL(全表扫描)、INDEX(索引扫描)、range(范围扫描)或ref(基于常量或列的引用)等,这决定了表数据的检索方式。
5. **possible_keys**:查询可以使用的所有潜在索引。
6. **key**:实际使用的索引,如果没有使用索引,则显示NULL。
7. **key_len**:索引中使用的字节数。
8. **ref**:显示哪些列或常量被用来与索引比较。
9. **rows**:预计要检查的行数。
10. **Extra**:额外信息,例如是否使用了临时表、文件排序等。
通过分析`EXPLAIN`输出,我们可以判断查询是否高效。例如,如果看到`type`是ALL,意味着全表扫描,可能需要考虑优化索引来减少扫描的行数。如果`Extra`字段包含“Using where”、“Using index”或“Using temporary”、“Using filesort”,则表示在查询过程中可能涉及额外的操作,如过滤、临时表或文件排序,这些都可能影响性能。
了解这些信息后,我们可以针对性地调整查询语句,如优化WHERE条件、创建合适的索引,或者重新设计查询逻辑,以提升查询效率。在实际开发中,`EXPLAIN`是数据库性能调优的必备工具,它帮助我们理解和改进SQL查询的执行性能。
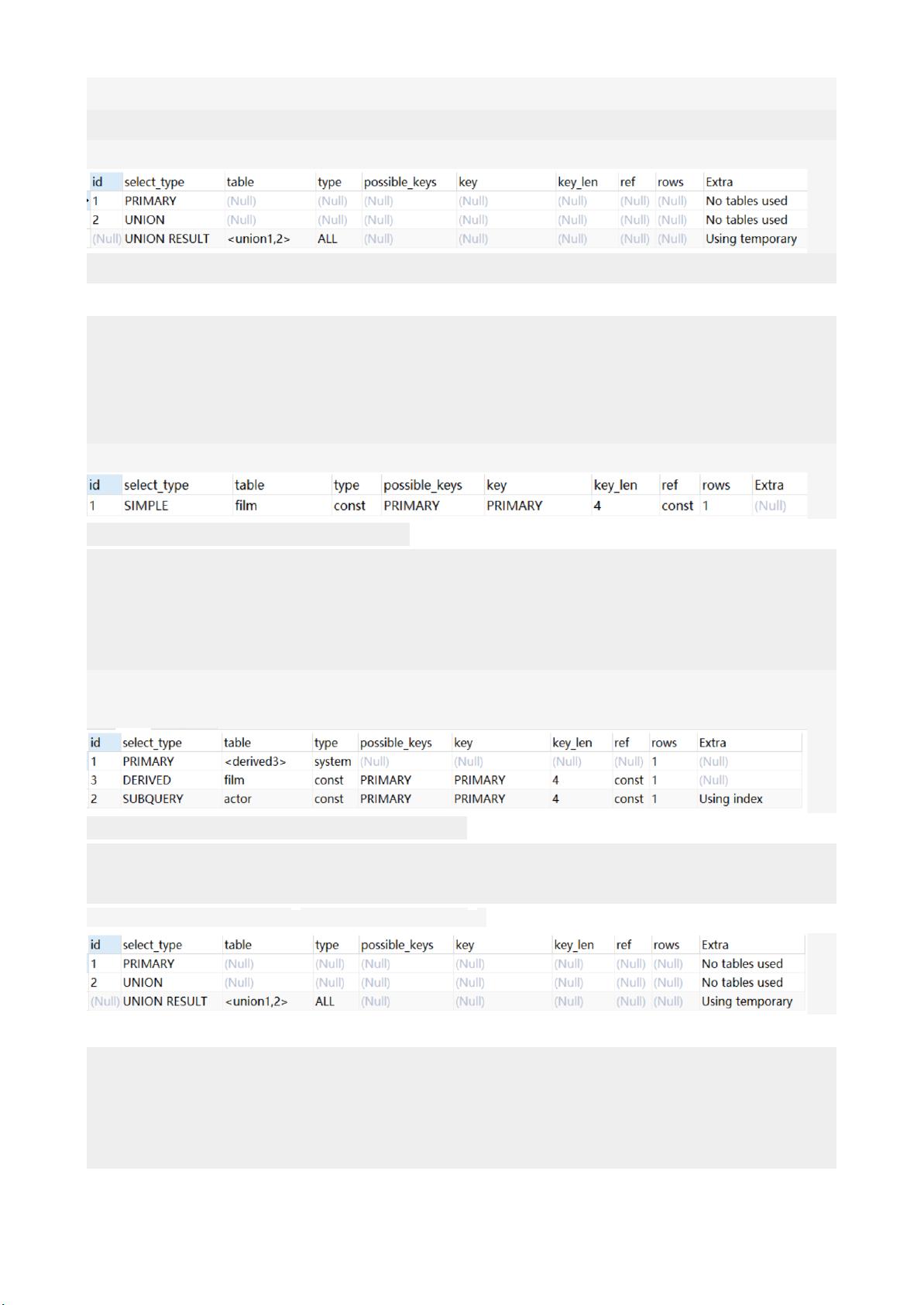
3)union查询
mysql>explainselect1unionallselect1;
union结果总是放在一个匿名临时表中,临时表不在SQL中出现,因此它的id是NULL。
2.select_type列
select_type表示对应行是简单还是复杂的查询,如果是复杂的查询,又是上述三种复杂查询中的
哪一种。
1)simple:简单查询。查询不包含子查询和union
mysql>explainselect*fromfilmwhereid=2;
2)primary:复杂查询中最外层的select
3)subquery:包含在select中的子查询(不在from子句中)
4)derived:包含在from子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生
表(derived的英文含义)
用这个例子来了解primary、subquery和derived类型
mysql>explainselect(select1fromactorwhereid=1)from(select*from
filmwhereid=1)der;
5)union:在union中的第二个和随后的select
6)unionresult:从union临时表检索结果的select
用这个例子来了解union和unionresult类型:
mysql>explainselect1unionallselect1;
3.table列
这一列表示explain的一行正在访问哪个表。
当from子句中有子查询时,table列是<derivenN>格式,表示当前查询依赖id=N的查询,于
是先执行id=N的查询。
剩余13页未读,继续阅读
2021-03-21 上传
2019-08-04 上传
点击了解资源详情
2022-11-22 上传
2019-08-25 上传
2019-05-22 上传
2021-06-07 上传
2024-04-10 上传
2021-09-30 上传

罗四强
- 粉丝: 15w+
- 资源: 301
 我的内容管理
展开
我的内容管理
展开







最新资源
- zen:Woohoo Labs。 Zen是一种非常快速,简单,符合PSR-11的DI容器和预加载文件生成器
- TKC:Projekt dalekohledu dopředmětuTKC
- 3.rar_单片机开发_C/C++_
- electronics-shop:Petto是想要宠物的人的在线宠物商店。
- PyPI 官网下载 | skygear-0.6.0.tar.gz
- ember-place-autocomplete
- 重复数据删除:用于准确,可扩展的模糊匹配,记录重复数据删除和实体解析的python库
- Citadel:渗透测试脚本的集合
- MIDletCode.zip_棋牌游戏_Java_
- MessageProcessingApplication
- 反汇编程序:借助capstone和ptrace的简单实验性反汇编程序
- Thierry-Cayman-Art:艺术家网站的Vue.js前端(Django后端)
- SpoofMAC:更改您的MAC地址以进行调试
- PHP开源api管理平台源码v1.2 带后台
- 全球顶尖j2me手机游戏揭密 pdf
- rcc:随机凯撒密码
