MapReduce模型详解:大数据处理与谷歌技术实践
MapReduce是谷歌在2004年由Jeffrey Dean和Sanjay Ghemawat提出的一项创新性技术,旨在解决大规模数据处理中的并行计算问题。它是一种编程模型和算法框架,用于分解复杂的计算任务,将其拆分成一系列相对简单的操作——映射(map)和规约(reduce)。这个模型的核心思想是将数据分片到多个节点上进行处理,然后通过本地操作后再汇总结果,极大地提高了处理大规模数据集的效率。
在MapReduce的基础架构中,用户编写两个关键函数:Map函数负责对输入数据进行预处理,将每个元素转换为一组(key, value)对,而Reduce函数则负责对这些键值对进行聚合,将具有相同键的值合并为单个结果。这种设计使得程序员只需关注业务逻辑,而将底层的并行化、错误处理和数据分布等复杂问题交给MapReduce框架处理。
谷歌的MapReduce实现允许在大规模、动态扩展的集群环境中运行,这些集群由普通配置的计算机组成,如数千台机器,能够处理PB级别的数据。这种灵活性使得没有并行计算或分布式系统开发经验的开发者也能高效地利用分布式资源,降低了复杂度,提高了效率。据统计,每天有上千个MapReduce任务在Google的集群上运行,处理着诸如网页抓取、日志分析、索引构建等各种大数据应用。
MapReduce的引入显著简化了数据处理流程,使得许多原本难以处理的海量数据运算变得可行。它的成功推动了整个大数据领域的进步,并成为了现代分布式计算平台的基础。后续的研究和改进也围绕着优化性能、降低延迟以及支持更高级别的编程抽象进行,例如Apache Hadoop和Spark等开源框架都是在MapReduce的基础上发展起来的。
MapReduce不仅是大数据处理的关键技术,也是现代IT行业中分布式计算和云计算的重要基石,它的出现改变了我们处理和分析数据的方式,对于推动科技进步和商业智能分析有着深远的影响。
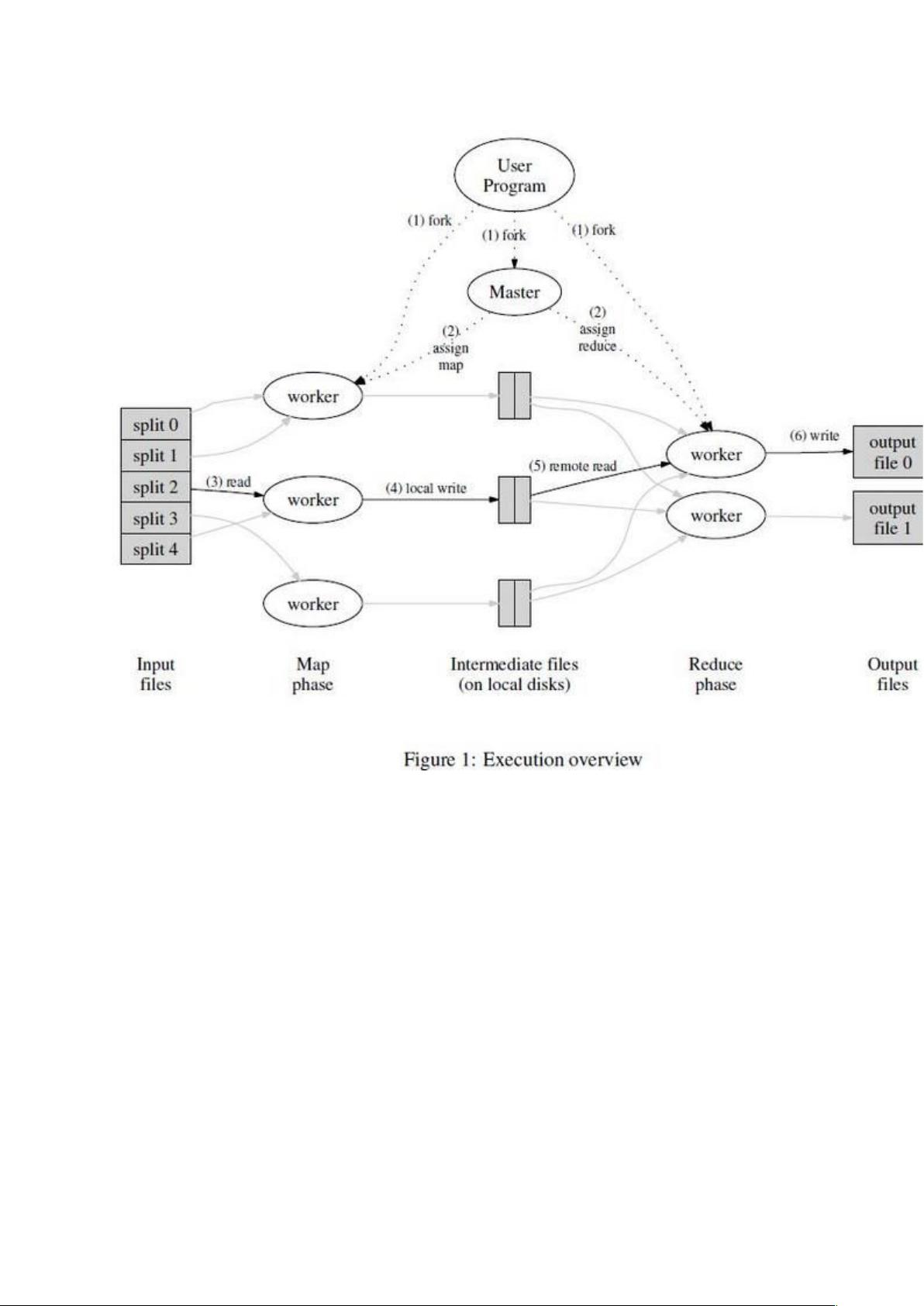
图 1 展示了我们的 MapReduce 实现中操作的全部流程。当用户调用 MapReduce 函数时,将发生下面
的一系列动作(下面的序号和图 1 中的序号一一对应):
1.用户程序首先调用的 MapReduce 库将输入文件分成 M 个数据片度,每个数据片段的大小一般从
16MB 到 64MB(可以通过可选的参数来控制每个数据片段的大小)。然后用户程序在机群中创建大量的程
序副本。
(
alex
:
copies of the program
还真难翻译)
2.这些程序副本中的有一个特殊的程序–master。副本中其它的程序都是 worker 程序,由 master 分配
任务。有 M 个 Map 任务和 R 个 Reduce 任务将被分配,master 将一个 Map 任务或 Reduce 任务分配给
一个空闲的 worker。
3.被分配了 map 任务的 worker 程序读取相关的输入数据片段,从输入的数据片段中解析出 key/value
pair , 然 后 把 key/value pair 传 递 给 用 户 自 定 义 的 Map 函 数 , 由 Map 函 数 生 成 并 输 出 的 中
间 key/value pair,并缓存在内存中。
剩余26页未读,继续阅读
919 浏览量
基于PLC的立体车库,升降横移立体车库设计,立体车库仿真,三层三列立体车库,基于s7-1200的升降横移式立体停车库的设计,基于西门子博图S7-1200plc与触摸屏HMI的3x3智能立体车库仿真控制
2025-01-12 上传
锂电池化成机 姆龙NJ NX程序,NJ501-1400,威伦通触摸屏,搭载GX-JC60分支器进行分布式总线控制,ID262.OD2663等输入输出IO模块ADA801模拟量模块 全自动锂电池化成分容
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传
2025-01-12 上传

juejitianyafei917
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 6502 汇编算法/Log,Exp
- Eclipse+WebLogic下开发J2EE应用程序
- solidworks高级装配体教程
- MTK软件编译过程.doc
- 09研究生考试英语真题
- 46家著名公司笔试题
- 手机电视标准分析与比较
- UNIX常用命令-2小时快速上手
- PL/I Reference Enterprise PL/I for z/OS and OS/390
- .net发送邮件的函数
- java面试知识点总结(接收建议和修改中...)
- ibatis入门ibatis入门
- 浪潮myGS pSeries 产品介绍
- 华为MA5100系统介绍
- Linux菜鸟过关 Linux基础
- NIOSII uClinux 应用开发
