事件图驱动的文本-视觉理解:连接现实世界多媒体应用
版权申诉
在"图机器学习峰会-3-4 基于事件图结构的文本-视觉理解.pdf"中,讨论的核心是将文本和视觉理解相结合,通过构建事件图结构来提升多媒体应用中的复杂认知能力。论文作者Manling Li提出了一个创新的方法,旨在解决现实世界多媒体应用中的一项关键挑战:如何使图像语言模型能够处理多层次的对齐关系,包括动词、对象和语义结构。
首先,文本-视觉理解的融合强调了实际场景中的需求,比如在识别和理解视频或图片时,模型不仅要能识别出物体,还要能关联这些物体与动作(如事件)。例如,"事件图"可以捕捉到如"Car Event Bombing"这样的事件,其中包含了事件的参与者(如Attacker和Target)、物品(如Car)以及动作(如Bombing)。这不仅涉及实体识别,还包括更高层次的概念理解和推理。
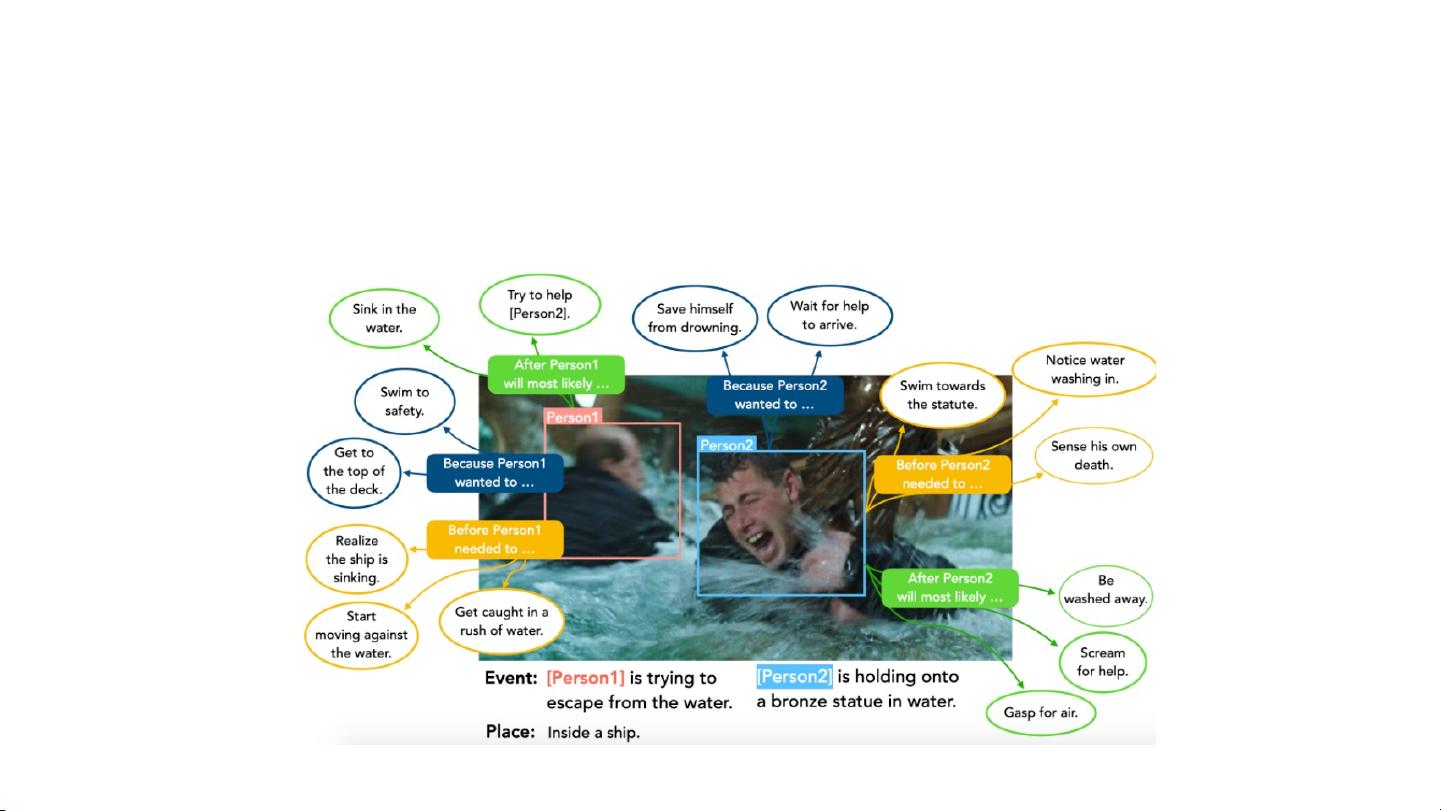
Zellers等人在2019年的"From recognition to cognition: Visual Commonsense Reasoning"的研究中,进一步推动了这一领域的进展,他们关注的是视觉常识推理,即模型不仅需要识别视觉元素,还需要具备理解日常生活中基本逻辑和情境的能力,例如,理解"Attacking"这个动作可能涉及的双方角色和目标。
Park等人也贡献了他们的研究成果,他们可能探讨了如何通过事件图结构设计更有效的算法,以增强图像语言模型的动态推理和跨模态理解,比如在处理"Vaccination"事件时,理解接种者(如woman)和受种者(如girl)之间的关系。
该研究论文关注的焦点是利用事件图结构来连接文本和视觉信息,以促进多媒体应用中的深层次理解和推理。这种技术有助于开发更加智能的系统,能在诸如新闻摘要、自动驾驶、安防监控等场景中准确地解读和解释复杂的图像数据,并基于文本上下文进行合理的情境推断。随着人工智能的进步,这种方法对于提升机器的感知和理解能力具有重要意义。
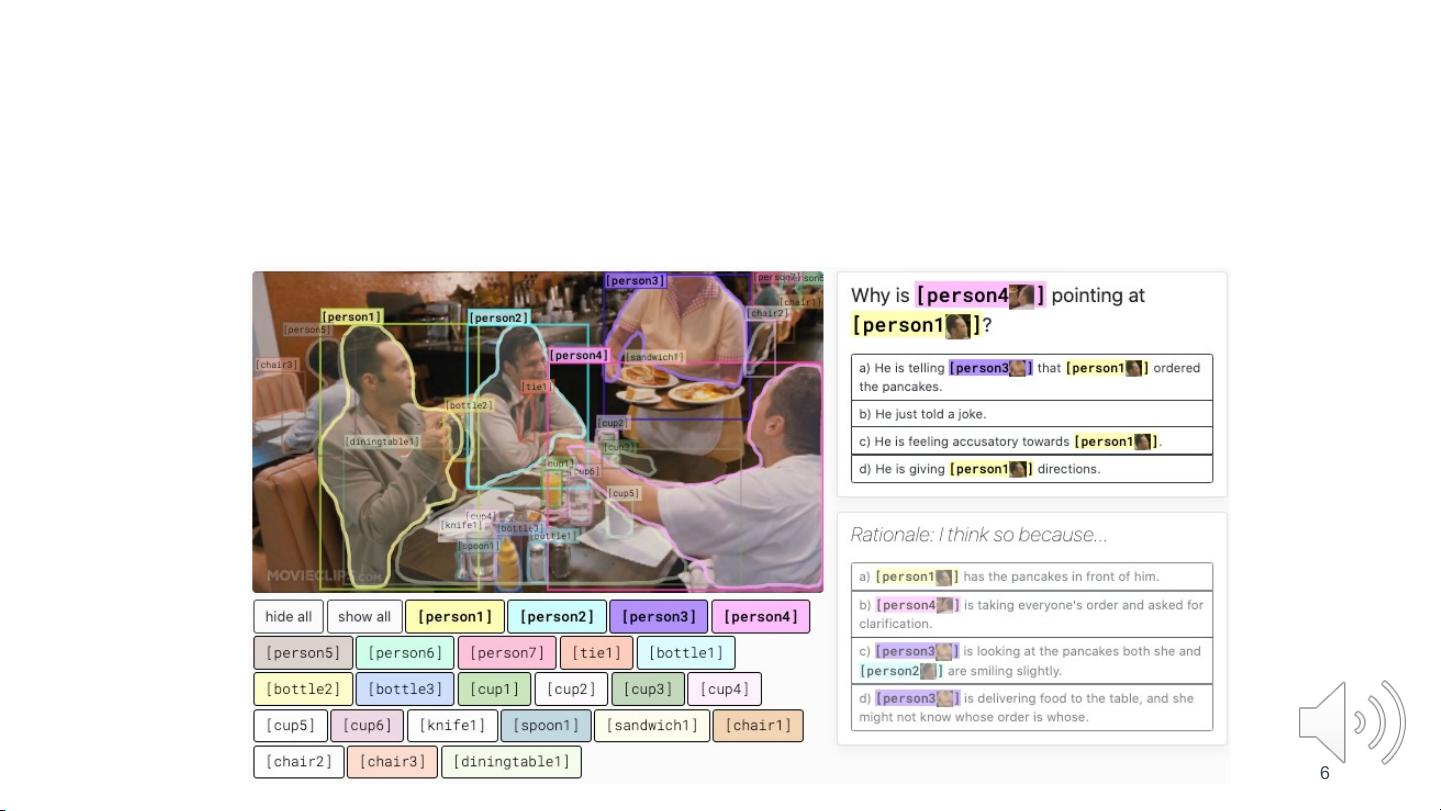
Real-world Multimedia Applications
• Real-world multimedia applications requires image-language models to
understand multiple levels of alignments such as verbs, objects, as well as
semantic structures.
Zellers, Rowan, et al. "From recognition to cognition: Visual commonsense reasoning." CVPR. 2019.
Visual Commonsense Reasoning
6
剩余32页未读,继续阅读
2024-10-25 上传
2022-07-10 上传

普通网友
- 粉丝: 13w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
