人机协同:数据准备的未来突破与挑战
125 浏览量
更新于2024-07-15
收藏 1.39MB PDF 举报
随着大数据时代的到来,数据准备在数据分析过程中扮演着至关重要的角色,但其复杂性和耗时性成为了企业及研究人员面临的重大挑战。"人在回路的数据准备技术研究进展"这一专题深入探讨了这两个核心问题——高昂的人力成本和冗长的时间周期。首先,文章关注于交互式数据准备技术,这是一种以用户为中心的方法,它通过实时互动预测用户的需求和意图,通过精准的算法预测和自动化流程,显著降低了数据准备的繁琐工作量,提高了效率。
交互式数据准备技术强调用户体验,用户不再是被动的数据接收者,而是参与到数据准备的决策过程中,这样既节省了人工干预的时间,又确保了数据处理的针对性和准确性。这种技术依赖于先进的机器学习模型和自然语言处理技术,能够理解用户的查询和需求,提供个性化的数据预处理解决方案。
其次,文章讨论了基于众包的数据准备技术。这种策略利用互联网上的庞大用户群体作为分布式计算资源,通过众包平台将数据清洗、转换等任务分解到个体用户,从而极大地扩展了数据处理能力。然而,如何确保众包数据的质量以及合理控制成本,如选择合适的任务分配策略、实施有效的质量监控机制,是这一领域亟待解决的关键问题。
为了实现高质量的众包数据准备,研究者们正在探索一系列方法,包括建立有效的激励机制、采用智能合约进行任务管理,以及通过人工智能技术自动评估和优化任务完成质量。同时,如何保护用户隐私和数据安全,以及如何处理数据主权和合规性问题,也是未来研究的重要方向。
"人在回路的数据准备技术研究进展"旨在通过结合交互式用户体验和众包计算力量,打破传统数据准备的瓶颈,推动数据分析的效率和质量提升。然而,技术进步的同时,也带来了新的伦理、法律和社会问题,这为未来的理论研究和实践应用提出了新的课题。在未来,期待看到更多创新的解决方案,使得数据准备变得更加智能、高效且透明。
BIG DATA RESEARCH 大数据
6
的难点一方面在于需要准确地预测适用于
用户数据集与分析任务的数据准备步骤以
及最优的参数,另一方面在于需要提升算
法执行的效率,以保证交互的实时性。本
文的第3节将从交互机制、操作预测与流
程推荐这3个方面梳理交互式数据准备的
研究进展。
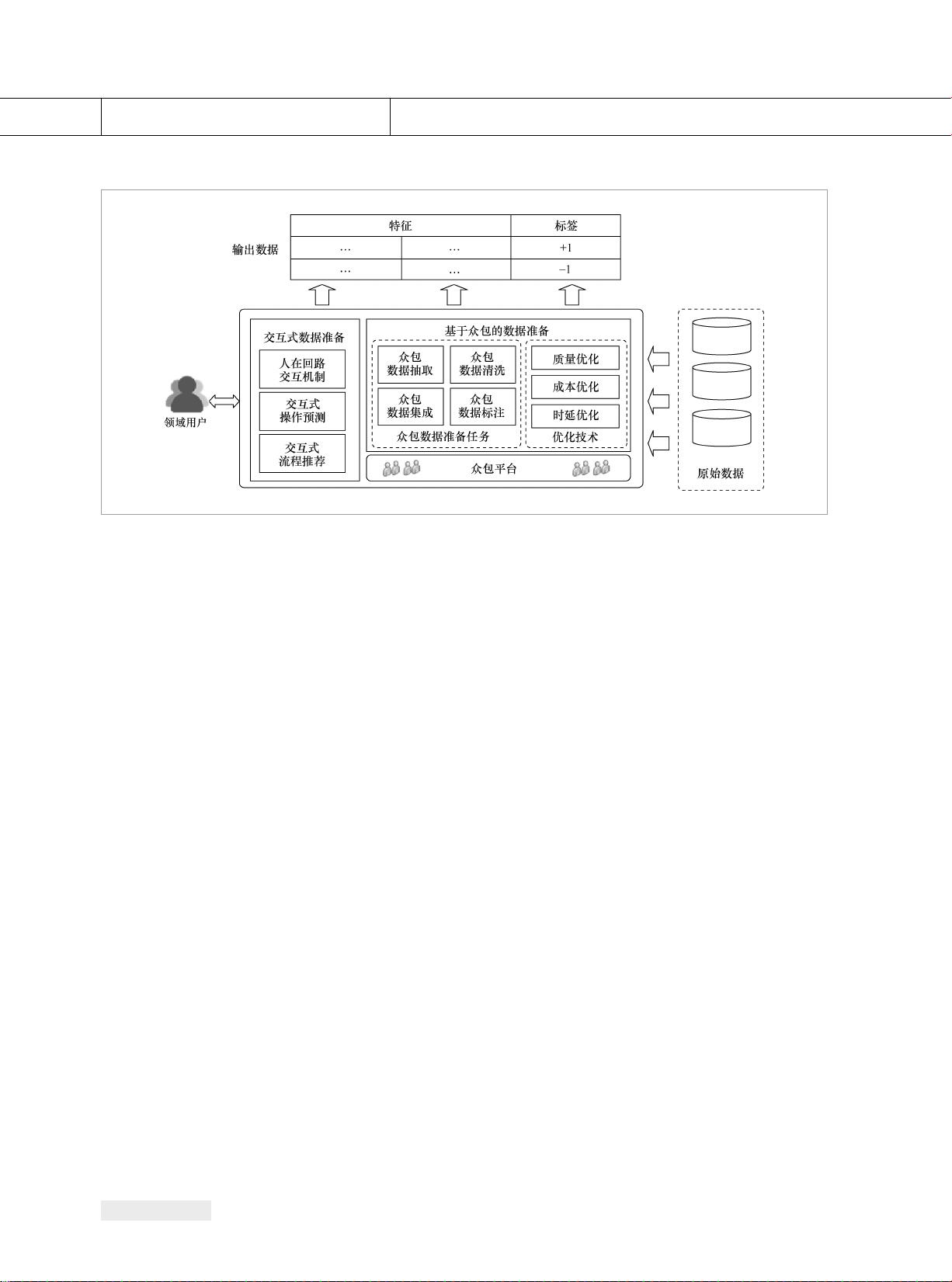
其 次 ,众 包 工 人 的 参 与 给 数 据 准 备 带
来了新的机会——能够通过人机协作的方
式解决传统单纯依靠机器难以解决的问
题,提升数据准备的效果。因此,众包技术
被广泛应用于数据准备过程中,如数据抽
取、数据清洗、集成与标注。其基本思想
是向互联网上的众包平台发布众包问题,
吸 引 大 量 的 互 联 网 用 户(称 为 众 包 工 人 )
作 答 ,以 相 对 低 廉 的 单 价 ,将 人 的 认 知 与
处理能力引入数据准备的过程中。然而,
由于数据集的规模越来越大,保证众包结
果 的 质 量 、成 本 与 时 延 变 得 越 来 越 有 挑 战
性。第4节将梳理众包数据准备的研究进
展,包括众包数据准备的核心任务与众包
优化。
不 难 看 出 ,虽 然 都 引 入 了人 的 参 与 ,
交互式数据准备与众包数据准备在谁来做
(w h o)、为 何 做(w h y)和 做 什 么(w h a t)
这3个基本问题上存在本质不同。具体地,
交互式数据准备面向的是需要进行数据准
备的终端用户(如上文提到的领域用户),
目的是通过尽可能少的交互预测用户的意
图,主要的工作是设计有效的交互机制和
预测算法。与此相对,众包数据准备面向
的是互联网上海量的众包工人,目的是借
助他们的识别能力提升数据准备的效果,
主要的工作是设计众包任务和进行质量控
制。需要指出的是,很多相关工作也研究
了 众 包 的 交 互 界 面 和 交 互 机 制
[6-9]
,但 其 目
的是提升众包完成的质量、降低众包成本
或时延,与本文的交互式数据准备是不同
的概念。
此外,现有的文献也采用了类似的方
式对人在回路的数据准备进行了分类。例如
D a t a T a m e r 系 统 将 参 与 人 分 为 管 理 员 与 领
域专家
[10]
,前者通过与系统的交互形成数据
准 备 工 作 流 ,后 者 起 到 了 类 似 众 包 的 作 用 ,
完 成 一 些 挑 战 性 强 的 任 务 ,如 实 体 识 别 。采
用 类 似 分 类 方 式 的 还 包 括 参 考 文 献 [ 1 1 - 1 4 ]
2019046-4
图 2 人在回路数据准备的研究概览
剩余15页未读,继续阅读
2021-07-07 上传
2021-09-22 上传
2021-09-14 上传
2023-05-01 上传
2023-05-10 上传
2023-04-05 上传
2023-04-05 上传
2023-05-19 上传
2023-08-20 上传

weixin_38685538
- 粉丝: 5
- 资源: 1023
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
