数据多流形结构分析:主成分与聚类方法
版权申诉
该文档是关于主成分分析在数据的多流形结构分析中的应用,主要涉及了在数据科学和机器学习领域的聚类方法。文章是针对某研究生数学建模竞赛的问题,通过不同的聚类模型对高维复杂数据进行解析。
主成分分析(PCA)是一种常用的数据降维技术,它通过线性变换将原始数据转换成一组各维度线性无关的表示,使得新坐标系下的方差最大化,从而保留了数据的主要特征。在文中,PCA被用来辅助K-means聚类算法,降低数据的维度,使聚类过程更加高效,并对模型的有效性进行了验证。
稀疏子空间聚类(SSC)模型则是用于处理数据分布于多个独立子空间的情况。在问题1中,通过对数据的SSC分析,将数据分成了两个类别,第41至140个数据被归为类别1,其余数据归为类别2。同时,通过PCA和K-means的组合,检验了SSC模型的聚类效果。
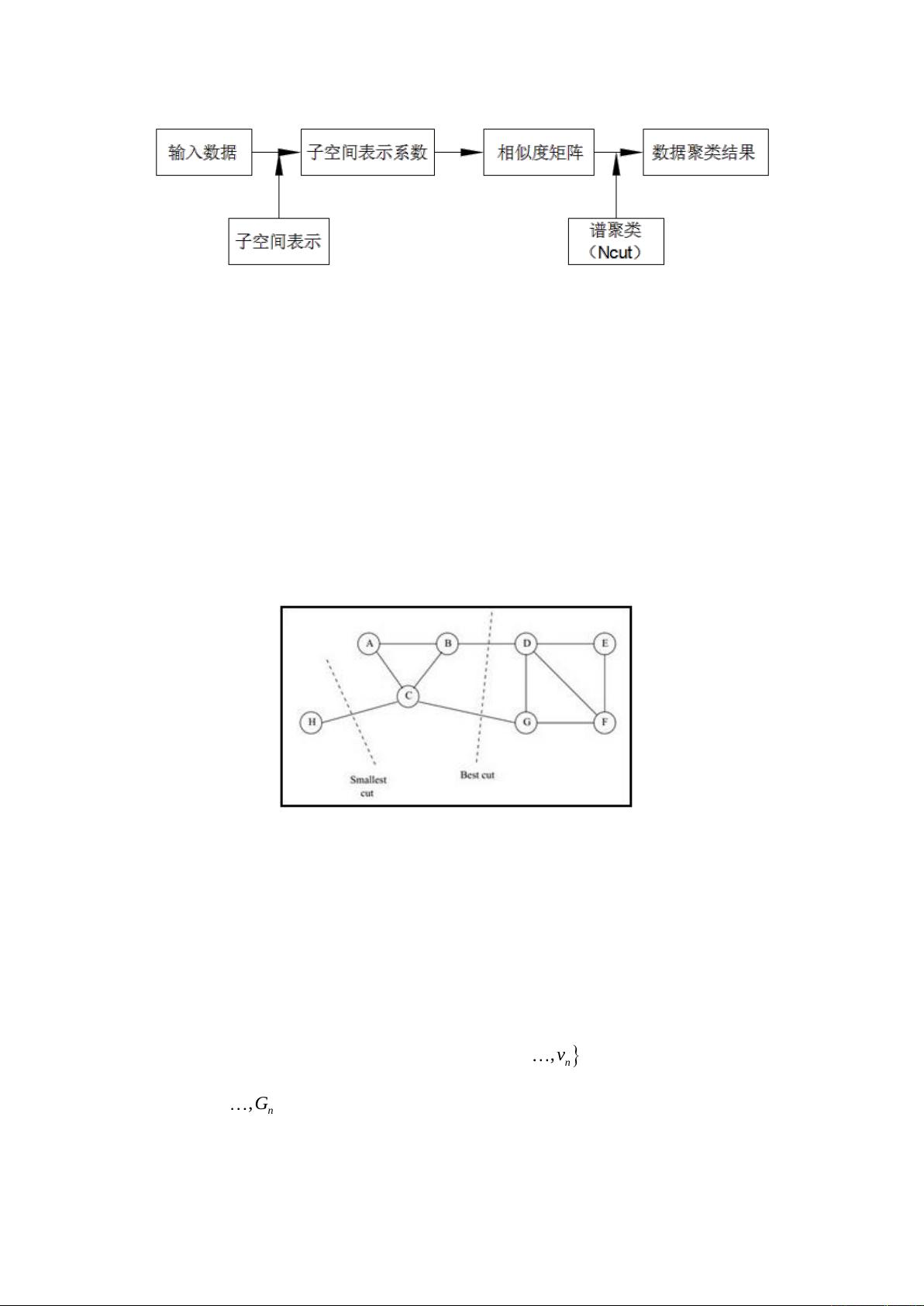
对于非线性流形聚类问题,如问题2中的子问题,文章提到了谱多流形聚类(SMMC)模型。SMMC适用于处理非线性结构的数据,能够有效地区分不同形状的流形,如直线、平面、二次曲线和螺旋线等。
问题3关注的是特征提取和视觉重建。对于3(a)的十字点聚类,使用了基于K-means的SSC模型;而对于3(b)的运动分割,结合PCA、Isomap和LLE三种降维模型以及K-means算法,将视频帧中的特征轨迹分成三类;3(c)的人脸识别问题,考虑到光照变化的影响,首先对数据进行标准化处理,然后利用PCA、Isomap和LLE的降维模型提取出低维不变的人脸特征,最终通过K-means实现人脸识别。
这篇文章展示了主成分分析和多种聚类模型(包括SSC、SMMC)在处理高维复杂数据时的能力,特别是在数据的多流形结构分析中。这些方法不仅能够有效地降低数据的复杂度,还能捕捉到数据的本质结构,有助于提升分析的准确性和有效性。在实际应用中,这些技术对于理解复杂数据集的内在模式和结构具有重要意义。

- 9 -
影后的低维嵌入表示
T
ii
y G x
具有最大的方差。
记原始数据按列堆叠构成的矩阵为
12
[x ,x , ,x ] R
Dd
N
X
,低维嵌入表
示按列堆叠构成的矩阵为
12
[ , , , ] R
Dd
N
Y y y y
。原始数据的样本协方差矩阵
为
1
( )( )
N
TT
t i i
i
S x x x x XHX
,其中
1
1
N
i
i
xx
N
为样本均值,
1
T
H I ee
N
为中心化矩阵,I 是单位矩阵,
R
Dd
e
是元素全为 1 的列向量。进而,可求得
低维嵌入表示的协方差矩阵为
1
( )(y )
N
T T T T T
i i t
i
y y y YHY G XHX G G S G
,
其中
1
1
N
i
i
yy
N
为低维嵌入表示的均值。PCA 的目标函数可以表示为下列数学
形式:
arg max tr(G S G)
S.t. G G=I
T
t
G
T
(4-1)
该目标函数的最优解 G 可以通过对原始数据的协方差矩阵
t
S
进行谱分解
或特征分解来求解,即假设 S
t
的谱分解为:
T
t
S U U
(4-2)
其中,
1
( , , )
D
diag
是由
t
S
的特征值组成的对角矩阵,满足:
1 1 2
( 1,2, , 1), [u ,u , ,u ],u (i 1,2, ,D)
i i D i
i D U
为
i
对应的特征向
量且
U U=I
T
。
在 PCA 的目标函数下,通常取最优解
G
为协方差矩阵
t
S
的最大的 d 个特
征值对应的特征向量,即
12
[u ,u , ,u ]
d
G
。PCA 学习后的低维嵌入表示的中
心通常在原点,即
(x )
T
ii
y G x
。
PCA 的一个显著特点和优势是:在不同的理解下可以有不同的解释。其中
一个解释是,PCA 是最小二乘意义下的最优线性重构模型,即其目标函数的数
学形式可以重述为:

剩余45页未读,继续阅读
2022-05-01 上传
2022-05-01 上传
2023-04-03 上传
2023-05-11 上传
2023-04-07 上传
2023-09-21 上传
2023-07-24 上传
2023-03-11 上传
2023-04-02 上传

普通网友
- 粉丝: 12w+
- 资源: 9195
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
