优化Spark MLlib:处理数十亿参数的L-BFGS Logistic回归
需积分: 5 146 浏览量
更新于2024-07-17
收藏 2.02MB PDF 举报
"Scaling Apache Spark MLlib to billions of parameters" 是一篇由Apache Spark提交者Yanbo Liang在SPARK SUMMIT 2017上发表的演讲稿,主题是扩展Apache Spark MLlib以处理数十亿级别的参数。该演讲探讨了在Spark上实现无矢量L-BFGS算法,用于大规模Logistic回归分析,并讨论了性能优化、与现有MLlib的集成以及未来的工作方向。
1. 背景:
随着大数据和大模型的结合,模型的准确性得到了显著提高。Apache Spark作为一个统一的平台,被广泛用于机器学习任务,特别是在处理大规模数据集时。然而,随着模型参数数量的增加,传统的优化方法面临着挑战,例如梯度下降(SGD)和加权最小二乘法(WLS)等。
2. 无矢量L-BFGS在Spark上的实现:
L-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)是一种优化算法,常用于求解大规模非线性最小化问题。无矢量L-BFGS是针对内存限制的一种优化,它不存储完整的梯度历史,而是通过紧凑的表示来近似Hessian矩阵。在Spark上实现无矢量L-BFGS可以有效地处理大量参数,降低了内存开销。
3. Logistic回归在无矢量L-BFGS上的应用:
Logistic回归是一种广泛使用的分类算法,通过最小化损失函数(通常是对数似然损失)来拟合模型。在无矢量L-BFGS上进行Logistic回归,可以解决传统方法中由于大模型而导致的计算和存储瓶颈。该方法广播系数到执行器,每个执行器本地计算损失和梯度,然后将它们汇总,处理正则化后,利用L-BFGS或OWL-QN(Orthant-Wise Limited-memory Quasi-Newton)找到下一步。
4. 性能:
演讲还关注了无矢量L-BFGS在Spark上的性能表现,可能涉及计算效率、内存使用效率和收敛速度等方面的评估。这包括对大规模数据集的训练时间、模型精度和资源利用率的分析。
5. 与现有MLlib的集成:
集成无矢量L-BFGS到现有的MLlib库中,意味着开发者能够直接利用这种优化后的算法,而无需进行底层实现。这提高了MLlib的功能性和适用范围,使得处理更大规模模型成为可能。
6. 未来工作:
演讲最后提到了未来的研究方向,可能包括进一步优化算法以提高性能,扩展到其他机器学习模型,或者探索更多适应大规模数据和参数的优化策略。
这篇演讲详细介绍了如何扩展Spark的MLlib库以处理大规模机器学习模型,特别是通过无矢量L-BFGS优化Logistic回归,从而提升了在云计算环境中的大规模数据分析能力。
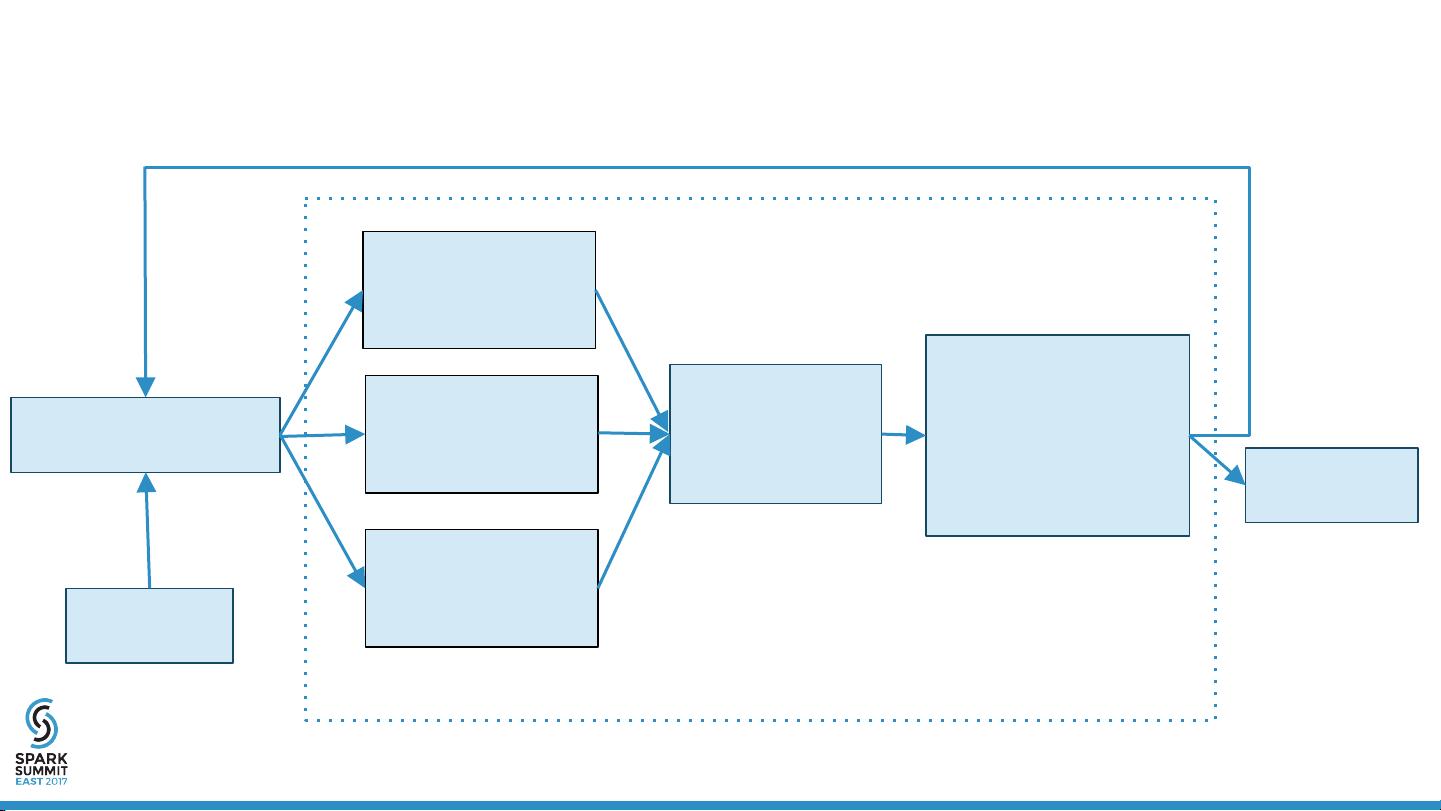
MLlib logistic regression
Initialize
coefficients
Broadcast coefficients
to Executors
Comput loss and
gradient for each
instance, and sum
them up locally
Comput loss and
gradient for each
instance, and sum
them up locally
Comput loss and
gradient for each
instance, and sum
them up locally
Reduce from
executors to get
lossSum and
gradientSum
Handle regularization
and
use L-BFGS/OWL-QN
to find next step
Final model
coefficients
Executors/Workers
Driver/Controller
loop untial converge
剩余43页未读,继续阅读
2024-10-24 上传
2024-10-24 上传
2024-10-24 上传

weixin_38744375
- 粉丝: 372
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
