HBase入门与实战指南:非关系型数据库详解
需积分: 14 22 浏览量
更新于2024-09-07
收藏 360KB DOC 举报
HBase学习笔记提供了对这个强大NoSQL数据库的全面概述。HBase是一款基于内存、面向列族的分布式数据库,它特别适合处理大量结构化和半结构化数据,支持MapReduce计算模型。以下是从文章中提炼的关键知识点:
1. **HBase简介**:
- HBase是非关系型数据库,其设计目标是高效处理大规模数据,特别是行式数据。
- 它是内存驱动的,这使得它可以快速访问和处理数据。
- 支持MapReduce编程模型,这意味着它能够处理大数据集的并行计算任务。
2. **HBase架构**:
- HBase依赖于Hadoop框架进行存储,提供了一个可靠的数据存储层。
- 架构由Master和RegionServer组成,Master负责全局管理和协调,如表分割、服务器注册等。
- RegionServer负责处理客户端的读写请求,并管理已分割的Region,即数据的物理存储区域。
3. **Zookeeper集成**:
- HBase高度依赖Zookeeper,这是一个分布式协调服务,用于维护节点的健康状态和配置信息。
- Master和RegionServer在Zookeeper中注册,确保服务发现和集群的稳定性。
4. **安装与使用步骤**:
- 用户需要下载HBase镜像,然后解压并配置`hbase-site.xml`文件,设置数据目录。
- 启动HBase可以通过`start-hbase.sh`脚本,启动后,Master和Zookeeper都在单机模式下运行。
- 使用`hbaseshell`工具登录HBase,可以查看帮助文档并创建表、插入数据和查询数据。
5. **基本操作**:
- `create`命令用于创建表,例如`create 'test', 'cf'`,定义表名和列族。
- `put`命令用于向表中插入数据,如`put 'test', 'row1', 'cf:a', 'value1'`,指定行键、列族和列名。
- `scan`和`get`命令分别用于查询表中所有数据和特定行的数据,如`scan 'test'`和`get 'test', 'row1'`。
HBase的学习和实践需要理解其分布式特性、数据模型和与Hadoop生态系统的紧密集成。通过这些基础操作,用户可以逐渐掌握如何在实际项目中高效地使用HBase来存储和处理海量数据。
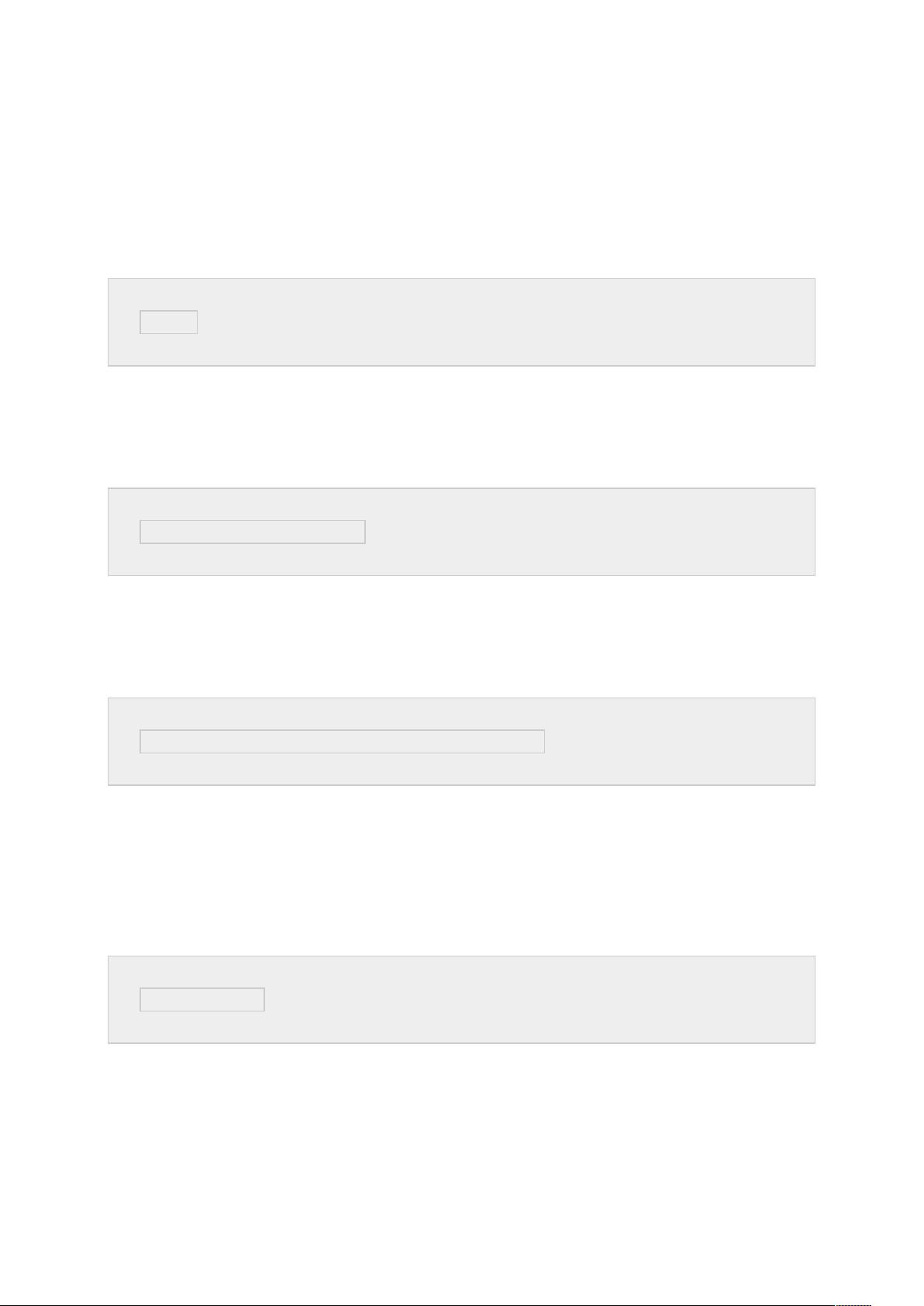
5、登录 hbase:
在解压后的文件中 bin 中执行:./hbase shell
6、查看 hbase 的帮助:
help
使用 help 命令;
7、在 hbase 中创建表:
create 'test', 'cf'
使用 create 命令,表名为 test,该表只有一个列族 cf;
8、在 hbase 的表中插入数据:
put 'test', 'row1', 'cf:a', 'value1'
使用 put 命令,test 为表名,row1 为行的唯一标识,cf:a 为 cf 列族中
的 a 列,值为 value1;
9、查看 hbase 中某个表中的数据:
scan 'test'
使用 scan 命令,test 为表名;
10、查询 hbase 中某个表中的数据:
剩余13页未读,继续阅读
2019-10-29 上传
2019-05-27 上传
2022-06-16 上传
2020-09-12 上传
2023-07-14 上传
2023-07-24 上传
2022-02-07 上传
2023-06-27 上传

LSY_csdn_
- 粉丝: 81
- 资源: 152
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
