使用RDMA加速Ceph存储性能
需积分: 9 200 浏览量
更新于2024-07-09
收藏 1.99MB PDF 举报
"Accelarate_ceph_with_RDMA.pdf"
本文档主要探讨了如何通过RDMA(Remote Direct Memory Access)技术加速Ceph存储系统,特别是在使用更快的存储设备(如Optane或AEP)时,如何实现性能的线性增长。Ceph是一款开源的分布式存储系统,广泛应用于云存储、大数据和容器存储等领域。
### 背景与动机
过去的成果(如在波士顿OpenStack峰会上展示的)表明,基于Optane的全闪存阵列能够提供超过280万IOPS(每秒输入/输出操作次数)的4K随机读取性能,且延迟极低。Optane作为BlueStore数据库驱动,显著降低了4K随机写入的尾部延迟。然而,随着更快存储设备的出现,我们需要一个高性能的网络栈,以实现带宽更高、CPU成本更低和更低延迟的目标,以保持性能的线性增长。
### CPU分布不均问题
在单个NVMe设备上运行一个OSD(对象存储设备)时,Ceph无法充分利用NVMe的性能,这导致了4K读写操作的延迟。而如果在一个NVMe设备上运行多个OSD,虽然可以极大地提高4K读写的性能,但CPU利用率往往成为瓶颈。下图(源自波士顿OpenStack峰会)展示了不同操作下的CPU开销:
- 对于4K随机读,异步消息处理大约占22%-24%的CPU。
- 对于4K随机写,日志移除线程占用约1.85%的CPU,RocksDB(Ceph的数据持久化组件)使用约6%-7%,异步消息处理则占14%-15%。
### 动机:引入RDMA
RDMA允许远程节点直接访问内存,减少了传统网络协议栈中的CPU负担,从而提高了数据传输效率。通过RDMA技术,Ceph可以实现更低的延迟和更高的带宽,更有效地利用硬件资源,特别是对于处理大量I/O操作的存储系统来说,这至关重要。
### Ceph与RDMA Messenger
将RDMA应用于Ceph的信使层,可以减少CPU的开销,因为RDMA网络接口卡(NIC)可以直接处理数据传输,无需经过操作系统内核。这不仅降低了CPU利用率,还减少了数据传输的延迟,使得Ceph能够更好地适应高速存储设备的性能。
### Ceph与NVMe-over-Fabrics
NVMe-over-Fabrics(NVMe-oF)是将NVMe协议扩展到网络环境的技术,它结合了NVMe的低延迟和高带宽特性以及网络的可扩展性。在Ceph中整合NVMe-oF,可以进一步提升性能,使得多个远程客户端能够高效地访问存储资源。
### 总结与下一步
通过RDMA和NVMe-oF,Ceph能够优化其性能,尤其是面对高速存储设备时。未来的步骤可能包括持续优化RDMA和NVMe-oF的集成,改进软件堆栈以降低CPU开销,以及探索如何在更大规模的部署中实现这些技术的优势。
总结,RDMA技术为Ceph提供了新的性能提升途径,尤其是在应对高速存储设备时,解决了CPU利用率问题,降低了延迟,提高了整体系统的效率。结合NVMe-oF,Ceph能够构建出一个更高效、响应更快的分布式存储解决方案。
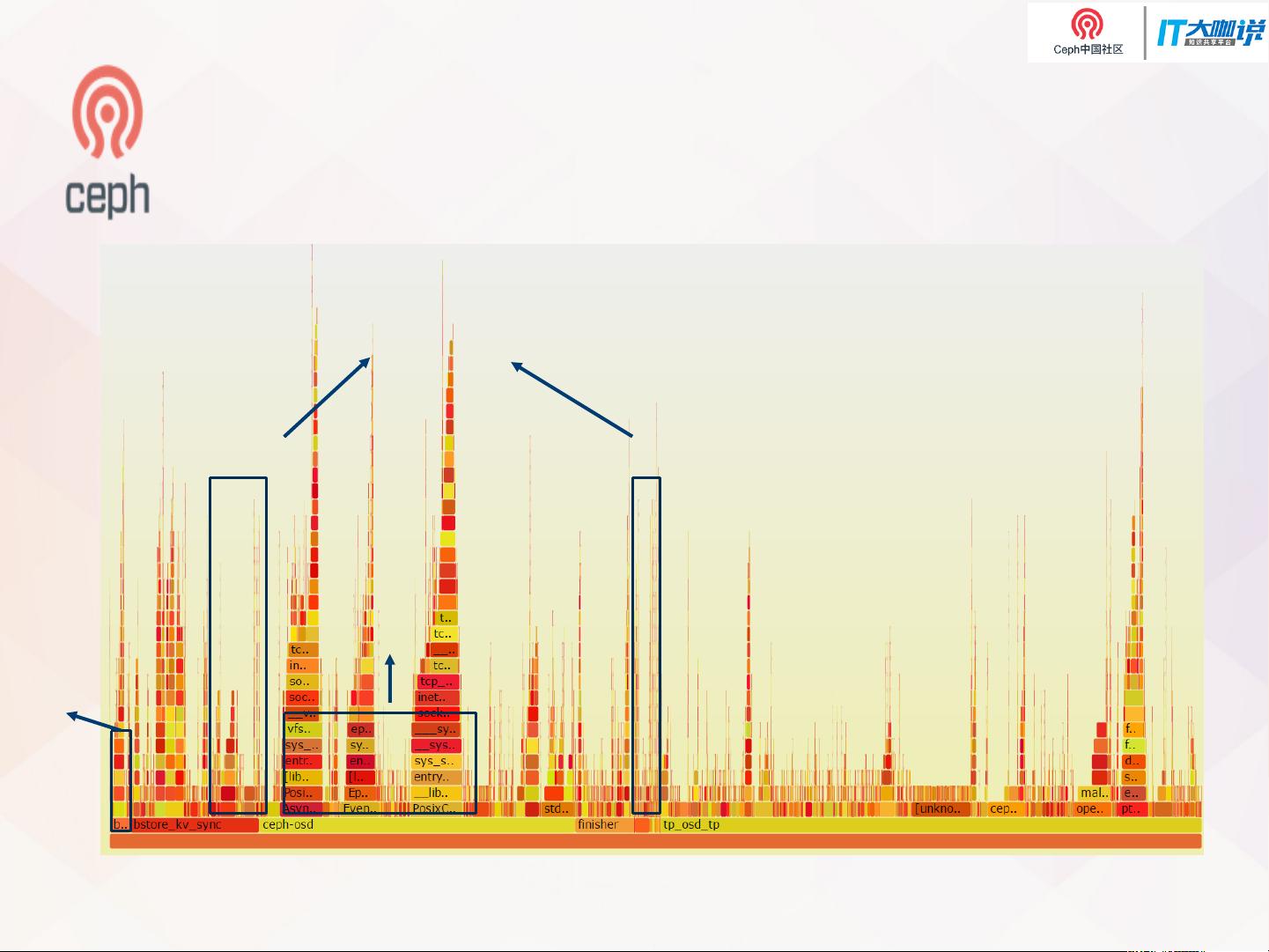
CPU overhead – 4K random write
Wal remove thread(~1.85%)
RocksDB(about ~6%
-
~7% )
AsyncMsg(~14% -
~15%)
剩余33页未读,继续阅读
158 浏览量
2015-12-20 上传
491 浏览量
126 浏览量
134 浏览量
234 浏览量
161 浏览量
2025-03-13 上传

bandaoyu
- 粉丝: 19w+
 我的内容管理
展开
我的内容管理
展开







最新资源
- Subclipse 1.8.2版:Eclipse IDE的Subversion插件下载
- Spring框架整合SpringMVC与Hibernate源码分享
- 掌握Excel编程与数据库连接的高级技巧
- Ubuntu实用脚本合集:提升系统管理效率
- RxJava封装OkHttp网络请求库的Android开发实践
- 《C语言精彩编程百例》:学习C语言必备的PDF书籍与源代码
- ASP MVC 3 实例:打造留言簿教程
- ENC28J60网络模块的spi接口编程及代码实现
- PHP实现搜索引擎技术详解
- 快速香草包装技术:速度更快的新突破
- Apk2Java V1.1: 全自动Android反编译及格式化工具
- Three.js基础与3D场景交互优化教程
- Windows7.0.29免安装Tomcat服务器快速部署指南
- NYPL表情符号机器人:基于Twitter的图像互动工具
- VB自动出题题库系统源码及多技术项目资源
- AndroidHttp网络开发工具包的使用与优势
