理解贝叶斯分类器:数据分析与朴素贝叶斯方法
下载需积分: 5 | PPTX格式 | 1.12MB |
更新于2024-07-09
| 163 浏览量 | 举报
"数据挖掘导论(第二版)第4章:贝叶斯分类器"
在数据挖掘领域,贝叶斯分类器是一种基于概率理论的机器学习方法,它利用贝叶斯定理来解决分类问题。贝叶斯定理描述了在给定一系列特征(或属性)的情况下,某一类别的先验概率如何影响后验概率。在这个概念中,"先验概率"是指在观察任何数据之前对类别概率的初始估计,而"后验概率"是在观察到特定数据特征后的更新概率。
在第四章中,讲解了条件概率的概念。例如,医生认为50%的脑膜炎患者会有脖子发僵的症状,而脑膜炎本身的发病率是1/50,000,脖子发僵的普遍率是1/20。通过贝叶斯定理,我们可以计算出如果一个人脖子发僵,他是脑膜炎患者的后验概率。
贝叶斯分类器的目标是根据给定的一组属性(A1, A2, ..., An)预测一个记录的类别(C)。这涉及到计算P(C|A1, A2, ..., An),即在已知这些属性值的情况下,属于类别C的概率。贝叶斯分类器的运作方式是找到使后验概率最大的类别。
为了实现这一目标,贝叶斯分类器采用了一种简化假设,即"朴素贝叶斯"假设,即所有属性在给定类别下都是条件独立的。这意味着,对于对象的属性Ai,其出现的概率P(Ai|Cj)不受其他属性的影响。这个假设简化了计算过程,但可能在实际问题中并不总是成立。
朴素贝叶斯分类器利用训练数据集来估计各种条件概率。例如,要预测一个客户是否会违约(拖欠贷款),可以计算出在已知属性如是否有房、是否离异、年收入等情况下,违约(Yes)和不违约(No)的条件概率。
类别概率P(C)可以通过数据集中类别实例的数量来估计,例如,P(No) = 类别“不违约”的实例数 / 总实例数,P(Yes) = 类别“违约”的实例数 / 总实例数。
对于离散属性,条件概率可以直接根据数据集中具有特定属性值和类别的实例数量来计算。而对于连续属性,通常需要进行某种形式的离散化或者使用概率密度函数来估计条件概率。
贝叶斯分类器是一种简单而强大的工具,尤其适用于处理大量特征和类别问题。虽然它的朴素假设可能过于理想化,但在许多实际应用中仍然表现出良好的性能。在数据挖掘中,理解并能够运用贝叶斯分类器对于解决分类问题至关重要。
02/10/2020 5
贝叶斯分类器
给定一个测试集 :
•
我们可以估计
P( 拖欠 = Yes | X)
P( 拖欠 = No | X)?
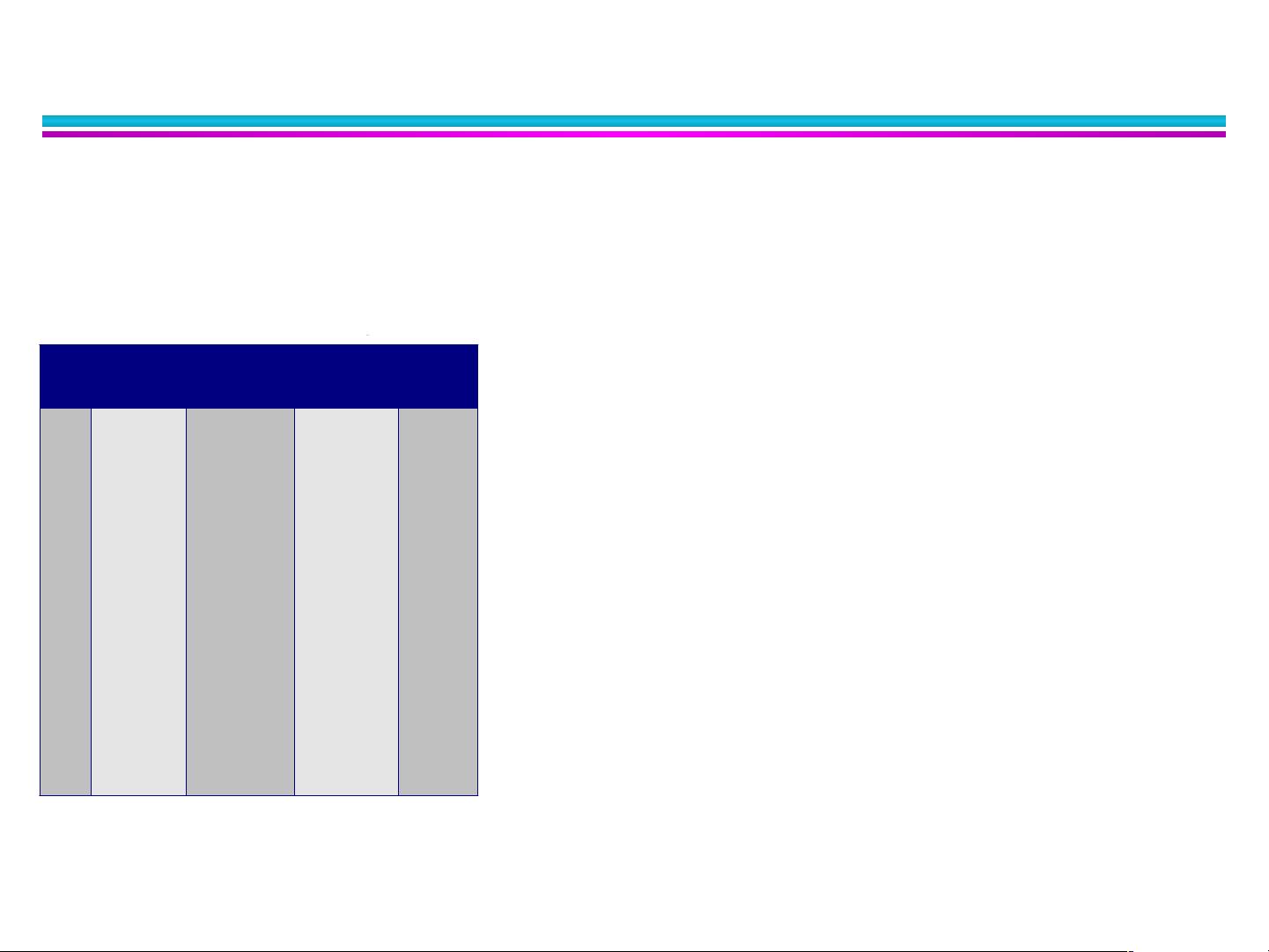
( No, , 120K)X 有房 离异 年收入
Tid 有房
婚姻状态
年收入
拖欠
1 Yes Single 125K
No
2 No Married 100K
No
3 No Single 70K
No
4 Yes Married 120K
No
5 No Divorced 95K
Yes
6 No Married 60K
No
7 Yes Divorced 220K
No
8 No Single 85K
Yes
9 No Married 75K
No
10 No Singl e 90K
Yes
1 0

剩余25页未读,继续阅读
相关推荐



157 浏览量

hj_911
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Web远程教学系统需求分析指南
- 禅道6.2版本发布,优化测试流程,提高安全性
- Netty传输层API中文文档及资源包免费下载
- 超凡搜索:引领搜索领域的创新神器
- JavaWeb租房系统实现与代码参考指南
- 老冀文章编辑工具v1.8:文章编辑的自动化解决方案
- MovieLens 1m数据集深度解析:数据库设计与电影属性
- TypeScript实现tca-flip-coins模拟硬币翻转算法
- Directshow实现多路视频采集与传输技术
- 百度editor实现无限制附件上传功能
- C语言二级上机模拟题与VC6.0完整版
- A*算法解决八数码问题:AI领域的经典案例
- Android版SeetaFace JNI程序实现人脸检测与对齐
- 热交换器效率提升技术手册
- WinCE平台CPU占用率精确测试工具介绍
- JavaScript实现的压缩包子算法解读
