大规模语言模型驱动的超写实文本到图像扩散模型
需积分: 5 117 浏览量
更新于2024-06-22
收藏 10.84MB PDF 举报
标题 "Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding" 这篇论文探讨了如何将深度语言理解与文本到图像的生成模型相结合,以实现前所未有的照片级真实感。作者Chitwan Saharia等人来自Google Research的Brain Team,他们开发了一种名为Imagen的模型,该模型利用大型Transformer语言模型的强大文本理解能力,并借助扩散模型在高保真图像生成方面的优势。
核心内容包括:
1. **方法创新**:研究者提出了一种基于Transformer语言模型(如T5)的文字到图像生成模型。这些预训练在纯文本语料库上的模型表现出令人惊讶的效果,能够在图像合成中有效地编码文本信息。
2. **技术结合**:论文强调了将深度语言理解和扩散模型(如稳定扩散模型Stable Diffusion)的有效结合。通过这种方法,模型能够更好地理解和生成与输入文本高度相关的图像,而非单纯依赖图像生成模型的大小来提升性能。
3. **效果提升**:实验结果显示,增大语言模型的规模对提高样本质量和图像文本一致性的影响远超过增加图像扩散模型的大小。这表明,对于图像生成任务,语言模型的重要性不容忽视。
4. **模型性能**:模型Imagen在照片级真实感和语言理解方面达到了新的高度,这在文本到图像转换领域具有重要的里程碑意义。
5. **潜在应用**:这项工作可能对各种需要高质量图像生成和精准文本描述的应用产生深远影响,比如虚拟现实、艺术创作、图像搜索引擎等。
"Photorealistic Text-to-Image Diffusion Models" 是一项关于如何利用深度学习技术,尤其是Transformer语言模型和扩散模型的优势,以生成高度逼真且符合文本描述的图像的研究。论文的重点在于揭示了语言模型在图像生成中的关键作用,挑战了传统上对图像模型尺寸的过度依赖,为文本驱动的图像生成技术开辟了新的发展方向。
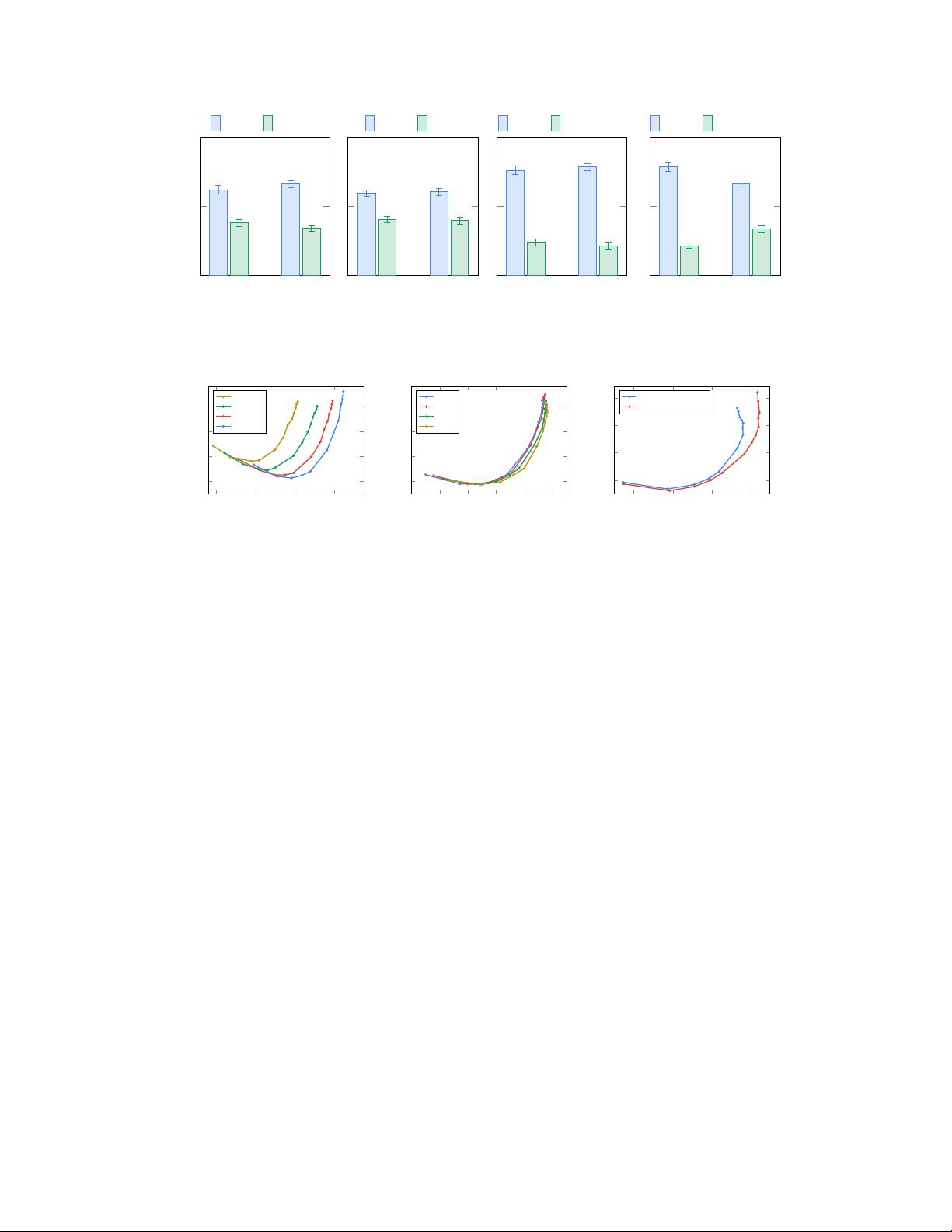
Alignment Fidelity
0%
50%
100%
Imagen
DALL-E 2
Alignment Fidelity
Imagen
GLIDE
Alignment Fidelity
Imagen
VQGAN+CLIP
Alignment Fidelity
Imagen
Latent Diffusion
Figure 3: Comparison between Imagen and DALL-E 2 [
54
], GLIDE [
41
], VQ-GAN+CLIP [
12
]
and Latent Diffusion [
57
] on DrawBench: User preference rates (with 95% confidence intervals) for
image-text alignment and image fidelity.
0.22 0.24 0.26 0.28
10
15
20
25
CLIP Score
FID-10K
T5-Small
T-Large
T5-XL
T5-XXL
(a) Impact of encoder size.
0.24 0.25 0.26 0.27 0.28 0.29
10
15
20
25
CLIP Score
FID-10K
300M
500M
1B
2B
(b) Impact of U-Net size.
0.26 0.27 0.28 0.29
10
15
20
25
CLIP Score
FID@10K
static thresholding
dynamic thresholding
(c) Impact of thresholding.
Figure 4: Summary of some of the critical findings of Imagen with pareto curves sweeping over
different guidance values. See Appendix D for more details.
Scaling text encoder size is more important than U-Net size.
While scaling the size of the diffusion
model U-Net improves sample quality, we found scaling the text encoder size to be significantly more
impactful than the U-Net size (Fig. 4b).
Dynamic thresholding is critical.
We show that dynamic thresholding results in samples with
significantly better photorealism and alignment with text, over static or no thresholding, especially
under the presence of large classifier-free guidance weights (Fig. 4c).
Human raters prefer T5-XXL over CLIP on DrawBench.
The models trained with T5-XXL and
CLIP text encoders perform similarly on the COCO validation set in terms of CLIP and FID scores.
However, we find that human raters prefer T5-XXL over CLIP on DrawBench across all 11 categories.
Noise conditioning augmentation is critical.
We show that training the super-resolution models
with noise conditioning augmentation leads to better CLIP and FID scores. We also show that
noise conditioning augmentation enables stronger text conditioning for the super-resolution model,
resulting in improved CLIP and FID scores at higher guidance weights. Adding noise to the low-res
image during inference along with the use of large guidance weights allows the super-resolution
models to generate diverse upsampled outputs while removing artifacts from the low-res image.
Text conditioning method is critical.
We observe that conditioning over the sequence of text
embeddings with cross attention significantly outperforms simple mean or attention based pooling in
both sample fidelity as well as image-text alignment.
Efficient U-Net is critical.
Our Efficient U-Net implementation uses less memory, converges faster,
and has better sample quality with faster inference.
5 Related Work
Diffusion models have seen wide success in image generation [
28
,
40
,
59
,
16
,
29
,
58
], outperforming
GANs in fidelity and diversity, without training instability and mode collapse issues [
6
,
16
,
29
].
Autoregressive models [
37
], GANs [
76
,
81
], VQ-VAE Transformer-based methods [
53
,
22
], and
diffusion models have seen remarkable progress in text-to-image [
57
,
41
,
57
], including the concurrent
DALL-E 2
[
54
], which uses a diffusion prior on CLIP text latents and cascaded diffusion models
8


剩余45页未读,继续阅读
194 浏览量
2024-07-11 上传
314 浏览量
2024-12-24 上传
2024-08-13 上传
127 浏览量
111 浏览量
158 浏览量

电子云与长程纠缠
- 粉丝: 4462
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







最新资源
- Phallanxpress:Phalanxpress允许您使用Wordpress作为后端来创建主干应用程序。 因此,您可以轻松创建单页wordpress。 它提供了一套完整的集合和模型,可以自动连接到您的wordpress安装
- 使用CORDIC算法的三角函数FPGA实现:使用CORDIC算法的三角函数在FPGA上实现。-matlab开发
- 烧瓶会议
- 冲突管理与沟通技巧
- LPC2300开发资料(原理图,例程代码)
- Catur:Bot Auto Chess.com
- Weather-Dashboard
- a8cas:用于存档 Atari 8 位磁带图像的便携式库和工具-开源
- priyamkhandelwal.github.io
- 电子功用-异步电机开环矢量控制方法和装置
- 个人职业生涯规划书
- python爬虫实验报告-3-类和对象的语法.ev4.rar
- VC6.0从开发activex ocx控件到发布到网上全过程
- Sweedly Webbyrå-crx插件
- DBS_Practice
- ShowCase:这是我的代码示例,用于展示我在c#中的编码经验
