Python文本挖掘:余弦相似度与TF-IDF在文本分析中的应用
需积分: 45 110 浏览量
更新于2024-07-18
8
收藏 2.52MB PPTX 举报
Python文本挖掘是数据挖掘领域的一个重要分支,主要涉及对文本数据进行深入分析和理解。本文档围绕四个关键部分展开:近似度分析、文本情感分析、协同过滤以及词云生成。
1. **近似度分析**:
- **余弦相似度与SimHash算法**:在文本相似度判断中,常用的算法有余弦相似度和SimHash。余弦相似度适用于短文本,它通过计算两个文本向量之间的夹角余弦值来衡量相似度,值越接近1表示相似度越高。SimHash则适合处理长文本和大数据场景,通过哈希函数将文本转化为二进制向量,简化了相似度计算。
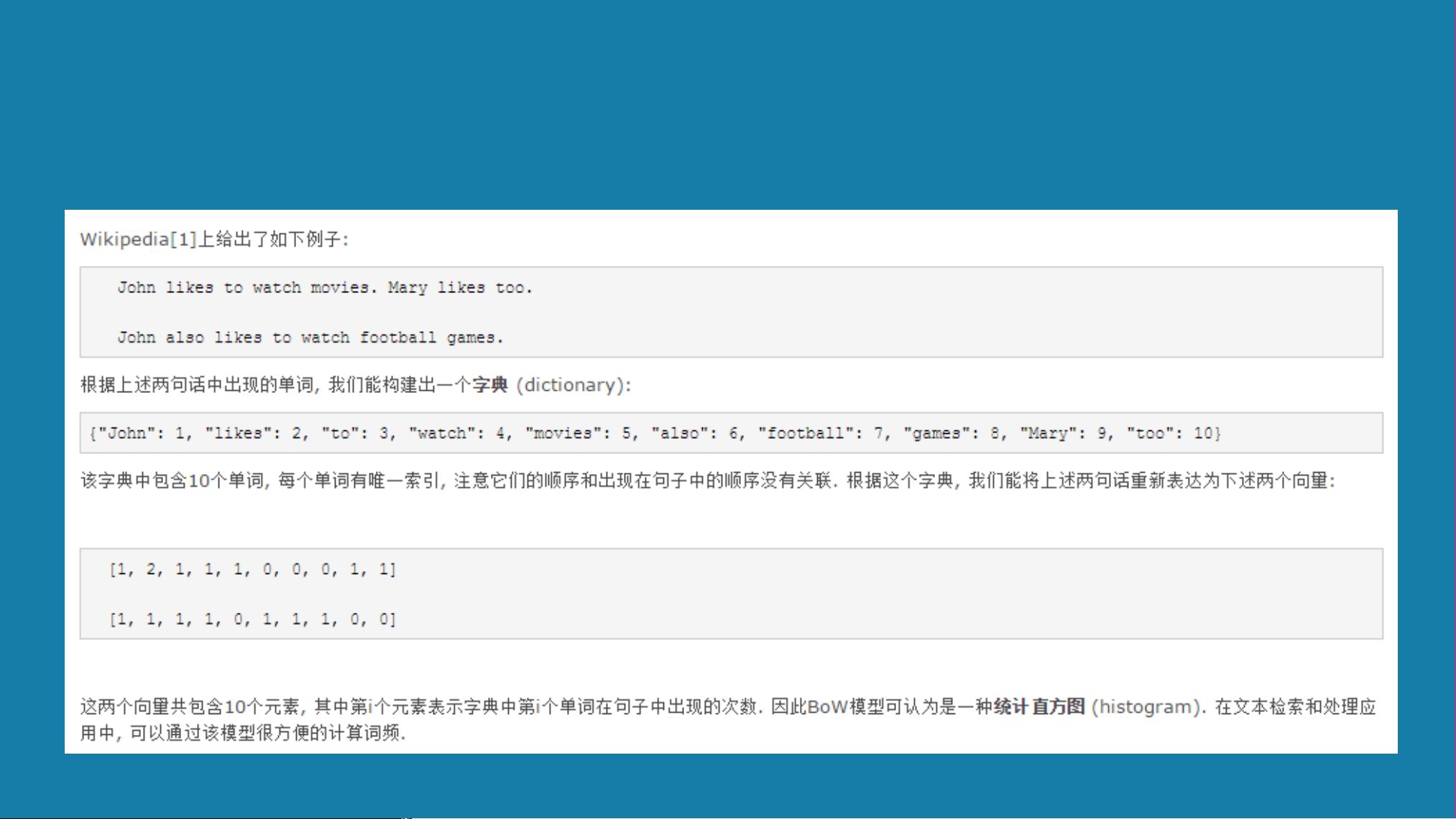
- **向量空间模型(VSM)**:VSM是文本处理的基础框架,将文本内容看作向量空间中的向量,文档由其包含词汇的权重向量表示。权重通常使用TF-IDF(Term Frequency-Inverse Document Frequency),TF考虑词在文档中出现的频率,IDF则是衡量词的普遍性,两者结合降低了常用词的影响,突出关键词。
- **TF-IDF与TF-IDF值排序**:TF-IDF是衡量词重要性的指标,它在文档中词频乘以逆文档频率。计算完每个词的TF-IDF后,可以根据值的大小来识别文档的关键信息。
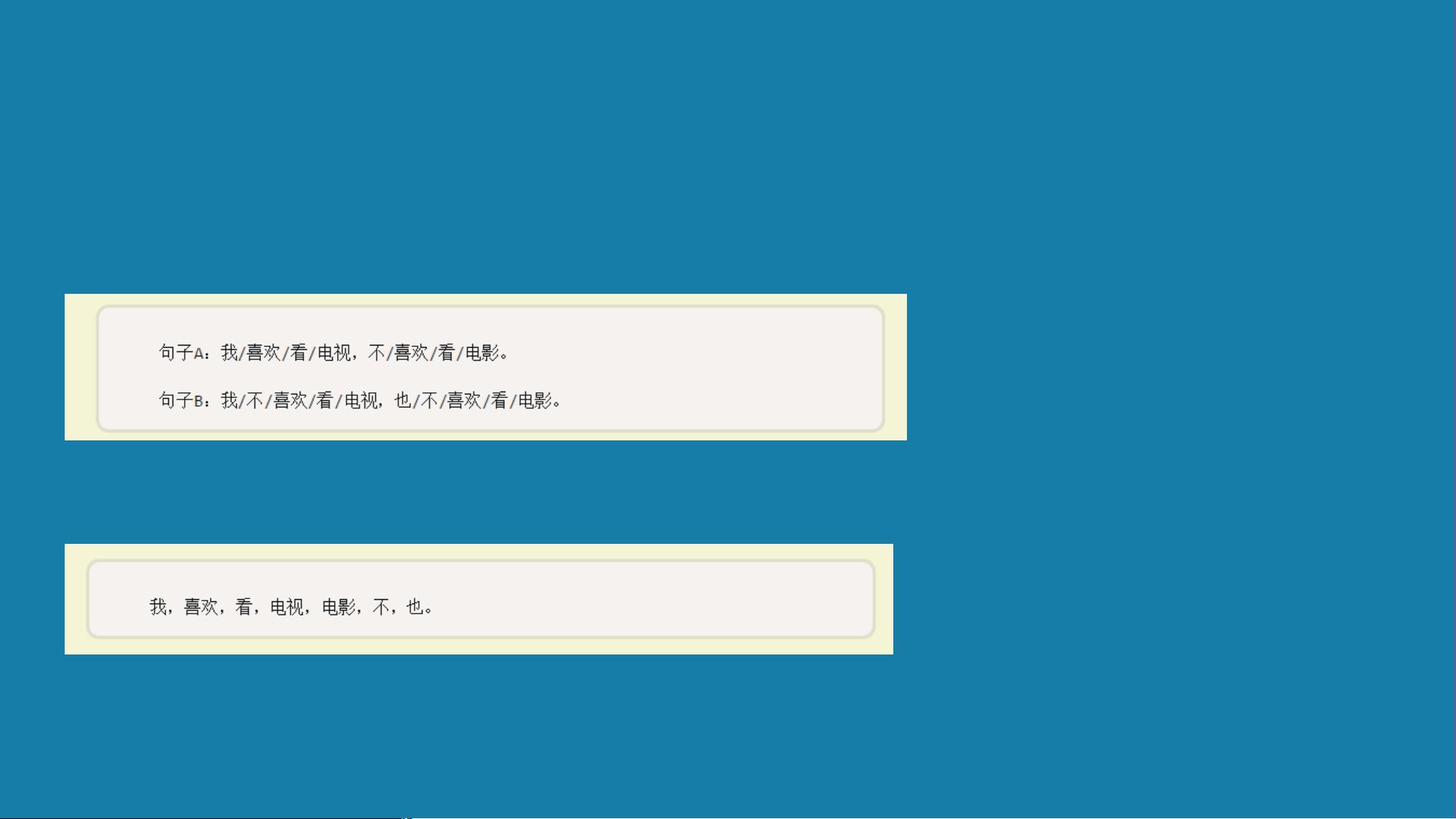
- **Bow模型**:基于词袋模型的简化版本,包括分词、词频计算、向量表示和余弦相似度计算步骤。例如,通过计算《中国的蜜蜂养殖》这篇文章中“中国”、“蜜蜂”、“养殖”的TF-IDF值,可以确定这些词在文档中的重要性。
2. **文本情感分析**:这部分未在提供的部分内容中详述,但情感分析是文本挖掘中的一个重要应用,通过分析文本的情感倾向,如正面、负面或中立,来理解用户情绪或主题倾向。
3. **协同过滤**:协同过滤是一种推荐系统技术,常用于个性化推荐,但它在文本挖掘中的具体应用并未在文中提及,可能涉及基于用户或物品的相似性进行内容推荐。
4. **词云**:词云是一种可视化工具,通过展示文本中出现频率最高的词语,以图形化方式呈现文本的主题分布。它有助于快速理解和感知文本的关键词汇。
Python文本挖掘涵盖了文本处理、相似度计算、关键词提取和可视化等多个关键技术,通过这些方法,可以从大量文本数据中抽取有价值的信息并进行深入分析。

2021-02-17 上传
2024-03-15 上传
2023-08-21 上传
2023-06-16 上传
2021-03-11 上传
2023-10-07 上传

juzhong0521
- 粉丝: 3
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- 平尾装配工作平台运输支撑系统设计与应用
- MAX-MIN Ant System:用MATLAB解决旅行商问题
- Flutter状态管理新秀:sealed_flutter_bloc包整合seal_unions
- Pong²开源游戏:双人对战图形化的经典竞技体验
- jQuery spriteAnimator插件:创建精灵动画的利器
- 广播媒体对象传输方法与设备的技术分析
- MATLAB HDF5数据提取工具:深层结构化数据处理
- 适用于arm64的Valgrind交叉编译包发布
- 基于canvas和Java后端的小程序“飞翔的小鸟”完整示例
- 全面升级STM32F7 Discovery LCD BSP驱动程序
- React Router v4 入门教程与示例代码解析
- 下载OpenCV各版本安装包,全面覆盖2.4至4.5
- 手写笔画分割技术的新突破:智能分割方法与装置
- 基于Koplowitz & Bruckstein算法的MATLAB周长估计方法
- Modbus4j-3.0.3版本免费下载指南
- PoqetPresenter:Sharp Zaurus上的开源OpenOffice演示查看器
