构建常识知识图谱:ASER方法与宋阳秋教授分享
需积分: 0 24 浏览量
更新于2024-06-30
收藏 4.88MB PDF 举报
在知识图谱前沿论坛系列中,宋阳秋老师于2020年7月的讲座探讨了构建常识知识图谱的新方法——ASER(Building a Commonsense Knowledge Graph by Higher-order Selectional Preference)。宋教授的演讲围绕以下几个关键点展开:
1. **动机与背景**:讲座的起点在于强调自然语言处理(NLP)中的常识知识的重要性。在日常的自然语言对话中,无论是人机交互还是理解人类行为,都需要大量的常识知识作为支撑。这些常识包括空间、时间、地点、状态、因果关系、颜色、形状、物理互动等多个方面,这些都是理解和生成自然语言的基础。
2. **考虑因素:选择性偏好** - 宋阳秋教授特别关注了选择性偏好(Selectional Preferences),这是指一个词或短语倾向于与哪些其他词汇搭配使用来表达特定概念或情境。传统的选择性偏好往往局限于一阶关联,但讲座提出了构建大型和高阶选择性偏好知识图谱的新理念,旨在捕捉更深层次的语言使用习惯和常识联系。
3. **应用实例:Winograd Schema Challenge** - ASER的应用体现在Winograd Schema Challenge(WS Challenge)上,这是一个评估模型对语言理解能力的挑战,特别是对于依赖常识推理的问题。通过利用高阶选择性偏好,该方法可能提高了模型在解决这类问题时的准确性和上下文理解能力。
4. **常识知识的关键性** - 讲座强调,常识知识是理解和生成自然语言、进行有效沟通和智能交互的核心。定义和捕捉常识知识的准确性和深度对于构建真正能够与人类进行无缝交流的AI系统至关重要。
5. **贡献者与协作** - 教授感谢了他的博士/硕士研究生、本科生以及来自其他领域的合作伙伴,如Cane Wing-Ki Leung、Daniel Khashabi、Dan Roth、Wilfred Ng和Lifeng Shang,他们的合作推动了这一研究项目的进展。
宋阳秋老师的讲座深入探讨了如何通过高阶选择性偏好来构建知识图谱,以增强人工智能在处理自然语言任务时的常识理解能力,并展示了这一方法在实际挑战(如Winograd Schema Challenge)中的应用前景。这一研究有助于提升AI系统的语言理解水平,使之更接近人类的自然交互方式。

However,
• Semantic meaning in our language can be described as ‘a finite set of
mental primitives and a finite set of principles of mental combination
(Jackendoff, 1990)’.
• The primitive units of semantic meanings include
• Thing (or Object, Entity, Concept, Instance, etc.),
• Property,
• Place,
• Path,
• Amount,
• Activity,
• State,
• Event,
• etc.
Ray Jackendoff. (Ed.). (1990). Semantic Structures. Cambridge, Massachusetts: MIT Press.
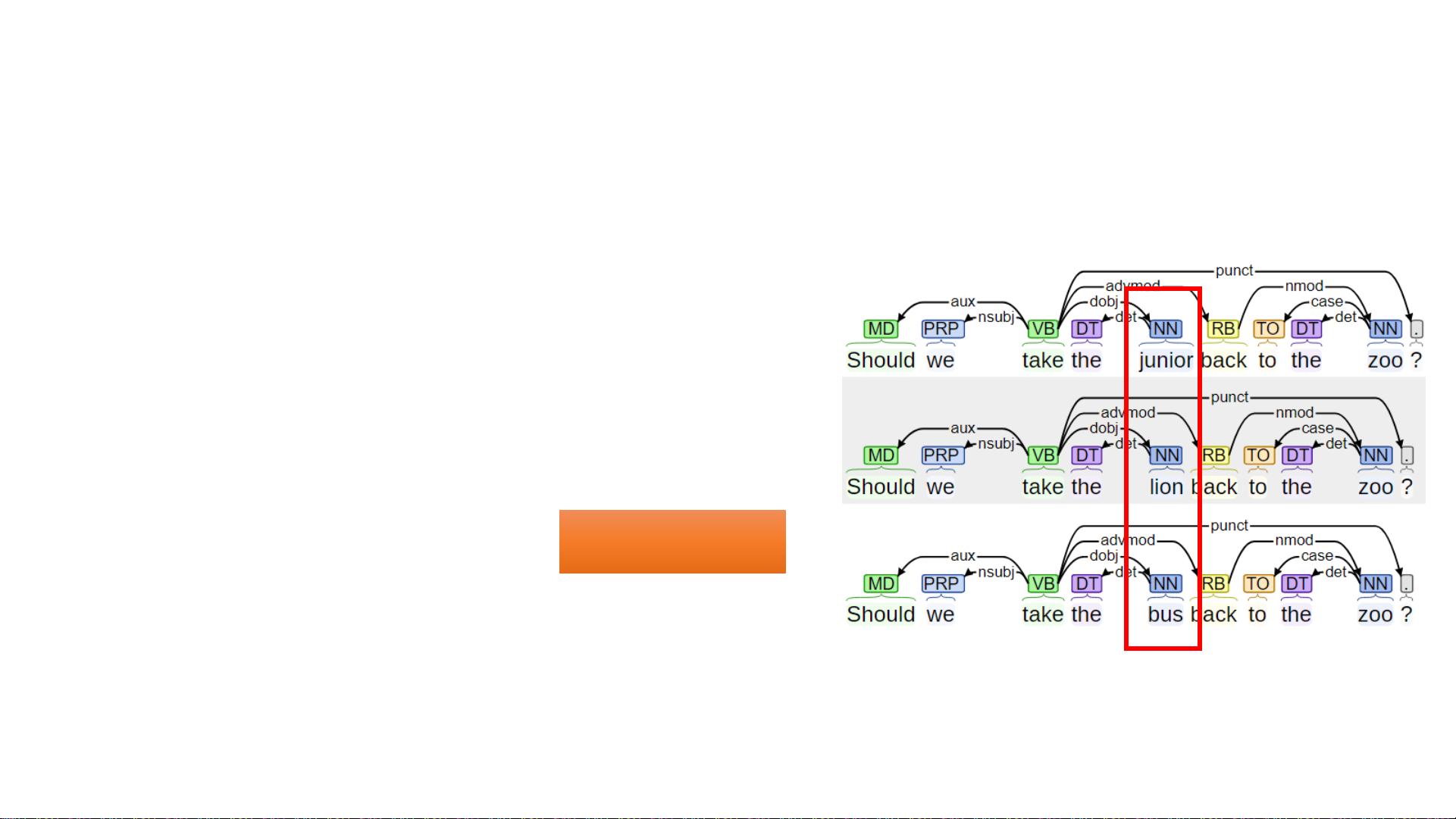
How to collect
more knowledge
about eventualities
rather than entities
and relations?
10
Eventuality

剩余56页未读,继续阅读
504 浏览量
2022-03-18 上传
2022-05-05 上传
2022-10-31 上传
2021-06-18 上传
2018-05-30 上传
2019-09-23 上传
2020-03-14 上传

艾法
- 粉丝: 28
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
