"大数据技术实践:Hadoop、Hive、Spark实验报告"
版权申诉
141 浏览量
更新于2024-04-19
收藏 4.85MB PDF 举报
本次大数据技术实践实验报告的目的在于熟练掌握大数据计算平台相关系统的安装部署,理解大数据MapReduce计算模型并掌握MapReduce程序开发,掌握Hive的查询方法,以及掌握Spark的基本操作。实验内容包括Hadoop完全分布模式的安装、Hadoop开发插件的安装、MapReduce代码的实现、Hive的安装部署、Hive的查询、Spark Standalone模式的安装以及Spark Shell操作。
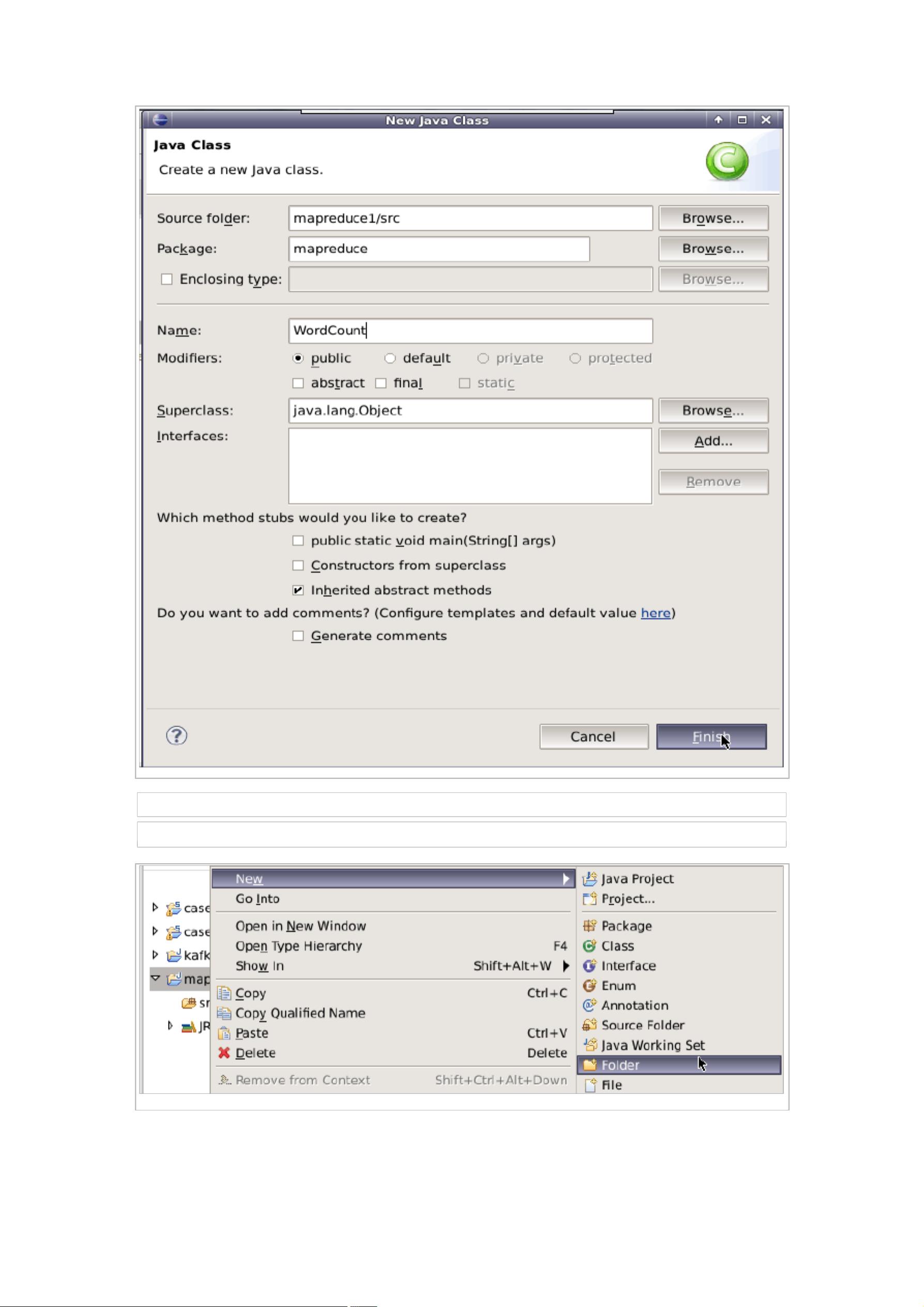
在实验过程中,首先进行了Hadoop开发插件的安装。具体步骤包括在Linux本地创建用于存放文件的目录,并通过wget命令下载所需的插件。接着,进行了Eclipse开发工具以及Hadoop默认安装的设置。随后,进行了Hadoop开发插件的安装,确保系统可以顺利进行MapReduce程序的开发。
其次,进行了Hadoop完全分布模式的安装。通过指导教师的指导,按照实验指导书上的步骤一步步进行,确保Hadoop平台能够正常运行。这包括对Hadoop配置文件的修改、集群节点的设置以及启动Hadoop服务等环节。
接下来,进行了MapReduce代码的实现。通过编写简单的MapReduce程序,加深了对MapReduce计算模型的理解,并熟练掌握了MapReduce程序的开发过程。这一步骤对于后续数据处理和计算具有非常重要的意义。
在完成了MapReduce的实现后,进行了Hive的安装部署以及Hive查询的实验。通过安装Hive并编写查询语句,加深了对Hive查询方法的理解,并熟练掌握了Hive的使用。
最后,进行了Spark Standalone模式的安装以及Spark Shell操作的实验。通过安装Spark并进行简单的操作,深入理解了Spark的基本操作原理,并为以后更深入的学习和应用奠定了基础。
通过本次实验,我不仅熟练掌握了大数据计算平台相关系统的安装部署,也理解并掌握了MapReduce计算模型、Hive查询方法以及Spark的基本操作。这对于我以后在大数据领域的学习和工作将会有很大的帮助。感谢指导教师在实验过程中的耐心指导和帮助,使我能够顺利完成实验并取得成果。希望通过今后不断的学习和实践,能够进一步提升自己的技术水平,为将来的发展打下坚实的基础。


2022-06-21 上传
2022-02-28 上传
2021-07-05 上传
2021-07-17 上传
2021-03-19 上传
2022-10-31 上传

不吃鸳鸯锅
- 粉丝: 8489
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
