编译原理第二版:词法分析实战与DFA构造详解
需积分: 3 99 浏览量
更新于2024-07-31
收藏 493KB PDF 举报
在《编译原理》第二版的第四章中,主要讨论了词法分析的理论与实践,特别是如何通过构造Deterministic Finite Automata (DFA)来实现对输入字符串的识别和解析。本章节的课后习题针对四个具体的正则表达式设计了对应的DFA构建任务。
首先,题目要求构造正规式1(0|1)*101的DFA。构造NFA后,需要通过子集消合并确定化过程,消除不必要的状态和转换,最终得到确定的DFA状态图。在这个过程中,会涉及到状态的重命名和识别终态的状态。
第二个正规式是1(1010*|1(010)*1)*0,同样需要先构建NFA,然后通过类似的方法将其转化为DFA。这个过程可能会涉及到状态的合并和调整,以确保所有可能的输入路径能够正确处理。
第三个正规式a((a|b)*|ab*a)*b涉及字符'a'和'b'的组合,构建的DFA需要能够处理括号内的选择和重复,同时确保最终匹配到'b'。NFA的构造和确定化会更复杂,需要考虑字符间的优先级和组合规则。
最后一个正则式b((ab)*|bb)*ab,其特点是包含嵌套的循环结构和特定的终止条件。构造DFA时,需要确保能够正确处理循环和终止符'b'的匹配。
整个过程不仅要求掌握正则表达式的语法和DFA的基本原理,还涉及到了实际操作技巧,如子集消并和状态命名规则。这些习题有助于读者深入理解词法分析的算法实现,并能提升对编译器设计中的词法分析模块的理解和应用能力。通过解答这些题目,学生可以巩固和提高对编译原理的理解,为后续章节的学习打下坚实基础。
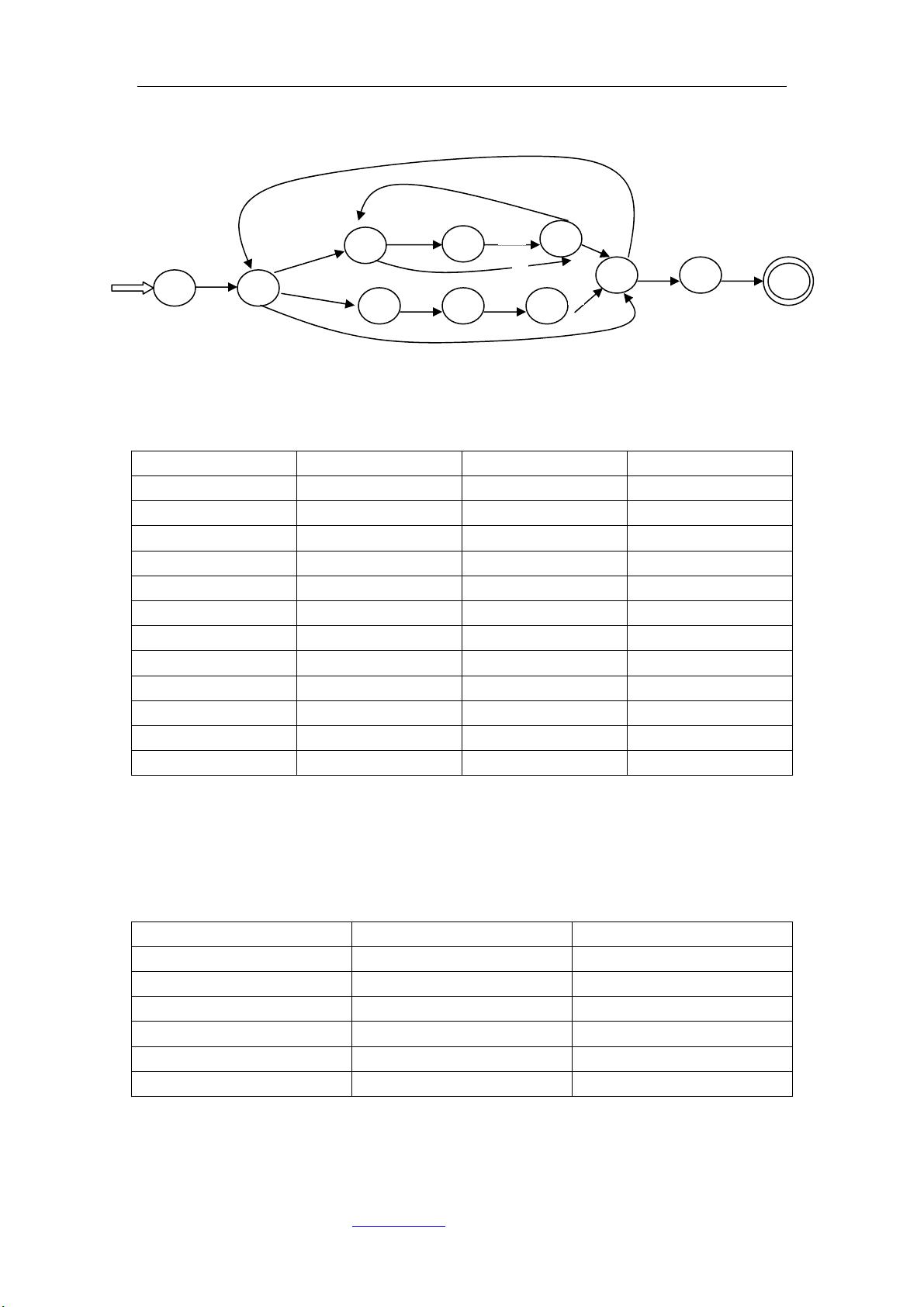
《编译原理》课后习题答案第四章
(4) 先构造 NFA:
X
A
b
B
ε
a
F
b
G
b
H
E
ε
Y
a
ε
C
D
b ε
I
b
ε
ε
ε
ε
用子集法将 NFA 确定化:
ε a b
X X
T
0
=X A
A ABDEF
T
1
=ABDEF CI G
CI CI
G G
T
2
=CI DY
DY ABDEFY
T
3
=G H
H ABEFH
T
4
=ABDEFY CI G
T
5
=ABEFH CI G
将T
0
、T
1
、T
2
、T
3
、T
4
、T
5
重新命名,分别用 0、1、2、3、4、5 表示。因为 4 中含有Y,
所以它为终态。
a b
0 1
1 2 3
2 4
3 5
4 2 3
5 2 3
DFA 的状态图:
盛威网(www.snwei.com)专业的计算机学习网站
5
剩余22页未读,继续阅读
1522 浏览量
2014-04-07 上传
2022-03-15 上传
927 浏览量
660 浏览量
176 浏览量
403 浏览量
2011-12-15 上传

luoyezhiqiu630
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- Verilog实现的Xilinx序列检测器设计教程
- 九度智能SEO优化软件新版发布,提升搜索引擎排名
- EssentialPIM Pro v11.0 便携修改版:全面个人信息管理与同步
- C#源代码的恶作剧外表答题器程序教程
- Weblogic集群配置与优化及常见问题解决方案
- Harvard Dataverse数据的Python Flask API教程
- DNS域名批量解析工具v1.31:功能提升与日志更新
- JavaScript前台表单验证技巧与实例解析
- FLAC二次开发实用论文资料汇总
- JavaScript项目开发实践:Front-Projeto-Final-PS-2019.2解析
- 76云保姆:迅雷云点播免费自动升级体验
- Android SQLite数据库增删改查操作详解
- HTML/CSS/JS基础模板:经典篮球学习项目
- 粒子群算法优化GARVER-6直流配网规划
- Windows版jemalloc内存分配器发布
- 实用强大QQ机器人,你值得拥有
