立体视觉入门:双目成像与深度计算
需积分: 10 14 浏览量
更新于2024-07-20
2
收藏 1.84MB PPT 举报
立体匹配(Stereo Vision)是计算机视觉领域的一个重要分支,它通过比较两个从不同视角拍摄的图像来估计场景中的深度信息。这个概念起源于对人类视觉系统的理解,人类能够通过双眼观察到的微小视差(disparity)来感知三维空间。在计算机上,这一过程涉及两个关键步骤:获取图像数据和计算深度。
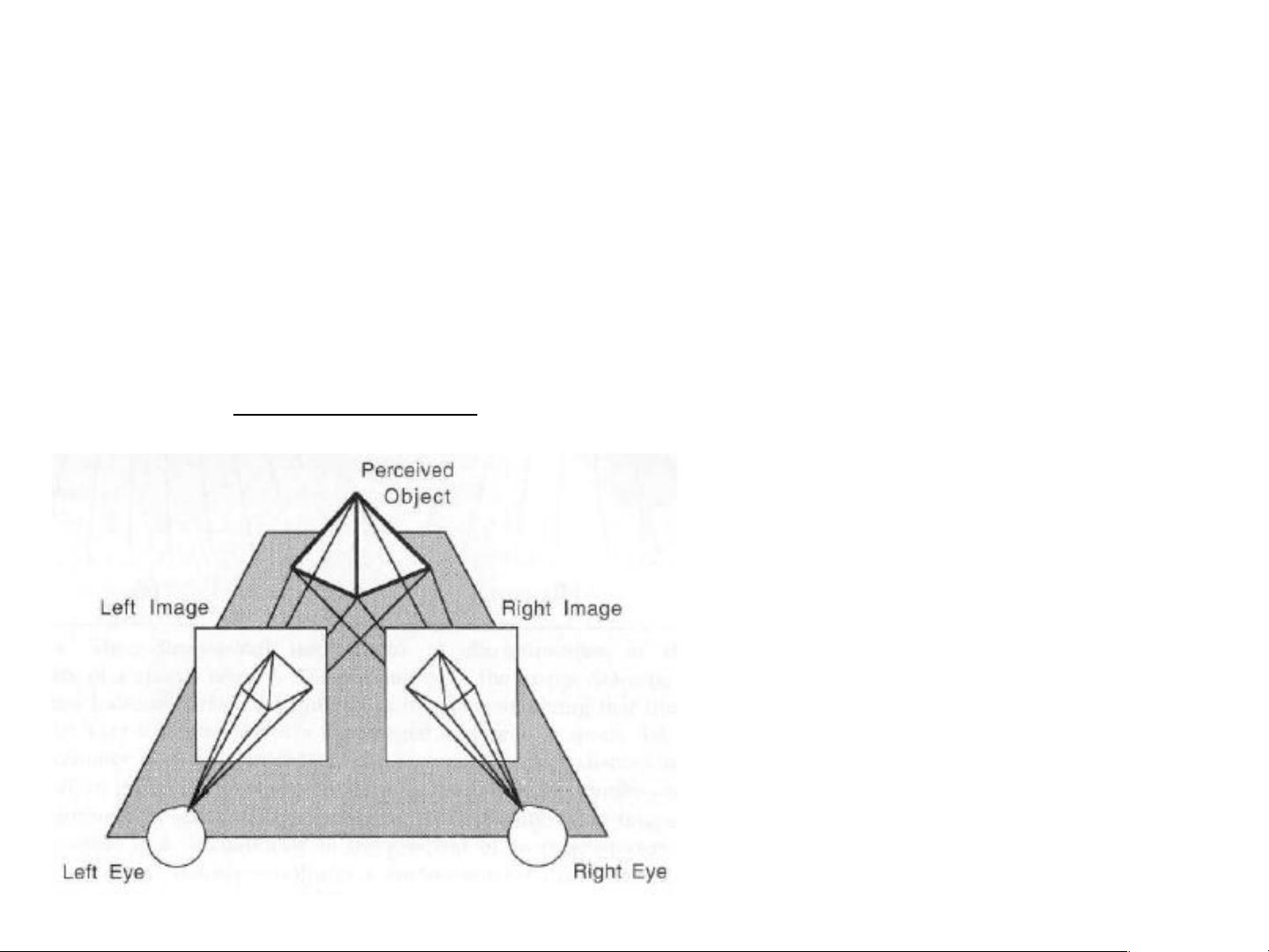
首先,立体视觉系统通常由一对左右相机组成,它们的光学中心分别标记为OL(左眼)和OR(右眼)。每个相机将捕捉到实际场景中物体的投影,形成各自的像平面。这两个像平面之间的距离,即基线(baseline),b,是决定视差分辨率的关键因素。当一个场景中的点P在左相机中被成像为pL,而在右相机中被成像为pR时,它们之间的像素差异d就是视差,等于pR与pL的差值。
例如,假设点P在两幅图中的位置分别为pL=9像素和pR=3像素,那么d = pR - pL = 6像素。从这个视差值,我们可以通过公式z = b / pd来计算出该点的深度(z),其中pd代表像素宽度。
立体视觉的应用广泛而多样。在航空测绘(Aerial Mapping)中,它可以用于创建高精度地图和三维模型;在犯罪现场调查(Forensics)和交通事故分析中,有助于重建事件发生时的现场细节;在矿业(Mining)中,用于测量矿井内部结构;在建筑和城市规划(Civil Engineering)等领域,它可以帮助测量建筑物的距离和尺寸,提高精确度。
尽管技术基础相对简单,但立体匹配涉及复杂的算法和技术,包括但不限于:特征匹配、稠密对应、深度估计、误差校正等。随着深度学习的发展,现代方法如卷积神经网络(CNN)和深度学习框架(如OpenCV、CUDA-Compute Unified Device Architecture)使得立体视觉处理更为高效,应用范围也进一步扩大。因此,对于初学者来说,理解和掌握立体匹配原理是进入高级计算机视觉研究的重要一步。
7
Stereo Vision
•
Goal
−
Recovery of 3D scene structure
−
using two or more images,
−
each acquired from a different viewpoint in space
−
Using multiple cameras or one moving camera
−
Term binocular vision is used when two cameras are employed
Stereophotogrammetry
Using stereo vision systems
to measure properties
(dimensions here) of a scene

剩余37页未读,继续阅读
2015-12-04 上传
2015-12-04 上传
384 浏览量
2022-07-15 上传
2022-07-15 上传
2022-07-14 上传
2021-02-02 上传

红泥_凛冬将至
- 粉丝: 13
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- IEEE 14总线系统Simulink模型开发指南与案例研究
- STLinkV2.J16.S4固件更新与应用指南
- Java并发处理的实用示例分析
- Linux下简化部署与日志查看的Shell脚本工具
- Maven增量编译技术详解及应用示例
- MyEclipse 2021.5.24a最新版本发布
- Indore探索前端代码库使用指南与开发环境搭建
- 电子技术基础数字部分PPT课件第六版康华光
- MySQL 8.0.25版本可视化安装包详细介绍
- 易语言实现主流搜索引擎快速集成
- 使用asyncio-sse包装器实现服务器事件推送简易指南
- Java高级开发工程师面试要点总结
- R语言项目ClearningData-Proj1的数据处理
- VFP成本费用计算系统源码及论文全面解析
- Qt5与C++打造书籍管理系统教程
- React 应用入门:开发、测试及生产部署教程
