Python数据预处理实战指南:提升模型精度的关键步骤
118 浏览量
更新于2024-07-16
1
收藏 6.44MB PDF 举报
数据预处理笔记是一份深入探讨数据预处理重要性的学习资料,针对机器学习、深度学习等领域的数据准备工作展开。作者强调了数据预处理在实际项目中的关键作用,尤其是在面对复杂任务和不同语言数据时,数据质量的提升往往比优化算法模型更为显著。笔记详细介绍了数据预处理的必要性及其流程:
1. 数据预处理定义:数据预处理是将原始数据经过一系列处理,去除噪声、填充缺失值、标准化格式、特征选择和转换,使其转化为适合模型训练的高质量数据。这有助于提高模型的性能,尤其是在处理“的,是”等停用词时,可以避免这些无用特征对模型造成干扰。
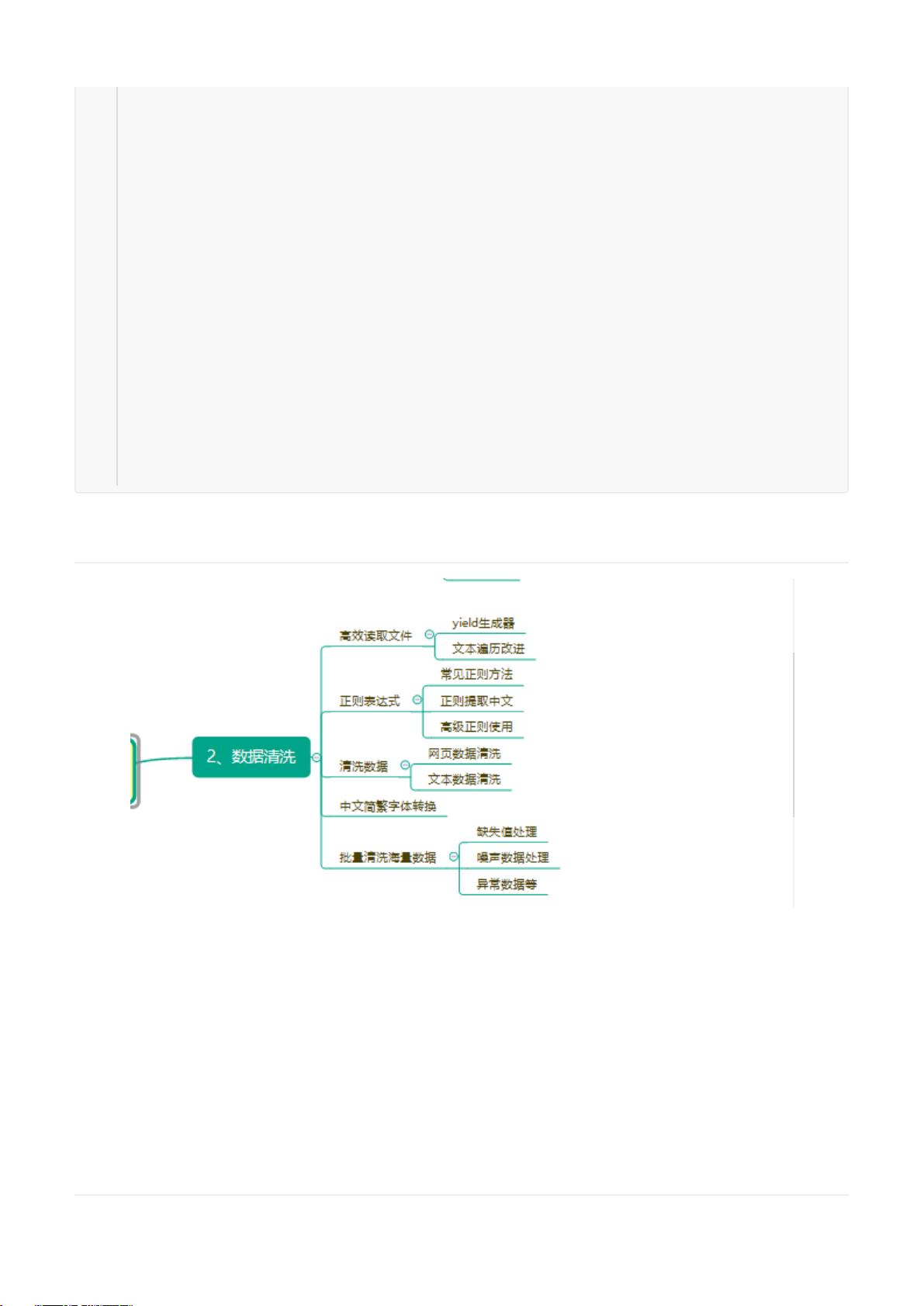
2. 预处理流程:
- 数据集成:整合来自不同数据源的信息,形成统一的数据存储,例如数据仓库。
- 数据清洗:包括填充缺失值、处理噪声、识别和处理异常值,确保数据的准确性和一致性。
- 数据变换:通过平滑、概括或规范化方法调整数据格式,使之适应算法模型的要求,如将数值范围缩放至0.0-1.0之间。
- 数据归约:对于大规模数据,通过降维技术(如PCA)生成更小但信息损失小的表示,以提高计算效率。
3. 学习内容覆盖Python 3.5开发环境下的数据预处理实践,使用PyCharm和Anaconda作为主要工具,支持最新的插件版本。这部分内容将着重介绍如何使用Python进行文本数据的抽取和处理,包括如何提取有用信息,去除噪声,以及如何进行特征工程。
该笔记不仅包含了理论概念,还包含了一些实用的代码示例和源码,适合初学者了解数据预处理的基本步骤,以及进阶开发者在实际项目中优化数据处理流程。对于想要提升数据驱动分析技能的读者来说,这是一份不可多得的参考资料。
"""
1、引用外部文本抽取模块:import ExtractTxt as ET
2、参数方法使用:TraversalFun(rootDir,ET.File2Txt,saveDir)
3、 创建保存根目录:os.path.abspath
4、递归遍历文件:func(path,save_dir)
"""
class TraversalFun():
# 1、初始化,rootDir目标文件路径
def __init__(self,rootDir,func=None,saveDir=""): # saveDir:保存路径,
self.rootDir = rootDir # 目标文件夹路径
self.func = func # 方法参数,实现文本提取
self.saveDir = saveDir # 文件夹保存路径,
# 2、遍历目录文件—调用具体的遍历文件名函数
def TraversalDir(self):
# 分切文件目录和文件名
dirs,filename = os.path.split(self.rootDir)
print('dirs:',dirs) # 根路径
print('filename=',filename) # 文件夹名称
# 保存目录
save_dir = ""
if self.saveDir == "":
save_dir = os.path.abspath(os.path.join(dirs,'new_'+filename)) # 文件夹保存
的路径
else:save_dir = self.saveDir
print('save_dir=',save_dir) # 打印最新的文件夹所在路径
# 创建保存路径-创建目录文件
if not os.path.exists(save_dir):
os.makedirs(save_dir) # 创建文件路径
print("保存目录:",save_dir)
# 遍历文件并将其转化txt文件
TraversalFun.AllFiles(self, self.rootDir,save_dir) # 根路径和保存路径
# 3、递归算法遍历所有文件,并打印文件名(非目录文件)—具体的遍历文件名(递归遍历所有文件,并提供具体
文件操作功能)
def AllFiles(self,rootDir,save_dir=''):
# 返回指定目录包含的文件或文件夹的名字的列表
# 获取根目录下所有文件
for lists in os.listdir(rootDir):
# 待处理文件夹名称集合
path = os.path.join(rootDir,lists) # 路径拼接
# 核心算法:对文件类型信息抽取,并保存
if os.path.isfile(path): # 如果是文件
self.func(os.path.abspath(path),os.path.abspath(save_dir)) # 文件名和保
存路径
print('原始文件绝对路径:', os.path.abspath(path)) # 打印绝对路径
# 递归遍历文件目录
if os.path.isdir(path): # 如果是一个文件夹
newpath = os.path.join(save_dir,lists) # save_dir+列表
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67

剩余120页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-04 上传
2019-05-20 上传
2022-07-10 上传
2023-10-21 上传
2019-08-30 上传
2022-06-17 上传

jjkqjj
- 粉丝: 624
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
