网络数据采集入门:爬虫技术与大数据应用
需积分: 0 44 浏览量
更新于2024-08-05
收藏 566KB PDF 举报
"《网络数据采集》第1章课件201911221"
本课程主要探讨的是网络数据采集,是大数据技术与应用领域的核心课程,旨在培养硕士生在网络数据获取、解析、存储及应用方面的专业技能。课程内容涵盖了网络数据采集的各个方面,包括网络爬虫的基本概念、工作原理、需求分析、发展历程,以及相关的Web技术、页面爬取、解析、身份认证处理、RIA(Rich Internet Application)网站数据爬取、构建稳定和高性能爬虫系统的策略等。
1.1 课程目标
课程的主要目标是使学生能够:
1) 了解网络数据采集的不同方法、技术要求和关键点;
2) 掌握如何进行Web信息爬取、内容解析以及有效存储数据;
3) 理解“网站就是API”的概念,即通过分析和利用网站内容来获取所需数据。
1.2 课程内容
课程详细讲解了数据来源和采集策略,从基础的网络爬虫概念到复杂的网络爬取技术。其中,数据科学的重要性被强调,它结合了统计学、数据分析和机器学习,致力于从大量数据中提取有价值的信息。数据科学的发展和数据驱动的科学范式被讨论,同时指出数据科学已成为21世纪的热门职业。
2.2 数据的来源与采集方法
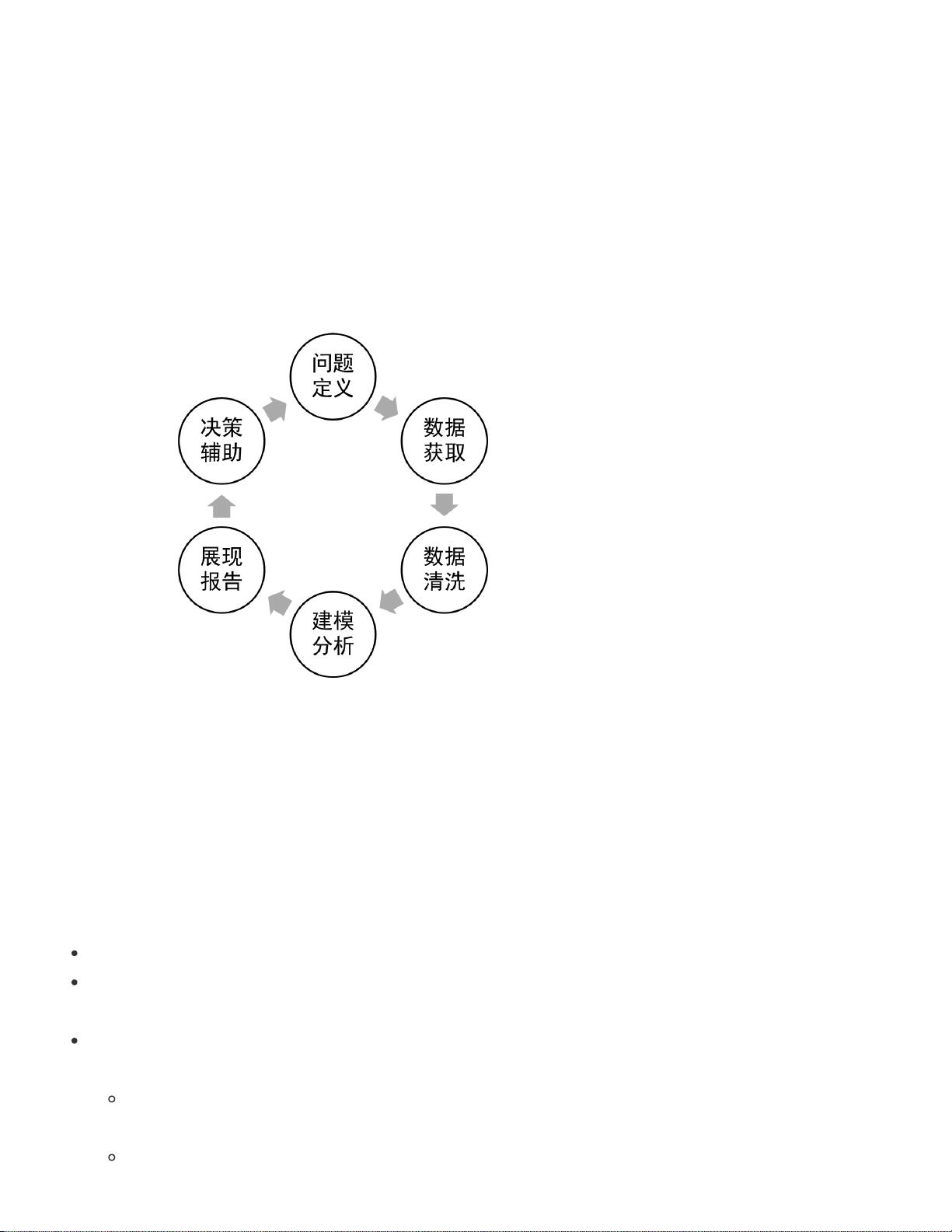
数据科学涉及从各种类型的数据源中获取和分析信息。随着信息技术和数据的增长,数据科学在各个科学领域中的角色日益凸显。数据工程师和数据科学家是大数据时代的代表职位,他们分别负责创建数据解决方案和解释数据背后的意义。数据科学的工作流程包括问题定义、数据获取、预处理、建模分析、结果展示和决策支持,这一过程通常是迭代的。
网络数据采集是大数据分析的基础,它要求学生掌握网络爬虫的运作机制,熟悉Web技术,能够解决身份验证等问题,并具备构建高效、稳定的爬虫系统的能力。通过本课程的学习,学生将能够运用这些知识来应对复杂的数据采集挑战,从而在大数据领域发挥关键作用。
图灵奖得主吉姆•格雷认为数据科学将成为科学的“第四个范式”,即经验、理论、计算和数据驱动,并且
断言“在信息技术和数据泛滥的影响下,有关科学的一切正在发生改变”。2012年,《哈佛商业评论》杂
志将数据科学称为“21世纪最性感的职业“,随后“数据科学”这个词变得流行起来。与此同时,与数据科
学相关的工作岗位也快速增多,薪资水平也逐年攀升。
大数据相关的工作岗位,一般被称为数据工程师或数据科学家,数据工程师的要求是利用数据工具做出
新东西,而科学家主要是利用数据和工具解释数据说明了什么,为什么会这样。
无论是数据工程师或是数据科学家,从事数据科学工作时的基本业务流程大致是相同的。数据科学的业
务流程可被描述成一个迭代模型,如图所示:
数据科学的基本业务流程依次是:问题定义、数据获取、数据清洗、建模分析、展现报告、决策辅助。
之后可能会出现新的问题,或是老问题的重新定义,经过多次迭代,知识会不断更新,对事物本质认识
呈螺旋型上升。从中我们可以发现,数据获取是基础环节。所谓数据获取就是通过各种技术手段和人类
活动,感知能反映事物状态和变化发展的数据,并将它们收集起来,为后续基于数据的分析奠定基础。
从就业市场上的反馈来看,数据科学从业者往往被要求有多项技能,而数据获取能力往往是不可或缺的
一部分。那么如何获取数据呢?
现实中,可供我们使用的数据,主要来自4个方面:
数据的第1种来源,是单位自有的历史数据,包括文档、数据库、表格等格式;
数据的第2种来源,是定量/定性的市场调研,例如:通过网络、街头、电话方式进行问卷调查而得
到的数据。
数据的第3种来源,是专业机构的长期积累:许多互联网公司、咨询机构都非常擅于收集数据。随
着大数据时代的来临,数据的获取与供给成为一门大生意,有从事这类业务的机构:
第1种专业机构是互联网企业:例如:百度指数、阿里指数、TBI腾讯浏览指数、新浪微博指
数;
第2种专业机构是数据交易平台:例如:数据堂、国云数据市场、贵阳大数据交易平台;
剩余12页未读,继续阅读
2022-08-04 上传
2022-08-04 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2022-08-03 上传
2021-11-19 上传
2021-11-23 上传

UEgood雪姐姐
- 粉丝: 42
- 资源: 319
 我的内容管理
展开
我的内容管理
展开







