监控动态资源:Spark与Yarn在大数据处理中的挑战与解决方案
需积分: 5 5 浏览量
更新于2024-06-21
收藏 1.27MB PDF 举报
"藏经阁-Monitoring the Dynamic.pdf"
这篇文档主要关注的是监控Apache Spark在YARN(Yet Another Resource Negotiator)集群中的动态资源使用情况,特别是针对使用Scala和Python编写的Spark作业。文档提到了机器学习(ML)应用程序的工作流程,并强调了将Spark应用投入生产环境时所面临的挑战。
在Yarn集群中运行Spark作业,涉及到数据提取、转换和加载(ETL)以及模型训练和预测等任务。这两种语言——Scala和Python,是Spark开发中最常用的编程语言。Scala是Spark的原生语言,提供强大的类型安全性和面向对象的功能,而Python则因其易读性和丰富的数据科学库而受到欢迎。
然而,将Spark应用带入生产环境并不简单,它需要一个执行框架,该框架必须具备可扩展性、健壮性和经过充分测试的性能。在大规模环境下测试应用至关重要,因为许多问题只有在负载较大时才会显现出来,如性能问题、内存需求、故障和扩展性问题。分布式应用的调试尤其困难,因为问题可能分布在各个节点上。
文档通过Spark UI展示了在作业和任务级别监控性能的重要性,Spark UI是Spark自带的一种可视化工具,可以查看作业执行的详细信息。然而,当遇到如Out-of-Memory (OOM)异常这样的问题时,尽管Spark UI提供了作业和任务级别的信息,但可能不足以定位问题的根本原因。
案例研究部分提到了一个Py4J问题,Py4J是一个Python到Java的网关,常用于在Spark中调用Python代码。测试工程师报告说,代码在处理特定量的数据时出现OOM异常,但Spark UI并未提供足够的线索来识别问题。这表明,对于Python Spark作业,可能需要更深入的监控工具和方法来诊断这类问题。
为了应对这些挑战,文档提出了对YARN集群工具的要求,包括全集群范围内的进程监控、每个节点和每个进程的统计信息、高CPU和内存使用率的识别,以及记录Spark作业的进程层次结构和时间线。这样的工具能够帮助开发者更好地理解资源消耗,及时发现并解决性能瓶颈,从而确保Spark应用在生产环境中的稳定运行。
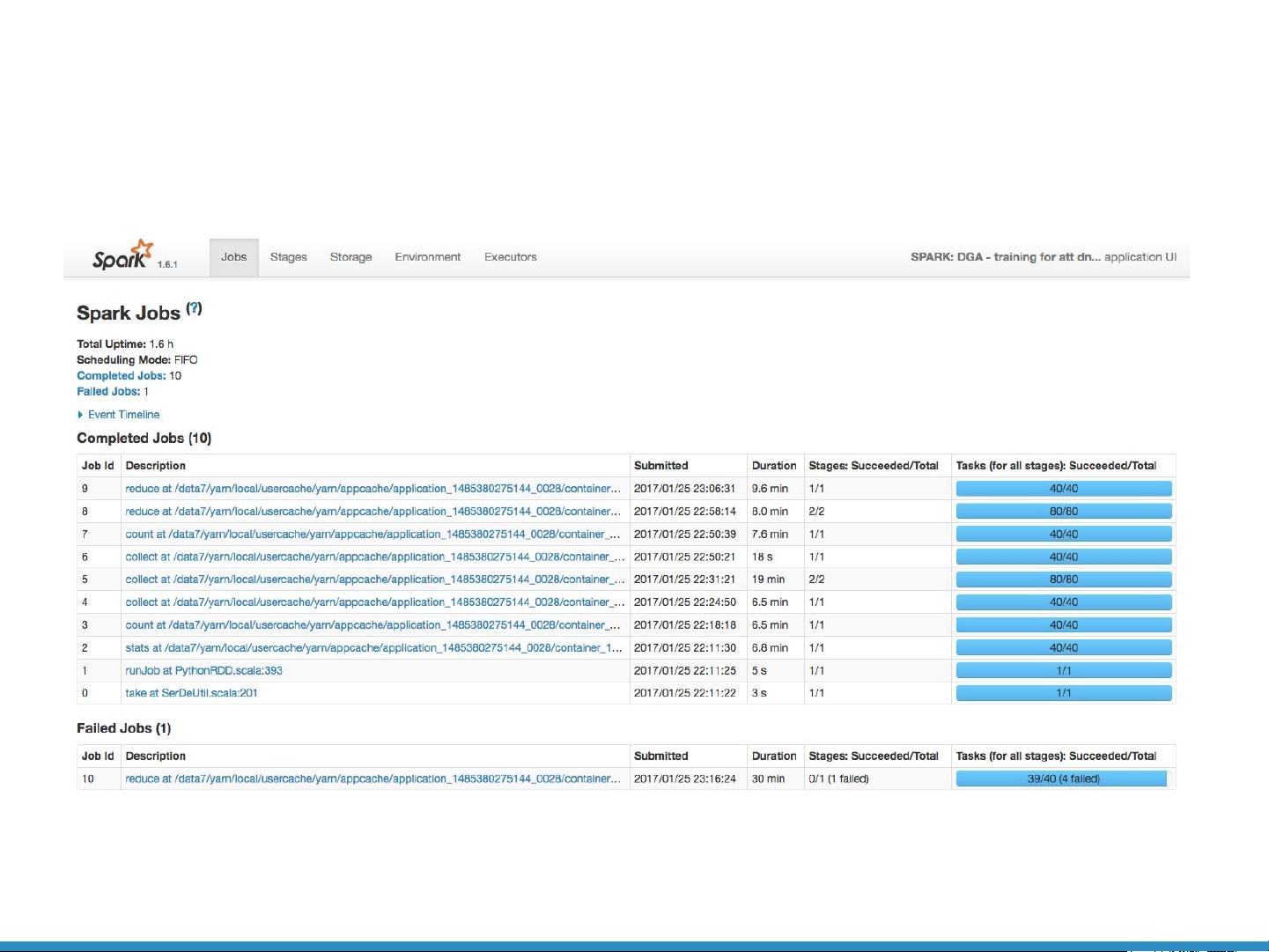
Spark UI: job level
剩余24页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-26 上传
2023-09-09 上传
2023-08-27 上传
2023-09-04 上传
2023-08-26 上传
2023-08-26 上传

weixin_40191861_zj
- 粉丝: 86
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- OnlineBookstore:这是一个简单的在线书店项目
- 记录自己的Python ML and DPL学习经历.zip
- react_base:Projeto基本em react
- resume:我的履历库
- ACP:我在萨尔大学的一个名为“高级Coq编程”课程的项目。 我的工作仅限于Reflection.v和GeneralReflection.v文件,对PA.v和ZF.v进行了一些细微修改
- laravel-mbt_transfer
- publicfile:容器 >
- kazoo-braintree:Braintree簿记员
- 记录python学习用.zip
- plc与气压控制讲了气阀,气路原理以及用PLC的控制(基础,WORD文档).zip三菱PLC编程案例源码资料编程控制器应用通讯通
- 外部窗口菜单内码转换-易语言
- flexbox-course
- CAD Scripts-开源
- JSP 学生排课选课系统-毕业设计(源码+论文).rar
- SistAlCec-Eof
- idcard-iranian:诊断您的身份证是真还是假(对于伊朗人)===诊断身份证号码的正确性
